Why bigger context windows don’t automatically produce better reasoning — backed by 1,296 audited coding runs and recent long-context research.
Quick read. This started as a problem, not a paper. I was deploying enterprise workloads against large-context APIs — calling frontier models directly, without an agentic harness in the loop — and the responses kept coming back worse than they should have. Not catastrophic, just consistently below where the model behaved when the same task was run inside Claude Code or Cursor. My hypothesis was that the long context window itself was doing damage when nothing was managing it. I went looking in the literature and found a small set of papers (LOCA-bench, Chroma’s Context Rot, Lost in the Middle, RULER) describing exactly this effect — but on benchmarks, not on the kind of production coding workload I cared about. So my team and I ran our own. 1,296 audited coding runs against four flagship models across four experiment families, on a real production codebase. The result is not “long context is useless” — it’s sharper: unmanaged context fails. Up to 200K tokens (the limit of our row-backed data), frontier models didn’t show a clean universal accuracy collapse, but hallucination pressure climbed with context size. Retrieval quality dominated raw context volume. Inline related distractors were far more damaging than file-level padding. And targeted full-file context beat both full-codebase loading and compressed summaries on accuracy, hallucination, and cost. Every run is a direct API call — no agentic harness, tool loop, or context-management system in scope; this is raw model behavior, a baseline that a well-engineered harness like Claude Code or Cursor is designed to improve on, not a ceiling on what such a harness can achieve. Detailed findings, methodology, and per-model breakdowns follow below.
The Promise That Broke
Your model can see your entire codebase. So why does it keep suggesting functions that don’t exist?
You load a critical service into your AI coding agent — fifteen files across three microservices. You enable the million-token context window. Every module, config, and test is in scope. The model has everything it needs. And still fails.
Twelve seconds later, it suggests calling validateUserSession() — a function that has never existed in your codebase. It hallucinated it. Confidently. While the real implementation sat in plain sight.
You try again. Now it ignores the rate limiter and proposes a fix that would hammer an upstream service. Authentication? Missed entirely.
Composite scenario, not a single measured run — representative of the failure patterns that show up in EXP1’s hallucination data (Finding 1, task T08) and EXP3’s inline-distractor results (Finding 3, task T07).
The model isn’t stupid. Frontier coding models score in the high range on public coding benchmarks. The problem is upstream: it can’t use the information it already has. And a single session like this can quietly burn several dollars and leave the codebase less safe than it was before.
This is the pattern playing out across the industry right now. Teams enable the biggest context window available, load everything in, and often get less reliable results than a tighter, targeted context pack would have given them. It’s not that a 1M window is broken; it’s that a 1M window is not self-managing. The window doesn’t decide what’s relevant, doesn’t suppress distractors, and doesn’t protect code identifiers from being compressed away. Unmanaged capacity is the failure mode, and the research published in early 2026 finally puts numbers on it.
Advertised Context Wasn’t Effective Context
Earlier this year, a team at HKUST released something the field needed badly: LOCA-bench — a benchmark that tests how agents degrade as context grows during real tasks, not the synthetic retrieval tests everyone aces.[1] It’s not without issues — the task set skews toward structured data manipulation, and the “environment context” they measure includes a lot of scaffolding that most production setups wouldn’t carry. But it’s the closest thing we have to measuring real agentic degradation, and the relative ordering of models is probably right even if the absolute numbers are pessimistic. (Why relative ordering survives absolute pessimism: their task design isolates context length as the only variable, and the failure modes at play — RoPE position bias, attention dilution, softmax sharpening — are architectural and shared across every transformer in the lineup. Tasks change the numbers; they don’t change which model handles 128K better than another.) They tested seven frontier models, including GPT-5.2-Medium (400K window), Claude-4.5-Opus (200K window), and Gemini-3-Flash (1,050K window), on tasks like managing spreadsheets, processing emails, and navigating databases — the kind of work we’re actually asking these models to do.
At 128K tokens — comfortably within every model’s advertised capacity — accuracy was bad across the board:

Source: LOCA-bench, Zeng et al. (2026)[1]
What jumps out isn’t just the absolute numbers — it’s that they don’t track window size. Gemini-3-Flash advertises 1,050K tokens — over five times Claude’s window — but at 128K it lagged both Claude-4.5-Opus and GPT-5.2-Medium. GPT-5.2-Medium, with the smallest frontier window in the test (400K), came out on top. DeepSeek-V3.2-Thinking, the open-source entry, dropped to 10.7% — well below the frontier group, despite a 130K window that nominally covers the test. Advertised capacity didn’t predict effective accuracy.[1]
It compounds. As the environment description grew from 8K to 256K tokens, every model’s accuracy dropped further — a smooth, measurable decline the researchers call “context rot.”[1] Agents generated trajectories of 76K to 617K tokens just to complete tasks, hoovering up file contents, tool outputs, and error traces along the way. The context didn’t stay clean. It never does.

The AI industry is in the middle of a context window arms race. Every few months, another company announces a bigger number: 128K, 1M, 2M, 10M tokens. The pitch is simple: more context, more knowledge, better answers. It makes sense on a whiteboard. It often falls apart in production — not because the windows don’t hold the tokens, but because what gets crammed into them stops being useful long before the limit. The number of teams I’ve talked to who burned a quarter trying to make “just load everything” work before learning this the hard way — it’s not small.
But here’s the twist: the LOCA-bench researchers also showed that the right context-engineering strategies — especially programmatic tool calling — substantially improved accuracy across the tested models, though simpler strategies sometimes helped and sometimes hurt. GPT-5.2-Medium’s accuracy improved by roughly 10 percentage points with the right techniques; Gemini-3-Flash saw similar relative gains from its 21.3% baseline.[1] The models weren’t broken — they were drowning in their own context. Clean it up, and they performed.
The race to bigger context windows is solving the wrong problem. What matters isn’t how much your model can see — it’s what you put in front of it, what you keep out, and whether what you leave in stays in a form the model can still reason over.
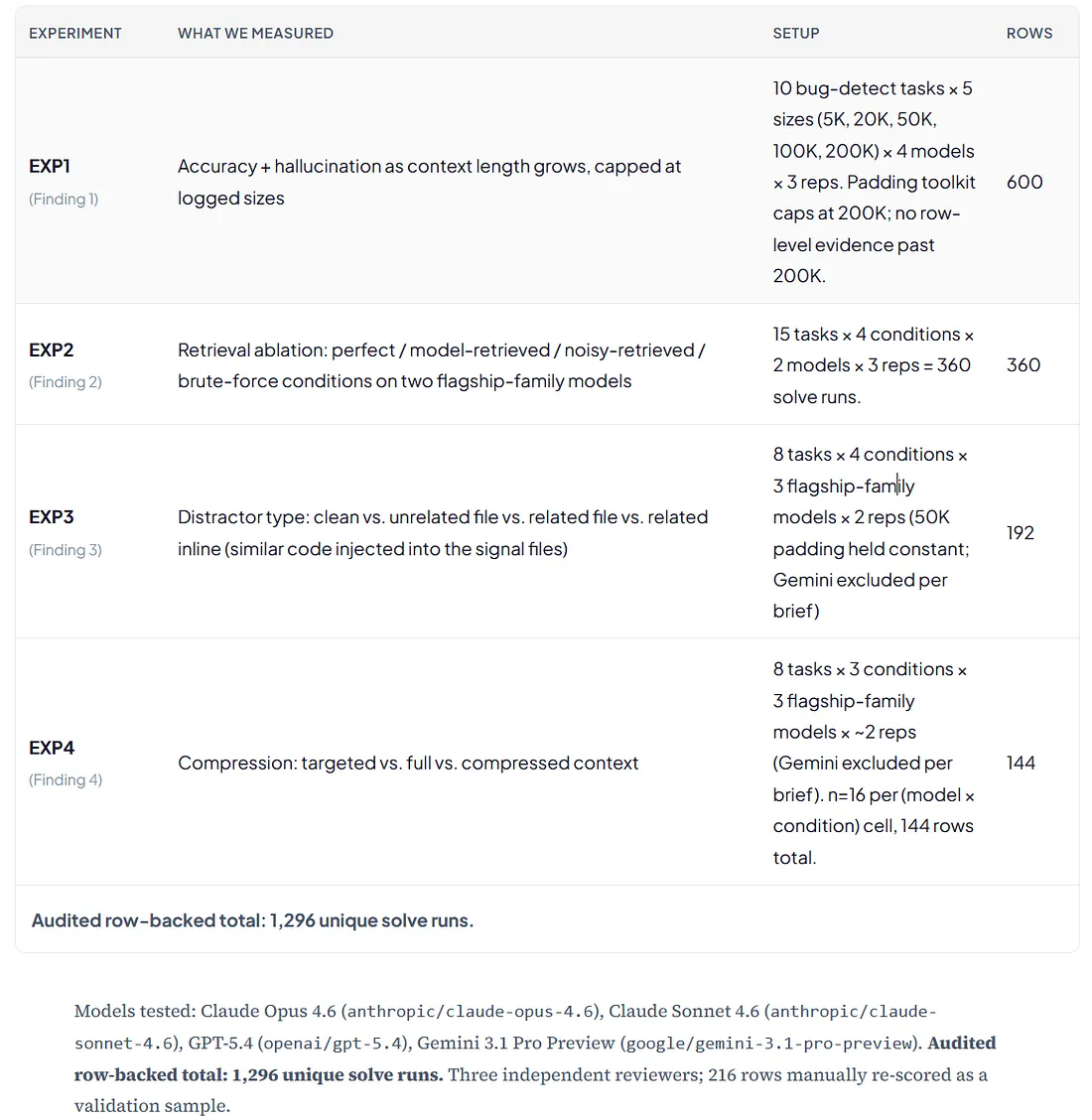
But published studies are always one step removed from your own workload. So we ran our own. What follows is based on 1,296 row-backed solve runs against four flagship-tier models — Claude Opus 4.6 (anthropic/claude-opus-4.6), Claude Sonnet 4.6 (anthropic/claude-sonnet-4.6), GPT-5.4 (openai/gpt-5.4), and Gemini 3.1 Pro Preview (google/gemini-3.1-pro-preview) — on a real production codebase. Flagship-tier models comparable to those in the published literature (though not version-identical; LOCA-bench, for instance, tested Claude 4.5 Opus and we ran 4.6); different tasks, different prompts, different noise profile. Where our findings agree with what’s already published, we say so. Where they diverge, we lead with our own data and explain the gap. Methodology details and the brief-to-finding mapping are in Appendix A. Raw JSONL logs for the four audited experiment families are available on request.
Critically, this is raw model evaluation, not deployed-system evaluation. We constructed each context window directly and made single API calls — no agentic tool loop, no sub-agent routing, no compaction or summarization mid-task, no skills or CLAUDE.md-style scaffolding, no live retrieval pipeline. The retrieval conditions in EXP2 simulate retriever outputs at four pre-defined quality levels rather than wrap a real retriever. This is the deliberate frame: it isolates the variable we care about — what happens to the model when it has to reason over the context it’s given — and makes every number in this article a raw-model baseline that a well-engineered harness like Claude Code or Cursor is designed to improve on, not a ceiling on what such a harness can achieve. (A poorly-designed harness can make things worse — aggressive compaction that strips needed context, a retrieval layer that returns the wrong files, sub-agent routing that loses task state — which is exactly why the four findings below double as the four problems any harness has to solve well.) Whenever you see a hallucination rate in this article, the right reading is: this is what the model does on its own; the harness exists to do better than this.
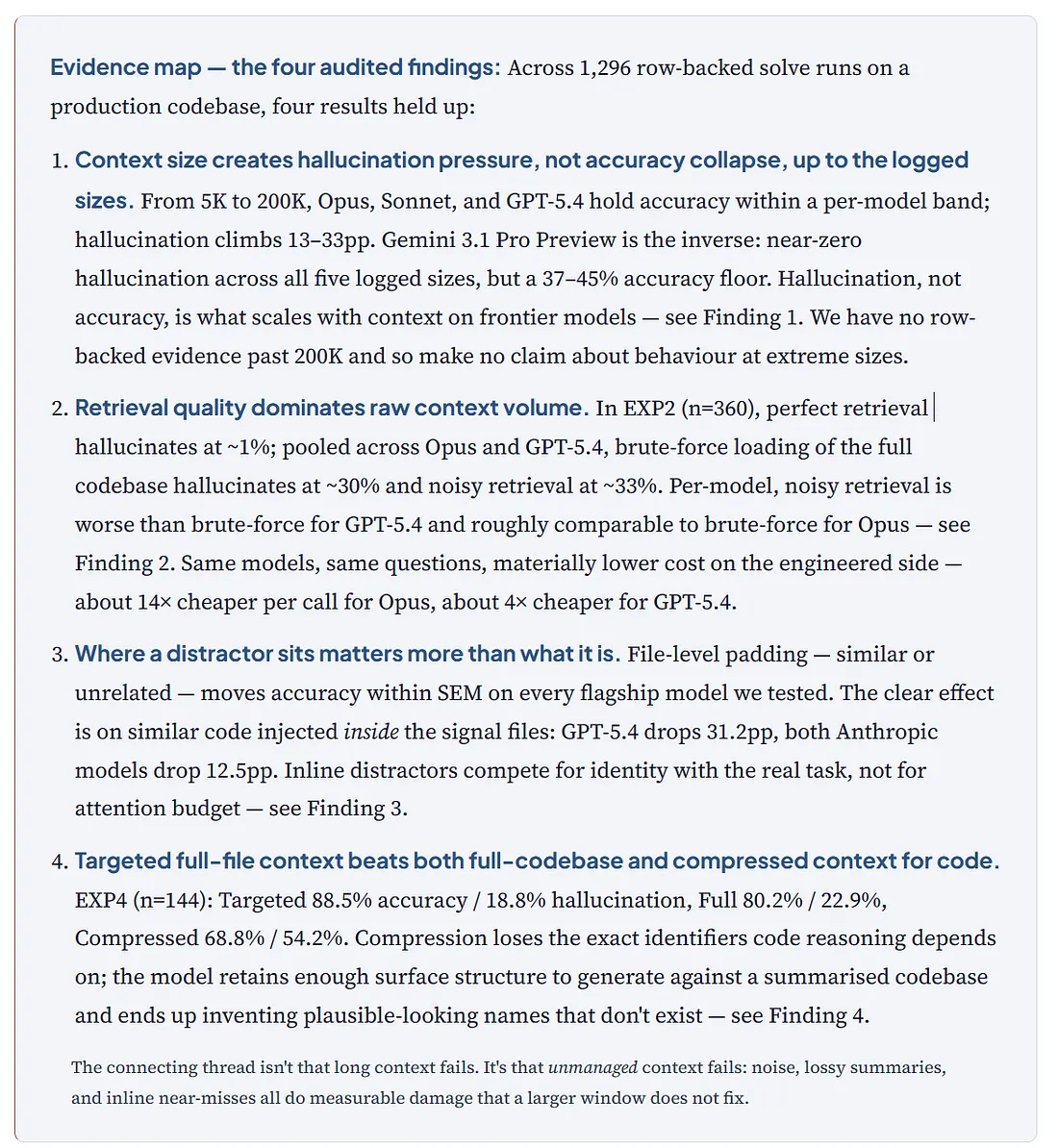
Our Own Evidence: 1,296 Row-Backed Solve Runs Across 4 Flagship-Tier Models
We ran four controlled experiment families totaling 1,296 unique row-backed solve runs. Every experiment has the same basic shape — a set of coding tasks graded three ways (correctness 0/1/2, hallucination 0/1/2, compilable 0/1) — with one variable changed at a time: context size (EXP1), retrieval quality (EXP2), distractor type (EXP3), or compression approach (EXP4). Everything ran at temperature 0. EXP1 covers all four flagship-tier models; EXP2 uses Opus and GPT-5.4; EXP3 and EXP4 use the three flagship-family models (Opus, Sonnet, GPT-5.4) with Gemini excluded per the brief. Sample sizes: the 1,296 calls are distributed across (model × condition × size) cells, with per-cell n ranging from 16 to 45. Findings represent directional patterns across multiple conditions and cross-model consistency rather than fully certified single-cell effect sizes. Scoring was done by Claude Sonnet 4.6 as LLM-as-judge with 216 rows manually re-scored as a validation sample; we ran the judge on a different model than the three other flagship models under test to reduce — though not eliminate — same-model circularity. The aggregate inter-rater agreement metric specified in the judge prompt was not computed as a summary statistic in our data, so we do not report it; the 216 re-scored rows are available alongside the raw JSONL on request. Three accuracy metrics appear in this article, defined in full in Appendix A: strict full credit (correctness = 2) is used on chart Y-axes labelled “full credit”; weighted correctness (mean(score) / 2 × 100) is the default for body-prose headline accuracy numbers; at-least-partial (correctness ≥ 1) appears as a diagnostic where it reveals a correct-area-wrong-fix pattern (notably Gemini in EXP1). Hallucination rates throughout are reported as the share of responses scoring hallucination ≥ 1.
All four audited experiments are single-turn API calls: system prompt + assembled context + question → response. We deliberately exclude MCP tool schemas, function-calling loops, multi-turn conversation history, and stale tool-call outputs so that one variable changes at a time per experiment. The article’s “MCP Tax” and “What’s Actually Inside the Window” sections later describe those as additional sources of context overhead that compound on top of the effects measured here. We expect our findings to generalize in direction to real agent setups but to under-state magnitudes — the noise sources we excluded are on top of, not instead of, the noise sources we tested.
Scope of the audited evidence. The four experiment families below are the ones with row-level JSONL backing. We cap our EXP1 degradation curve at 200K tokens because that’s where our padding toolkit ends; nothing in this article makes claims about behavior past 200K without an explicit citation to external work. Where we relied on a single audited dataset that supports only some models or some conditions, the relevant finding says so up front.
One scoring observation worth flagging: across brief-EXP3 and brief-EXP4, response compilability degraded more slowly than correctness. In the related-inline condition that dropped GPT-5.4’s accuracy 31pp, compilability stayed above 80% — code that runs but solves the wrong problem. A response can remain fully compilable while still reflecting severe reasoning corruption. Consequently, compilability alone substantially overestimates practical reliability in long-context coding tasks. We report all three rubric dimensions separately to avoid that bias.
Four Findings, In Brief-Experiment Order
Finding 1 — Frontier Models Stay Accurate as Context Grows, But They Stop Being Trustworthy
We ran ten coding bug-detection tasks at five logged context sizes (5K, 20K, 50K, 100K, 200K tokens), four models, three runs per cell. 600 calls total (EXP1, the original brief’s experiment 1). The buggy snippet was positioned mid-context; padding came from unrelated real codebases. The chart below shows the 5K → 200K arc.
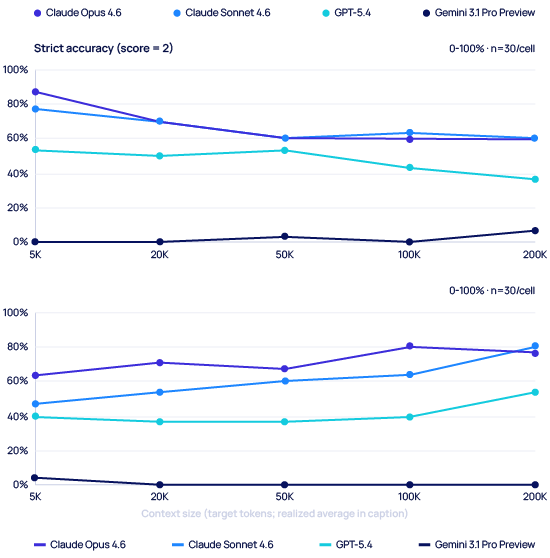
Hallucination rates: Opus, Sonnet, GPT-5.4 climb 13–33pp from 5K to 200K. Gemini Pro Preview stays in a 0–3% band. n=30/cell across EXP1.
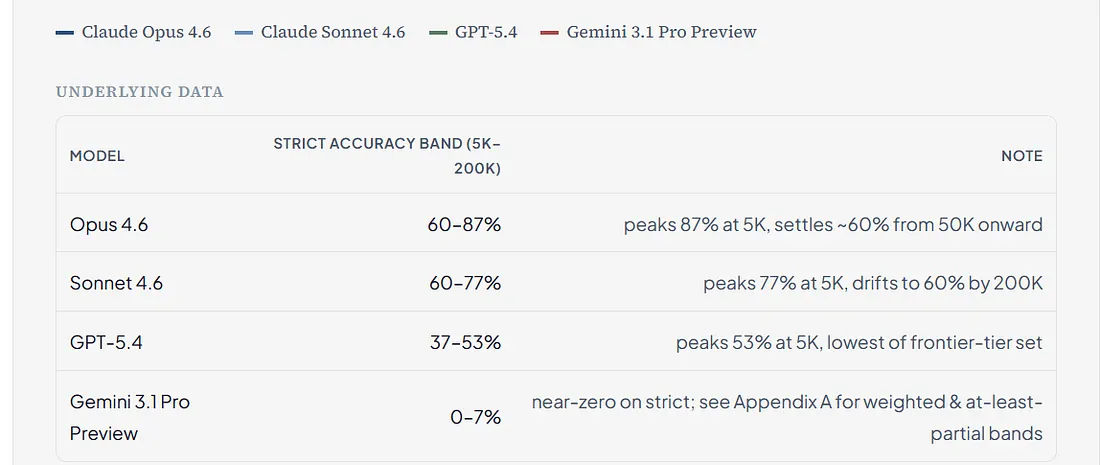
EXP1 only: 5K → 200K, all four flagship-tier models (Opus, Sonnet, GPT-5.4, Gemini 3.1 Pro Preview). Strict full credit (score = 2): Opus 60–87%, Sonnet 60–77%, GPT-5.4 37–53% across the five logged sizes — per-model bands of 14–27pp, no consistent downward trend after the 5K baseline. Gemini Pro Preview sits at 0–7% strict. Under weighted correctness (mean(score)/2 × 100), it lands in a 37–45% band; under the separate at-least-partial diagnostic, it reaches 73–83%. The gap is largest for Gemini because Pro Preview often produces correct-area-wrong-fix responses. Hallucination: the three non-Gemini flagship models climb 13–33pp from 5K to 200K; Gemini stays near zero (with very different accuracy implications — see body). Confidence intervals are 95% Wilson. Chart visual reflects strict full-credit (score=2) rubric; body-prose headline numbers use weighted correctness. Full rubric breakdown in Appendix A. Condition labels: reader-facing sizes (5K, 20K, 50K, 100K, 200K) match the raw run IDs (5K_total, 20K_total, 50K_total, 100K_total, 200K_total). Realized provider input counts averaged 6.1K, 22.5K, 55.2K, 109.7K, and 218.5K tokens per condition respectively (n=120 per condition, ranges in Appendix A). Source: our experiment 1, April 2026.
Two things jump out. First, on this particular task, accuracy on the frontier models is more stable than we expected — Claude Opus, Claude Sonnet, and GPT-5.4 point estimates stay in per-model bands of roughly 15–25 percentage points across five sizes from 5K to 200K, with no consistent downward trend. The confidence intervals at each point are wide (n=30, typical 95% CI half-widths of ±15 points), so we’re reading the absence of a downward trend across five sizes rather than any individual comparison. Bug detection is binary, the bugs were unambiguous, and the frontier models are good at it. If we’d only measured accuracy, we’d have been tempted to write a much more reassuring article.
Second — and this is what changed how we think about the problem — the hallucination rate tells a different story. Claude Opus’s hallucination rate climbed from 63.3% at 5K to 76.7% at 200K (peaking at 80.0% at 100K; 95% CIs overlap at n=30, directional rather than certified). The same upward drift shows up for Sonnet (+33pp from 5K to 200K) and GPT-5.4 (+13pp), and the elevated rate persists at 200K rather than reverting to baseline. The same sample-size limitation applies to the accuracy-stability claim above: we’re reading directional patterns across multiple models and sizes, not fully certified single-cell effects. Gemini Pro Preview shows the opposite signature: hallucination rates of 0–3% across every context size we tested (3.3% at 5K, 0% at every other condition; n=30 per cell), the lowest of any model in our set. But Pro Preview’s accuracy across those same conditions sits in the 37–45% range — also the lowest of any model in our set. This is the article’s “hallucination alone is insufficient as a quality metric” thread stated as data: Pro Preview’s near-zero hallucination rate reflects a tendency to produce generic, non-committal responses rather than specific (and thus fabricatable) claims. A model that says nothing specific cannot hallucinate, but it also cannot help. Opus, Sonnet, and GPT-5.4 aren’t getting worse at finding real bugs as context grows; they’re getting worse at not inventing fake ones. In production, that second failure mode is the one that costs you: a confident wrong answer wastes more engineer time than a missed answer ever does.

Why Strict Accuracy Starts Below 100%
A reader looking at the left panel might reasonably ask: at 5K tokens with just the relevant file in context, shouldn’t accuracy be at or near 100%? There’s no padding, nothing to distract. The answer is no, and the reason matters.
The scoring rubric is strict by design (per the experiment brief): a score of 2 requires both identifying the exact bug and proposing a valid fix. A response that correctly locates the bug but proposes a slightly incomplete fix gets 1 — partial credit, which the “full credit” chart doesn’t count. At the 5K baseline, Opus scored 2/2 on 26 of 30 runs (86.7% strict, rounded to 87% in the figure) and 1/2 on the remaining 4 runs (partial credit, no 0/2). Across the full 5K–200K range, Opus’s strict pass rate drops from 86.7% at the baseline into the 60–70% band at 20K and above, with the partial-credit count rising as the strict count falls. That distribution is what the chart is plotting.
Finding 4 below — the compression vs. targeted-loading ablation on EXP4 (144 row-backed runs) — quantifies the ceiling directly. When each of the three flagship-family models tested in EXP4 (Opus, Sonnet, GPT-5.4; Gemini excluded from EXP4 per the brief) is given a 200-word project overview plus the 3–5 relevant files (the “targeted_groundtruth” condition, ~10K avg input, eight tasks), strict full-credit accuracy lands at 81% for Opus, 75% for Sonnet, and 75% for GPT-5.4 — versus 67%, 66%, and 47% respectively on the EXP1 baseline averaged across the logged 5K–200K range. The gap between the EXP1 baseline and the EXP4 targeted ceiling — 9 to 28 percentage points depending on the model — is larger than any single change caused by padding from 5K up to 200K within EXP1 itself. Finding 4 below isolates the compression-vs-targeted question on the same 144-row dataset.
That reframes the context-rot finding on accuracy as: padding doesn’t move the needle much at these sizes, but it also doesn’t need to — the baseline is already below the achievable ceiling because the model lacks architectural context. The real accuracy signal on a brute-loaded codebase isn’t the size — it’s the hallucination climb on the right panel.
Chroma’s 2025 study found similar accuracy erosion across 18 models on text-retrieval tasks; HKUST’s LOCA-bench (2026) found it on agent traces.[1][2] Our data for the hallucination failure mode on code is an extension of those findings, not a replication — the accuracy-vs-hallucination divergence is something we haven’t seen cleanly broken out in the published literature.
Finding 2 — Retrieval Quality Dominates Context Size: Noisy Retrieval Undermines the Win
Retrieval quality dominates raw context size — at both extremes. Same two flagship-family models, same fifteen bug-detect tasks: hallucination rate is ~1% under perfect retrieval, ~6% with model-retrieved, ~30% under brute-force loading of the full 200K+ codebase (pooled), and ~33% pooled when retrieval returns the correct files plus two semantically plausible decoys. Per-model, contaminated retrieval is worse than brute-force for GPT-5.4 (33.3% vs 24.4%) and roughly comparable to brute-force for Opus (33.3% vs 35.6%, where brute-force is in fact marginally worse). The cliff is at the extremes, in both directions: a clean window beats a full one by ~30×, and a window contaminated with adjacent-but-wrong files is at least as bad as just loading everything.
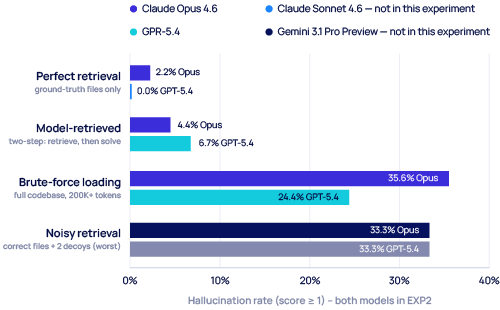
EXP2 retrieval ablation. Same models, same tasks, four retrieval strategies. The two cliffs (perfect-retrieval at the clean extreme and noisy-retrieval at the contaminated extreme) demonstrate that retrieval quality dominates context quantity. Source: our experiment 2, April 2026.
EXP2 (the brief’s experiment 2) ran this as a 360-row retrieval ablation: four conditions (perfect, model-retrieved, noisy-retrieved, brute-force-loaded), two flagship-family models (Opus and GPT-5.4), 45 reps per (model × condition) cell. The noisy-retrieved condition is constructed by protocol as the correct files plus two semantically plausible decoys — the ground-truth files are present in context by construction. That tightens the decoy reading of this experiment: the model wasn’t missing the right files; the two decoys we added on top of correct retrieval are what drove the hallucination spike. The full per-condition, per-model breakdown — including cost and latency — sits in “The Numbers: Better Context Beats More Context” further down, where it carries the engineered-vs-brute-force argument in detail.
Finding 3 — Inline Distractors are Catastrophic; File-Level Padding is Within Noise
For the distractor-type test, we held the relevant file constant and varied what kind of noise sat around it: no distractor (clean baseline), unrelated file (e.g., NumPy stats code in a Postgres bug task), related file (semantically similar code in a separate file), and related inline (one fake “similar but wrong” function injected directly inside the relevant file itself). 8 tasks × 4 conditions × 3 flagship-family models × 2 reps = 192 calls. Gemini excluded per the brief.
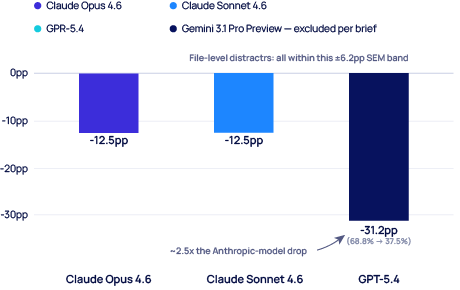
File-level padding (unrelated or similar code in separate files) ranges from −6.2 to +6.2pp, all within SEM (8.5–12.5pp). The clear effect is inline. brief-EXP3, n=16/cell. Gemini excluded per brief.
EXP3 distractor-type comparison (brief’s experiment 3), 3 flagship-family models, 4 conditions, n=16 per cell. File-level distractors (Unrelated and Related) move accuracy within SEM on every model. The clear effect is on Related Inline, where similar code is injected directly into the signal files: GPT-5.4 drops 31.2pp, and both Anthropic models drop 12.5pp. Gemini not included — excluded from brief-EXP3 per the brief. Source: our experiment 3 (brief’s experiment 3), April 2026.
On natural text, Chroma found similar > unrelated in damage among file-level distractors.[2] On code, our data don’t support that ordering at the file level — padding accuracy effects (similar or unrelated) ranged from −6.2 to +6.2pp across all three flagship-family models, every magnitude inside its own SEM of 8.5–12.5pp. The clear effect is on inline distractors: when similar code is injected directly into the signal files rather than as separate padding, GPT-5.4 drops 31.2pp (68.8% → 37.5%), and both Anthropic models drop 12.5pp. The mechanism isn’t attentional; it’s interpretive. A function with a similar signature embedded next to the real one isn’t competing for tokens; it’s competing for identity. (n=16 per cell, 3 flagship-family models, brief-EXP3. Gemini excluded per the brief.)
At the pooled cross-model level (n=48 per condition), related-file padding shows a small consistent drag (−2.1pp vs clean) directionally toward Chroma’s natural-text finding, though within per-model SEM. We don’t lean on it — the inline collapse is the much larger and cleaner story — but it’s worth noting that the per-model “within noise” finding masks a small pooled effect. The within-SEM file-level variation isn’t flat either: Opus drops on both unrelated and related-file conditions (−6.2pp on each), Sonnet gains on unrelated (+6.2pp) and loses on related (−6.2pp), and GPT-5.4 gains on both (+6.2pp each). Every cell sits inside its own SEM, but the per-model directions disagree — we read this as noise around a small true effect, not a clean replication of Chroma’s natural-text ordering on code.


What this means in practice: the conventional wisdom around “avoid semantically similar context” may be misdirected for code at the file level. Across our three flagship-family models, similar-file and unrelated-file padding produced effects within SEM, both close to the clean baseline. The decisive variable is whether the distractor sits inside the relevant file or alongside it. Inline near-misses corrupt diagnosis; file-level padding mostly doesn’t, regardless of similarity. We tested one codebase, so this needs to replicate — but the direction is consistent across all three flagship-family models we ran.
Finding 4 — Targeted Context Beats Both Full and Compressed Context on Accuracy and Cost
For the “compression paradox” test — does removing information actually improve results? — we took 8 tasks and ran each under three conditions: Full (whole codebase plus prompt, ~332K avg input), Compressed (2–3 sentence AI-generated summaries of every file, with full content for 3–5 relevant files, ~19K avg input), and Targeted (3–5 relevant files only, ~10K avg input, no project overview).
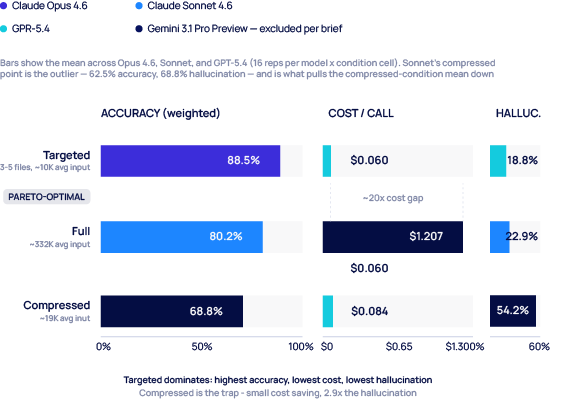
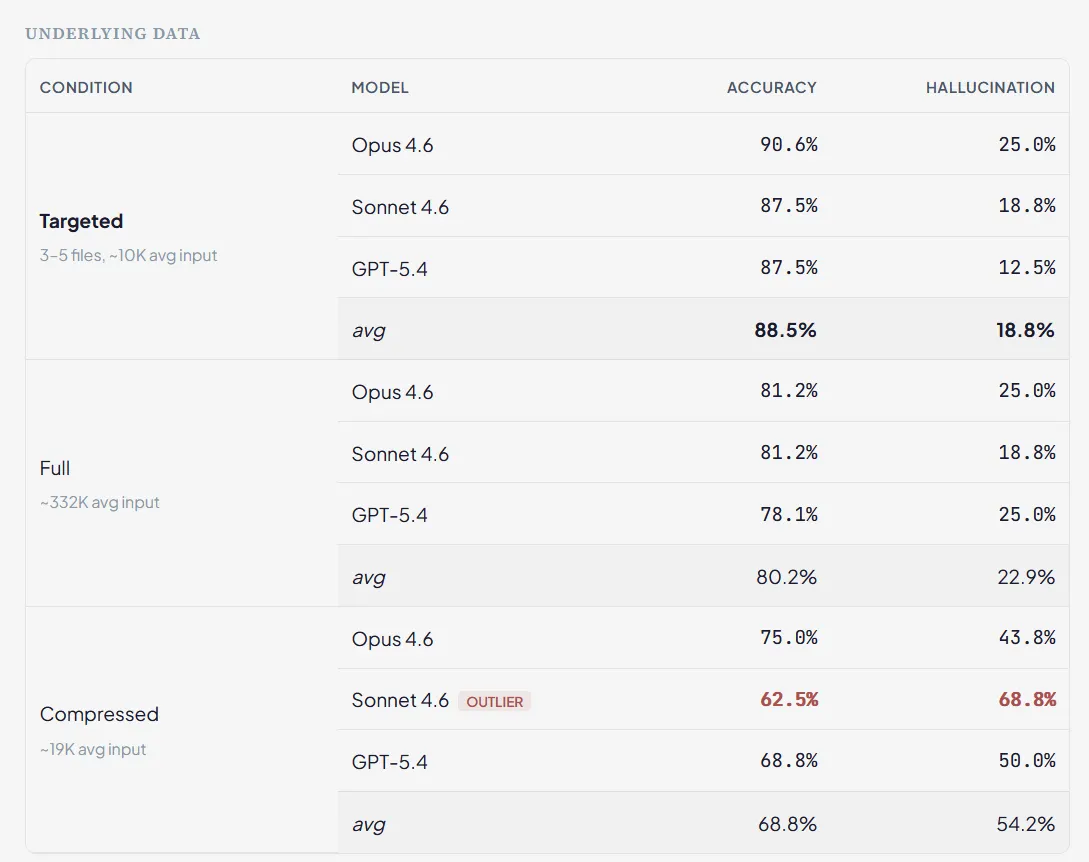
Per-model breakdown shows the source of the compressed-condition collapse: Sonnet alone drops to 62.5% accuracy / 68.8% hallucination (the dataset’s worst single cell), while Opus and GPT-5.4 hold above 68.8% accuracy on compressed. The 3-model average masks the spread. brief-EXP4, n=16 per (model × condition) cell. Gemini excluded per brief.
EXP4 compression-strategy comparison (brief’s experiment 4), 3 flagship-family models (Opus 4.6, Sonnet 4.6, GPT-5.4), n=16 per cell. The Pareto-optimal region is bottom-right of the cost axis, top-right of the accuracy axis. All three Targeted points cluster there. Compressed points (notably Sonnet) drop sharply in accuracy and spike in hallucination at modest cost reduction vs Targeted. Full points hold accuracy but at 20× cost. Gemini not included — excluded from brief-EXP4 per the brief. Source: our experiment 4 (brief’s experiment 4), April 2026.
Targeted (88.5%) beat Full (80.2%) beat Compressed (68.8%) — averaged across the 3 flagship-family models in brief-EXP4 — with roughly 20× lower cost than Full ($0.060 vs $1.207 per call) and a hallucination rate less than a third of Compressed (18.8% vs 54.2%) — and noticeably below Full as well (22.9%). (Worth pausing on the comparison to Finding 1’s strict bands: EXP4’s 88.5% is weighted correctness (mean(score)/2 × 100) averaged across three models on EXP4’s eight tasks, not the strict score=2 rubric the EXP1 chart uses. Different task set, different metric — see Appendix A. The right way to read these two findings together: the EXP1 chart shows how the strict rubric degrades with context size on a degradation-curve task set; EXP4 shows how weighted correctness reflects what the model actually returns on a separate task set under three retrieval strategies. Both are row-backed; both are documented.) The compression result was the surprise of this experiment: every model degraded under compressed context, and Sonnet collapsed to 68.8% hallucinations under the compressed condition — more than half of responses contained fabricated API names or function references. Compression isn’t lossless in the way that matters here: the model retains enough of the surface structure to generate code against the summarised codebase, but loses enough of the specifics to invent plausible-looking names that don’t exist. Targeted loading wins. Pull the few files the task actually needs into the window in full; don’t summarise the whole codebase and hope. (n=16 per cell, 3 flagship-family models, brief-EXP4. Gemini was excluded from brief-EXP4 per the brief.)
This diverges from Morph’s findings on natural-text compression.[12] In natural text, summarization preserves the gist that downstream tasks need. On code under the conditions we tested, summaries replace the concrete identifiers (function names, parameter names, exact module paths) that the model needs to ground its output, and the model hallucinates plausible-looking replacements rather than reasoning at a higher level. Code identifiers don’t paraphrase.
What Didn’t Hold Up in Our Data
Two things we expected to see, but didn’t.
No clean signal-to-noise threshold on frontier models in the audited retrieval rows. Within EXP2’s four retrieval conditions (perfect, model-retrieved, noisy-retrieved, brute-force), the dominant story is a strong noise effect at the extremes: ~1% hallucination on perfect retrieval versus ~30% on brute-force loading of the full codebase. What we did not see was a clean S/N-ratio threshold on Claude Opus and GPT-5.4. Between conditions, the cliff was sharp; within a condition, accuracy held up. We report the cliff-at-the-extremes pattern as the EXP2 finding and the absence of a within-condition threshold as a null result. Possibly the bugs were unambiguous enough that even noisy context gave enough signal to locate them. Weaker models would probably show a cleaner threshold.
Frontier models do not catastrophically collapse at 100K. A natural hypothesis going in was that accuracy would fall off a cliff by 100K on all models. EXP1 does not support that. Claude Opus at 100K performs within CI of its 5K baseline on accuracy. The hallucination rate climbs steadily; accuracy holds. The real cliff is at the budget tier (Gemini Pro Preview’s 37–45% weighted-correctness floor across every logged size in EXP1). Frontier models at standard sizes resist accuracy degradation surprisingly well; what they don’t resist is the silent rise in hallucination, which is the failure mode that costs you in production.
Context Rot: The Problem Nobody Warned You About
Nobody mentions this when they sell you a bigger context window: under the wrong conditions, your model can start getting worse long before you hit the limit. Context rot is the term the published literature has settled on for it: measurable degradation in output quality as input length increases, particularly when context is noisy, poorly structured, or reasoning-heavy. It is not a universal collapse law. It is a conditional failure mode — one that shows up clearly in the broader literature (Chroma’s 18-model retrieval study, LOCA-bench’s agentic traces, Paulsen’s stress-test sweeps) and that our own audited code experiments confirm on the dimension we tested most carefully: hallucination rises with context size for non-Gemini frontier models from 5K to 200K, even when accuracy doesn’t move much.
Most engineering teams think about context limits in terms of overflow: you hit the token ceiling, the model refuses the request or silently drops older content. Overflow is a cliff. You see it, you fix it, you move on.
Context rot works differently. On the kinds of tasks where it does show up, a model with a 200K token window can show measurable degradation at 50K tokens.[2] Nothing breaks. No error appears. The outputs just get gradually, silently worse — more hallucinations, more ignored instructions, more confident wrong answers. And because nothing visibly fails, teams often don’t realize it’s happening until the damage is done. The published evidence is strongest on retrieval and agentic tasks; our audited evidence is on coding bug-detection, where the dominant signal is hallucination drift rather than accuracy collapse. Different tasks, same direction.
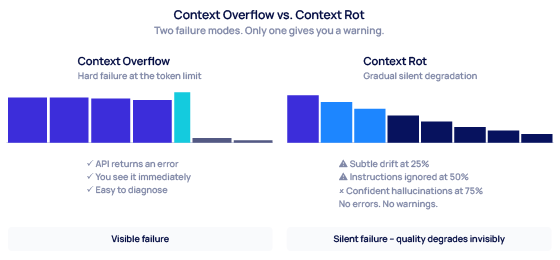
Most teams engineer for overflow. Context rot is far more dangerous — it starts long before any limit is reached.[2][13]
Why We Missed It
For years, the standard test for long-context capability has been the Needle-in-a-Haystack (NIAH) task: hide a known sentence in a long document and ask the model to find it. Frontier models ace this test. It’s reassuring. It’s also almost useless.
NIAH tests simple lexical retrieval — the model pattern-matches a sentence it was explicitly told to look for. Real-world tasks demand something fundamentally harder: synthesis across scattered information, multi-step reasoning over ambiguous data, and identifying relevance without being told what matters.[2] These are exactly the conditions where context rot is most severe.
NIAH basically tests whether the model can pattern-match a sentence you told it to look for. It says very little about whether the system works on tasks where relevance isn’t pre-labeled.
What Chroma Found
Chroma’s 2025 study is probably the most thorough look at this we have so far. They tested 18 frontier models — GPT-4.1, Claude 4, Gemini 2.5, Qwen3, and others — on retrieval tasks where they held difficulty constant and only varied input length. Not a perfect setup (retrieval tasks are easier than real work), but it isolates the variable cleanly.[2]
Every model degraded as context grew. All eighteen, including the state-of-the-art. No exceptions.
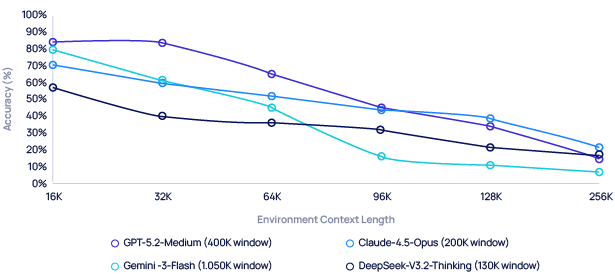
Model accuracy on LOCA-bench tasks as environment description length grows. Baseline ReAct scaffold; each model evaluated at its maximum context length.[1] Chart starts at 16K for readability; LOCA-bench’s 8K rung is omitted — per the cited paper, the 8K-to-16K step shows little movement and the degradation curve is clearer from 16K onward. Source: Zeng et al. (2026), Table 1.
But Chroma wasn’t alone. An independent study published the same year went even further — and its findings are harder to ignore.
The 99% Gap
Norman Paulsen’s September 2025 study introduced a concept that should be on every engineering leader’s radar: the Maximum Effective Context Window (MECW). It’s the point beyond which more tokens stop helping and start hurting — as distinct from the Maximum Context Window (MCW), which is just the number on the model card.[13] Paulsen’s headline framing is stark, but the most useful thing about MECW is its underlying claim: effective context is task-dependent. The number is not a fixed model property; it shifts with what you’re asking the model to do.
Paulsen tested across multiple frontier models and problem types. His most extreme numbers — the “99% gap” framing in particular — come from sorting, aggregation, and multi-step logic tasks specifically designed to stress the attention mechanism. Those are not representative of the typical LLM workload, and they are not what we measured in our own experiments. Read at face value, Paulsen’s numbers are the worst-case bound, not the typical case. But even if you discount the most extreme cases, the directional.

Source: Paulsen (2025), “Context Is What You Need”[13]
Under those stress-test conditions, models advertising 128K, 1M, even 10M token windows showed effective windows of roughly 100 to 2,500 tokens — the “99% gap” between what’s on the spec sheet and what actually works on those particular tasks.[13] The headline is real for the workloads Paulsen tested, but it’s a ceiling claim under adversarial conditions, not a typical-case prediction. Retrieval tasks do meaningfully better; our own audited coding tasks show a much smaller gap than Paulsen’s worst-case numbers (Finding 1 below). The takeaway isn’t that all models only really use 1% of their context. It’s that the effective ceiling depends sharply on the task, and that for reasoning-heavy or aggregation-heavy work, the gap between advertised and effective capacity is wide enough to be a primary engineering concern.
The MECW takeaway: Effective context is not a fixed property of a model — it shifts based on problem type. Simple retrieval tasks tolerate longer effective windows (~3,000–5,000 tokens in Paulsen’s data). Complex reasoning, sorting, and aggregation tasks collapse much earlier (~400–1,200 tokens under Paulsen’s stress-test setup).[13] The same model that aces a needle-in-a-haystack test at 100K tokens may fail a multi-step reasoning task at 1,000. Plan capacity around the hardest task you actually run, not the advertised maximum.
Two more findings from Paulsen’s study that matter for anyone building production systems. First: as context size increased on his stress-test workloads, hallucination rates exceeded baseline rates for every model tested. For the worst performers on the hardest tasks, hallucination approached 100%. Those models weren’t just getting worse; they were generating almost entirely fabricated output.[13] Frontier models on easier tasks (and on our own coding workloads in Finding 1) show much smaller increases, but the directional pattern (hallucination rises with context) is the consistent one.
Second, and this one should concern anyone relying on RAG: retrieval-augmented generation can reach near-perfect accuracy if utilized within the MECW. But it actively worsens performance when context exceeds the MECW.[13] The very technique most teams use to manage long documents can backfire if you don’t understand your model’s effective limits.
Our Finding 1 above puts per-model, per-size numbers on Paulsen’s MECW concept for coding tasks across the 5K–200K range we have row-level evidence for: none of the four flagship-tier models hits anything near their advertised window in effective accuracy on this workload. Under strict full credit (score=2), Opus peaks at 87% at the 5K baseline and settles around 60% from 50K onward; Sonnet peaks at 77% and drifts to 60% by 200K; GPT-5.4 peaks at 53%; and Gemini 3.1 Pro Preview holds a 0–7% strict floor across every size we logged — reflecting Pro Preview’s tendency to produce correct-area-wrong-fix responses (Appendix A gives the corresponding weighted and at-least-partial bands under the same data). Either way, none of the four matches its advertised window in effective accuracy on this workload — that’s the MECW gap made tangible on workloads teams actually ship. (Our row-backed evidence stops at 200K; we make no claim about behavior at larger context sizes.)
Chroma found degradation across every model in its tested 18-model suite. Paulsen quantified the task-dependent effective-context gap. And independent peer-reviewed research confirmed the pattern: Hosseini et al., published at COLING 2025, tested Claude 3, Gemini Pro, GPT 3.5, Llama 3, and Mistral on text classification tasks. They found that context management strategies improved accuracy by up to 50% while reducing API costs by 93% and latency by 50% — a formally peer-reviewed confirmation that engineering what goes into the window matters more than the window’s size.[15]
But Chroma’s most striking results went even deeper than the headline.
The Shuffled Text Paradox
Chroma also varied the similarity between their needle-question pairs — how closely the phrasing of the question matched the target information. As similarity decreased (moving from exact lexical matches toward the kind of semantic, inferential matching real tasks require), performance degraded significantly more with increasing input length.[2]
This is where real-world systems break. Real questions almost never match their answers lexically. When a developer asks “why is this endpoint timing out?” the answer might live in a rate-limiting config, a retry policy, or a load balancer setting — none of which contain the word “timeout.” The model has to infer relevance, and that inference gets worse as context grows.
The Architecture Behind the Failure
To understand why this happens, you have to look at how these models actually process context.
The degradation isn’t random. Research from Stanford (Liu et al., 2024) established that LLM accuracy follows a U-shaped curve across the context window: models attend strongly to tokens at the beginning and end of the input, but drop 30% or more for information positioned in the middle.[3]

Adapted from Liu et al. (2024).[3] Models attend strongly to the beginning and end, but accuracy drops 30%+ in the middle.
No firmware update fixes this. The root cause is architectural. Most modern LLMs use Rotary Position Embeddings (RoPE), which introduce a long-term decay effect that naturally de-emphasizes middle positions. The further a token sits from the beginning or end of the context, the weaker its influence on the model’s output. This is baked into the math of how transformers compute attention.
And the pattern shifts as context fills up. Veseli et al. (2025) found that the U-shaped bias only persists when the context is less than 50% utilized. Beyond that threshold, a different pattern emerges: the model increasingly favors the most recent tokens, then middle tokens, while early content fades almost entirely.[11] For any system that accumulates context over time — which includes every agent, every multi-turn conversation, and every RAG pipeline — this means the instructions and constraints you set at the beginning are the first things the model forgets.

Not All Noise Is Created Equal
One more finding from the research that complicates the picture further: the type of irrelevant content in the context window matters. Chroma found that adding list operations that locally cancel each other out degraded model performance significantly more than adding inert print statements.[2] Content that is semantically adjacent to the task — plausible but wrong — is far more damaging than content that is obviously unrelated.
For coding agents, this is devastating. Every search result, every similar-but-not-quite function signature, every file that shares terminology with the target — these aren’t just wasted tokens. They’re active distractors that pull the model’s attention away from the information that matters.
The Reframe
The right metric for context quality isn’t capacity — how many tokens can the model accept. It’s signal-to-noise ratio — what proportion of the context is actually relevant to the task at hand. And most systems today are overwhelmingly noisy.
And here’s the cost dimension that makes this an executive-level concern: you’re not just paying for irrelevant tokens. You’re paying for tokens that actively degrade the tokens that matter. Every unnecessary file read, every verbose tool output, every uncompacted conversation turn — these aren’t neutral overhead. They’re paying to make your system worse.[2] At some point, you have to ask: Are you building an intelligent assistant, or a very expensive confusion engine?
Your context window isn’t a filing cabinet. It’s a spotlight. The bigger you make it, the dimmer it gets.
The Paradox in Practice: Why Coding Agents Suffer Most
Context rot affects every LLM application. But coding agents are the worst case — by a wide margin. They don’t just suffer from context rot. They amplify it.
To see why, look at what actually fills the context window now versus two years ago.
What’s Actually Inside the Window
In the pre-agent era — simple chat, document Q&A, single-turn prompts — the context window was mostly signal. A system prompt, a user question, or maybe a pasted document. Total: a few thousand tokens, almost all of it relevant to the task.
In the agent era, the same window fills with an entirely different composition:
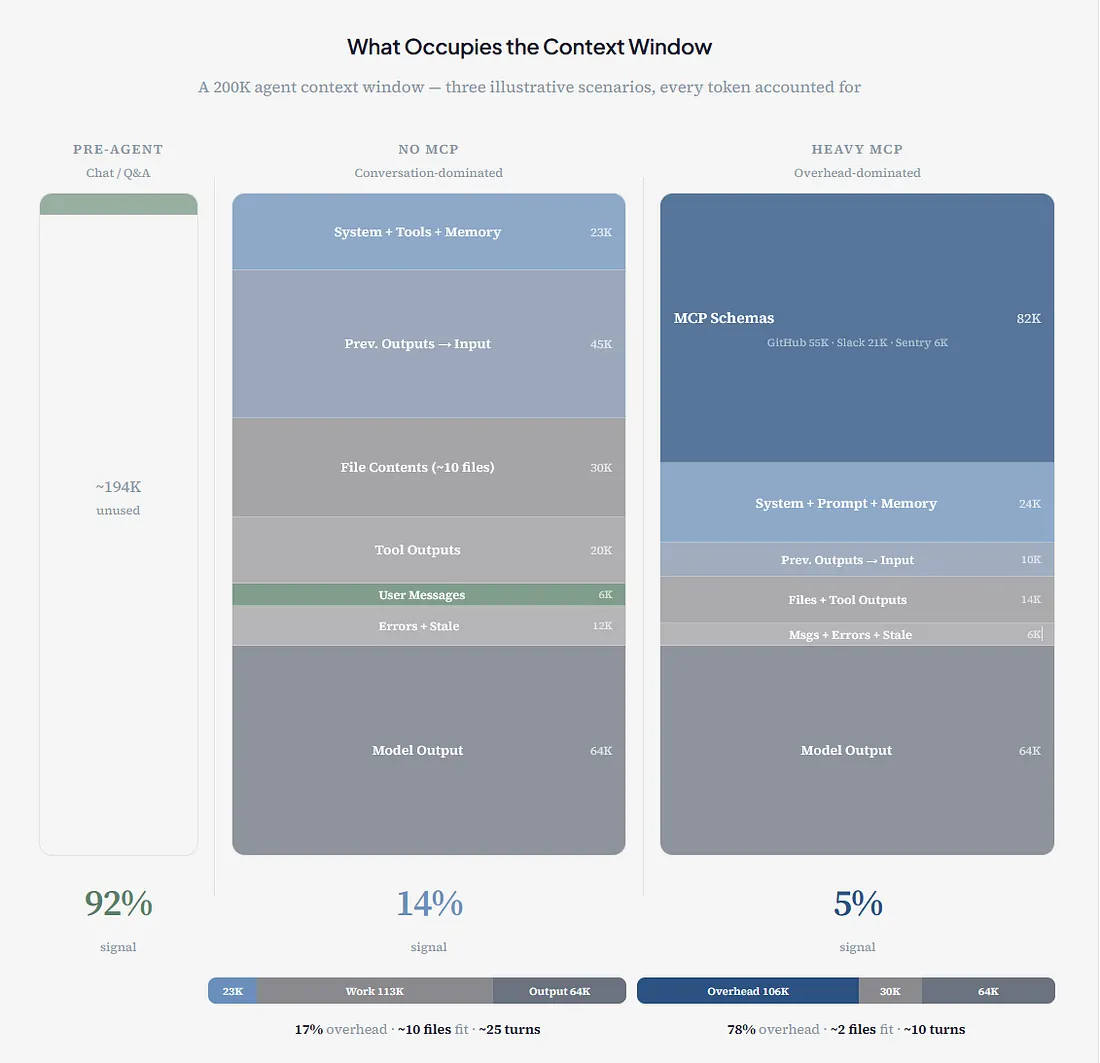
Illustrative composition figure. Token-count buckets are order-of-magnitude estimates derived from publicly reported /context readouts and deployment writeups (wmedia.es, jdhodges.com, paddo.dev, AgentPMT, Apideck). Each scenario sums to exactly 200,000 tokens by construction. 200K shown — the default session window for most Claude Code plans.
Even without MCP, only 14% of your input is task-relevant signal. The bottleneck shifts from protocol overhead to accumulated conversation history — but the context rot problem remains. MCP makes it dramatically worse, but it doesn’t create the problem.
The MCP Tax
So far I’ve been talking about context that accumulates during a session: files, tool outputs, conversation history. But there’s a whole other category of bloat that shows up before you even start working. A significant (and often overlooked) portion of the degradation starts before the agent does any work at all, in the form of protocol overhead.
The Model Context Protocol (MCP) — the open standard for connecting AI agents to external tools — illustrates the problem vividly. MCP requires each tool to be described with a JSON schema that includes semantic descriptions, parameter formatting instructions, enum values, and few-shot examples. A single tool definition averages 550–1,400 tokens. A single integration like GitHub brings 35+ tools. Connect three services — GitHub, Slack, and Sentry — and you’re looking at north of 80,000 tokens of tool definitions loaded into every conversation, whether the agent uses them or not (GitHub alone accounts for the largest slice; see the per-service split in the figure above).
One developer reported their full MCP setup consuming 143K of their 200K token window — 72% of capacity — before a single user message arrived. At the Ask 2026 conference, Perplexity CTO Denis Yarats announced his company was moving away from MCP internally, citing this exact overhead.
The industry response is converging on progressive disclosure — loading capabilities in layers rather than all at once. The Skills architecture, now adopted across Claude, OpenAI, GitHub Copilot, and LangChain, loads only a skill’s name and description at startup (~100 tokens per skill). Full instructions load only when the agent determines a skill is relevant. Compare: all 17 Anthropic built-in skills cost approximately 1,700 tokens at discovery. The equivalent MCP tools would consume 55,000+. That’s a 32× reduction in context overhead, with no loss of capability.
Anthropic’s own engineering team demonstrated the endpoint of this approach: code execution with MCP, where agents write code to interact with tools instead of calling them through the context window, achieved a 98.7% reduction in context overhead.[16]
In the agent era, your context window isn’t consumed by your task — it’s consumed by the infrastructure around your task. MCP schemas, tool definitions, system prompts, and conversation scaffolding can eat 40–50% of your window before the first user message arrives. Making the window bigger doesn’t solve this. Loading less does.
This is why the context window arms race misses the point. A 200K window that was over 90% signal in the chat era becomes nearly 80% infrastructure overhead in the agent era. Making it 1M tokens doesn’t solve the composition problem — it just makes every other cost 5× larger. Capacity was never really the bottleneck; composition is.
The Shared Budget: Input vs. Output Tokens
There’s one more dimension of context window composition that most teams overlook: input and output tokens share the same budget. The context window isn’t just what you send to the model — it’s what you send plus what the model generates back. And on the next turn, the model’s previous output becomes part of the input.
This isn’t just a frontier-model problem. Whether you’re on a 4K or 1M window, the model reserves part of it for output, and you get the rest. Across the spectrum:
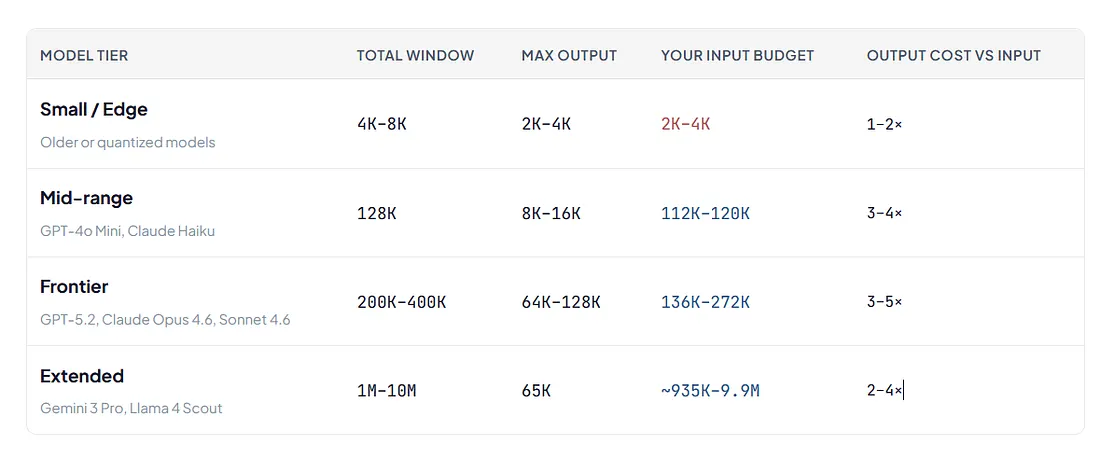
All values in tokens. 1K tokens ≈ 750 English words ≈ 300–500 lines of code. Pricing as of March 2026.
At the small end, a model with a 4K total window and a 2K max output only leaves 2K tokens for your entire input — system prompt, user message, and context combined. That’s roughly 1,500 words. A single RAG document can exceed this. At the frontier end, GPT-5.2’s 400K window sounds generous until you realize 128K is reserved for output, leaving 272K for input. The headline number on the model card is never the number you actually get to use.
It gets expensive, too. Output tokens cost 3–5× more than input across all major providers. But on the next turn, that expensive output becomes input — and it still eats from the same attention budget. You pay premium rates to generate it, then it competes with your actual task context for the model’s attention on every subsequent turn.

This is why the most effective coding agents keep outputs compact. The approach of generating targeted diffs rather than echoing entire files — used by Claude Code, Aider, and other context-aware tools — isn’t just about readability. It’s about preserving input budget for future turns. A 500-line file echo costs 2,000+ tokens of output that become 2,000+ tokens of input on the next turn. A 10-line diff costs 50 tokens. Same information, 40× less context pressure.
There’s a less obvious angle here too. A March 2026 study by Hakim tested 31 models across 1,485 problems and found that on a meaningful subset of tasks, larger models actually scored worse than smaller ones — by 28 percentage points. The culprit was overelaboration: the bigger models were verbose enough to talk themselves into wrong answers. When the researchers added brevity constraints — basically just telling the model to keep it short — large-model accuracy jumped by 26 points and the performance rankings flipped entirely on math and science benchmarks. The models didn’t get smarter. They just stopped drowning in their own output.[18] It’s the same dynamic we’re seeing with context rot, just on the output side: more tokens doesn’t mean more signal.
Coding agents have three structural properties that maximize this degradation, and understanding them explains why the “just make the window bigger” approach fails hardest in exactly the domain where people most want it to work.
Three Properties That Maximize Rot
Accumulative context
Every file read, every grep result, every tool output, every error trace stays in the window for the rest of the session. A human developer looks at a file and moves on. An agent looks at a file and drags it along forever. If you’ve watched any coding agent session hit the compaction wall at turn 15 (Claude Code, Cursor, Copilot), you’ve seen this firsthand. Over a 30-minute session, context only grows; quality only drops.[13]
We ran into this during a refactoring project — nothing exotic, just migrating an internal service from REST to gRPC. The agent handled the first three files fine. By file eight it was mixing up the old REST handlers with the new gRPC stubs, referencing function signatures from files it had read twenty minutes earlier. Same session, same model, same prompt. The context had just accumulated too much similar-looking code. We ended up splitting it into per-file subagent calls, which felt like overkill at the time. Accuracy went right back up.
High distractor density
Code search returns many semantically similar results. When you grep for a function name, you get the definition, the tests, the mocks, the deprecated version, the wrapper, and three files that import it. Each result shares terminology and patterns with the target. This is exactly the type of content Chroma found to be most damaging — plausible distractors that pull attention away from the actual answer.[2]
Long task horizons
Real coding tasks take 15 to 60 minutes of agent interaction. During that time, context grows continuously while the signal-to-noise ratio steadily worsens. By the time the agent reaches the critical decision point — applying the fix, writing the test, making the commit — it may be operating at the lowest quality point of the entire session.
The Enterprise Code-base Gap
Okay, different angle. Forget context rot for a second — even if models could use their full window perfectly, the capacity argument still doesn’t hold.
Factory.ai — a company building agentic coding tools — analyzed real enterprise codebases and found that a typical production monorepo spans several million tokens — with millions more tokens of relevant context living outside the code in Slack threads, Notion docs, Datadog dashboards, and commit histories.[9]
A million-token window holds maybe 50,000–100,000 lines of code. Sounds like a lot until you realize most enterprise codebases are bigger than that. And as we’ve established, filling the window degrades the model’s ability to use what’s inside. Even if the window were infinite — which doesn’t help — there’s still too much code.

The Numbers: Better Context Beats More Context
Finding 2 above gave the headline for EXP2; this section gives the underlying four-condition breakdown. The EXP2 retrieval ablation tests four conditions — perfect retrieval, model-retrieved, noisy-retrieved, and brute-force — against two flagship-family models, with 45 reps per (model × condition) cell on the 360-row dataset. It is the only fully first-party data we have on the engineered-vs-brute-force question at this granularity:
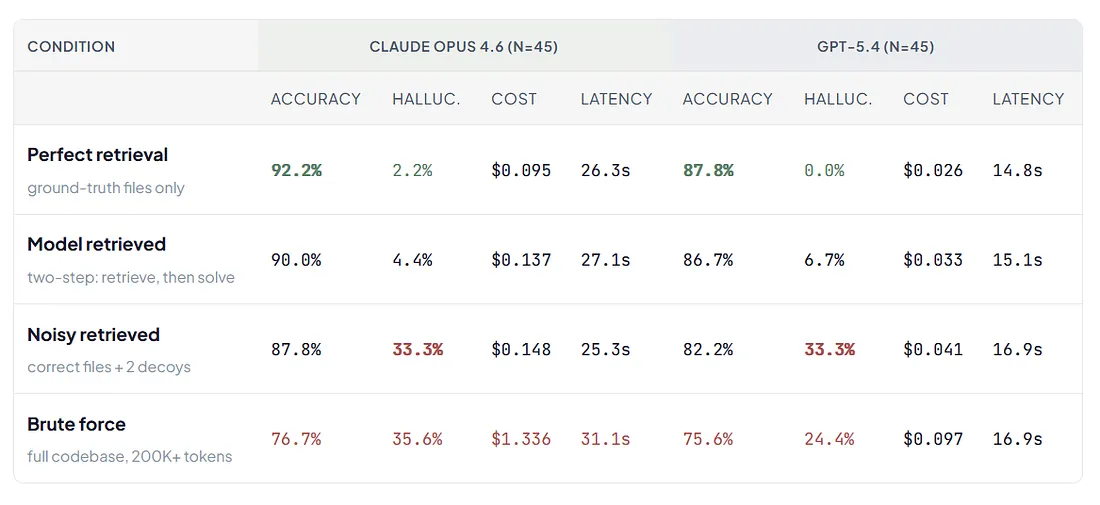
Source: our experiment 2 retrieval ablation (15 tasks × 4 conditions × 2 models × 3 reps = 360 calls). Accuracy = weighted correctness (mean(score)/2 × 100). Data: our internal EXP2 retrieval-ablation dataset (n=360, available on request).
Two things to notice. The accuracy spread between conditions is modest (~15pp for Opus, ~12pp for GPT-5.4) — engineered context wins, but not by orders of magnitude on accuracy alone. The hallucination spread is dramatic: from 2.2% (Opus perfect) to 35.6% (Opus brute force), a 16× jump. And the noisy-retrieved condition tells the cleanest story in the table: at one-tenth the tokens of brute-force, the model picks correctly — then we add two decoy files. Hallucination spikes from ~3% to ~33% on both models. Cost is what scales with tokens; hallucination scales with the plausibility of the noise. The decoy effect is the bigger threat in production: nobody is going to dump their entire codebase into context on purpose, but plenty of retrieval pipelines silently fetch one or two adjacent files alongside the correct ones.
Morph, a context compression company whose analysis should be read with that interest in mind, reported that SWE-rebench (a SWE-bench variant) maintainers found models hit a clear performance ceiling around 1 million tokens regardless of what the context window technically supports.[12] Beyond that point, more context doesn’t plateau; it actively degrades. Claude Code achieves equivalent results with 5.5× fewer tokens than competing tools, primarily through better context management.[12]
For coding agents, the bottleneck isn’t model intelligence — it’s what you put in front of the model. Our audited row-backed data says this more bluntly than the published literature: in EXP2 (n=360), perfect retrieval hallucinates at ~1% vs ~30% for brute-force loading of the full codebase; in EXP4 (n=144), targeted loading averages 88.5% accuracy at $0.060/call versus full-context’s 80.2% at $1.207/call — roughly 20× less cost for higher accuracy and a hallucination rate less than a third of compressed context’s. Different mechanisms, same direction: what you put in the window matters more than how much you fit.
Why Models Are Trained on Small Windows (And Why That’s Smart)
If long context windows degrade performance at inference time, a natural question follows: why not train models on longer sequences so they learn to handle them better?
Labs tried. The models got worse.
The Quadratic Wall
The self-attention mechanism — the thing that lets transformers relate any token to any other token — scales quadratically with sequence length. Every token attends to every other token, so double the sequence and you quadruple the attention compute. At small scales this is fine; at 2K tokens it’s basically free. But the math gets ugly fast. Going from 2K to 1M tokens means roughly 250,000× more attention compute.[7] That’s not a typo, and it’s not fixable with better hardware — it’s the fundamental scaling law of the architecture.
Moore’s Law won’t fix this. It’s a mathematical property of how transformers compute relationships between tokens. Every token attends to every other token, and the cost of that attention grows as the square of the sequence length. Architectural optimizations like FlashAttention, ring attention, and grouped-query attention reduce the constant factor, but they don’t change the fundamental scaling law.
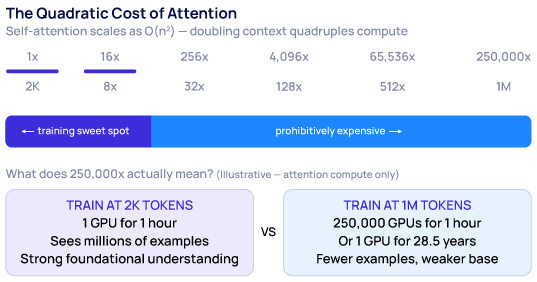
Self-attention cost scales quadratically. Labs train short first because it produces better models at a lower cost. Long context is added as a thin final extension.[4][7]
Short Windows Produce Better Models
SkyLadder, published at NeurIPS 2025, produced a finding that surprised a lot of people: models pretrained with shorter context windows consistently outperform their long-context counterparts under a fixed compute budget.[4]
In controlled experiments with 1 billion parameter models trained on 100 billion tokens, increasing the context window during pre-training degraded performance on standard benchmarks. The reason is straightforward: with a fixed compute budget, longer sequences mean fewer training steps and fewer unique examples seen. The model gets marginally better at attending to long ranges but substantially worse at the foundational language understanding that matters for most tasks. Long context doesn’t create better models. It dilutes them.
SkyLadder demonstrated up to 3.7% gains on common benchmarks and 22% faster training speeds by starting with short sequences and progressively extending them — a curriculum approach.[4]
The Curriculum Strategy
Instead of training on long contexts from the start, the industry has converged on a staged approach:

Two additional factors reinforce this strategy. First, there simply isn’t enough naturally occurring high-quality training data at very long sequence lengths. Most web documents, articles, and code files are well under 8K tokens. Training on million-token sequences requires either concatenating many short documents — creating artificial boundaries — or generating synthetic data that introduces distributional biases.
Second, the memory requirements are staggering. For a 300K-token input on Llama 3 70B, the KV cache alone consumes approximately 93 GB of GPU memory — more than an entire H100’s 80 GB capacity.[12] Long-context training doesn’t just cost more compute. It requires fundamentally different infrastructure.
The punchline for practitioners: every model you use today was trained on short contexts first — because that produces better models. Long context was bolted on afterward, as a thin extension on a foundation built on a small scale. That’s why the effective window falls so far short of the spec sheet. The foundation was never designed for it.
The Real Numbers: Advertised vs. Effective Context
Bringing together the evidence from LOCA-bench, Chroma, Paulsen, and the RULER benchmark, a clear picture emerges of just how wide the gap is between what models advertise and what they can actually use.[1][2][13][5]
In practice:
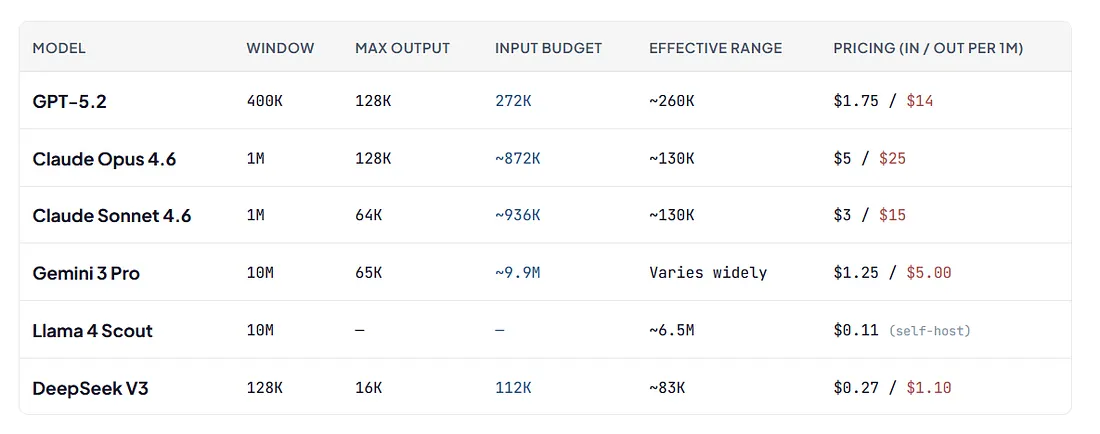
Pricing snapshot as of April 2026 — verify against current provider docs before relying on these numbers. Estimates synthesized from: RULER benchmark[5] Paulsen (2025)[13] Morph (2026)[12] — effective ranges are approximate and task-dependent. Claude Opus 4.6 has long-context premium pricing for prompts above 200K tokens; the figures above reflect standard-rate pricing.
Rough rule of thumb across model families: 60–70% of the advertised maximum for simple retrieval tasks. For complex reasoning and multi-step tasks — the work that actually matters — Paulsen’s research shows the effective window can collapse to as little as 1–2% of the advertised capacity.[13]
And remember: the “Input Budget” column in the table above is the theoretical maximum — before the model reserves space for its own output. A model with a 200K window and 64K max output only has 136K tokens for your input. After system prompts, MCP tools, and conversation history consume their share, the actual space available for your task context may be a fraction of that. The headline context window number is, at best, a ceiling you’ll never reach.
On the MRCR v2 multi-needle retrieval benchmark — a harder test than standard NIAH — even the best-performing model drops from ~92% at 256K tokens to ~78% at 1M. Others collapse far more dramatically: GPT-5.4 — a later variant in OpenAI’s lineup — falls from ~80% to ~37%, and some models barely cross 20% at maximum context.[5]
And then there’s the cost. As an illustrative pricing model — not a measurement from our experiments — consider Anthropic’s listed March 2026 pricing: the full 1M context window at standard rates ($5 per million input tokens, $25 per million output tokens), no surcharge for long contexts. That makes brute-force approaches cheaper than before, but the waste is still enormous on paper. A single 500K-token session costs $2.50 in input alone; add a typical 50K of output at $25/1M ($1.25) and the per-session cost reaches $3.75. Scale that to a team: 10 developers running 20 agent sessions per day — that’s 50,000 sessions per year at $3.75 each, totaling approximately $187,000 per year. The same workload with engineered context averaging 30K input tokens and 10K output per session costs $0.40 per session — approximately $20,000 per year. The implied ~9× cost reduction is a back-of-envelope calculation from public token pricing, not a measurement from our experiments.
(Inputs to this calculation: vendor list pricing as of March 2026, plus assumed session counts and token mixes. Our row-backed cost evidence comes from EXP2 and EXP4 only and is reported in those finding sections; the figures above should be read as an order-of-magnitude pricing sketch teams can re-run with their own usage data.)
What Actually Works: Context Engineering
If the problem is what goes into the context window; the solution isn’t a bigger window. It’s a disciplined approach to what you include, where you place it, and when you remove it.
Anthropic laid the groundwork in their guide on building effective agents,[8] then made the token-level implications explicit in a September 2025 blog post: “Context must be treated as a finite resource with diminishing marginal returns.”[17] The practice they describe — context engineering — is turning out to be the skill that separates teams shipping reliable AI from teams burning tokens.
Every effective strategy shares one goal: to reduce entropy before the model sees it.
The Seven Strategies That Work
Subagent isolation
If you only adopt one pattern from this article, make it this one. Instead of running everything in one context window, spawn specialized subagents — each with its own clean context and targeted tool permissions. A search subagent reads many files and returns only the relevant results. A coding subagent gets the precise context it needs for the current change. The parent conversation stays clean. The implementation details vary across frameworks, but the principle is universal.[8][12]
Targeted retrieval over brute-force loading
Instead of loading entire files, retrieve specific functions, line ranges, and diffs. When ten lines changed, send ten lines — not the entire 500-line file. A retrieve-then-solve approach improved Mistral’s accuracy from 35.5% to 66.7% by selecting relevant context rather than sending everything.[12]
Tool-result clearing
After the model has processed tool outputs (search results, file contents, API responses), proactively remove them from context. The LOCA-bench researchers found that this strategy alone contributed meaningful accuracy improvements — because the model no longer has to attend through stale exploration results to find current information.[1]
Proactive compression
Don’t wait until you hit the token limit to compact context. Run compression early and often. CompLLM research demonstrated that 2× compressed context actually surpasses uncompressed performance on long sequences — because removing noise improves the signal-to-noise ratio of what remains.[12]
Project-level context documents
You’ve probably seen these proliferate in your repos already — CLAUDE.md, AGENTS.md, .cursorrules, copilot-instructions.md, GEMINI.md. Different names, same idea: a markdown file the agent reads at session start, loaded with your coding standards, build commands, architectural constraints, and known gotchas. The industry is converging on AGENTS.md as the shared standard (it’s now under the Linux Foundation), with teams symlinking to tool-specific filenames. Why it works: this context loads at the beginning of the window, which is the strongest attention position. Front-load what matters most.[12]
Progressive disclosure and skills architecture
Instead of loading all tool definitions upfront (the MCP tax problem), use lazy-loaded capabilities. The Skills pattern loads only a name and description (~100 tokens per skill) at startup, then pulls full instructions into context only when relevant. The pattern is now showing up across the major coding-agent platforms named earlier — Claude, OpenAI, GitHub Copilot, LangChain. The reduction is dramatic — 95%+ less context overhead versus loading everything up front. If you’re running MCP servers, this is the difference between 80K+ tokens of idle schema and roughly 2K tokens of lightweight discovery metadata.
Multi-agent architecture — distribute context, not just work
There’s a reason every major agentic framework in 2026 — CrewAI, LangGraph, Google ADK, OpenAI’s Agents SDK, Microsoft’s Agent Framework, Claude’s subagents and Agent Teams — converges on multi-agent patterns. It’s not primarily about parallelism or specialization. It’s about context windows.
A single agent trying to handle research, coding, testing, and deployment carries everything in one context window: the system prompt grows to cover every capability, tool definitions multiply, and conversation history from every phase accumulates. By the time the agent reaches the critical decision — should I deploy this? — it’s operating on a context that’s 80% stale exploration traces from three phases ago. In our experience, once a single agent carries more than ~15 tools, context overhead and tool-selection errors become noticeably more common.
Multi-agent architectures solve this by giving each agent its own clean context. A search agent reads fifty files and returns a two-paragraph summary. A coding agent receives only the relevant functions and the specific task. A review agent gets the diff and the test results — not the entire exploration history. Each agent’s system prompt is small and specialized: “You are a code reviewer. Here are the changed files. Flag issues.” Not a 5,000-token mega-prompt trying to cover every scenario.
The providers have figured this out. Anthropic, Google, and OpenAI all explicitly frame multi-agent as a context management strategy in their documentation — not just a scaling pattern.[17] The implementations look different on the surface (subagents, agent trees, handoffs, crews) but underneath they’re all doing the same thing: giving each worker a clean window, a focused prompt, and returning only a distilled summary to the coordinator. Google’s ADK team says it plainly: just giving agents more context space “cannot be the single scaling strategy.”[8]
That’s the thing that doesn’t get said enough about the multi-agent trend: the underlying motivation is context hygiene, not smarter or faster agents. Crews, graphs, agent trees, subagents — different vocabulary, same underlying fix. A single context window degrades under load, so you split the load across multiple clean ones.
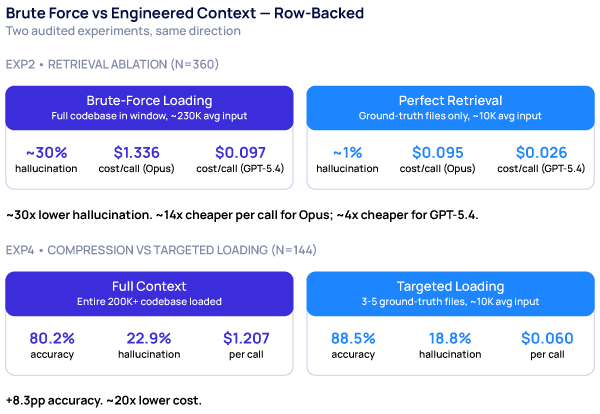
Two audited row-backed comparisons. EXP2 averages over Opus and GPT-5.4 (45 reps per model × condition cell). EXP4 averages over Opus, Sonnet, and GPT-5.4 (16 reps per model × condition cell, Gemini excluded per brief). Both point the same direction: a curated context window outperforms a full one on every dimension we measured. Source: our experiments 2 and 4, April 2026.

Respecting the MECW
Paulsen’s Maximum Effective Context Window research provides an actionable framework for calibrating these strategies. Rather than treating every model’s context window as a single number, teams should empirically measure the MECW for their specific model-task pipeline — and enforce per-agent token budgets that stay within it.[13]
This applies to RAG as well. Paulsen’s data showed that retrieval-augmented generation reaches near-perfect accuracy when context stays within the MECW, but actively worsens performance when it exceeds that threshold.[13] More retrieved documents don’t mean better answers. It means more noise competing for attention with the documents that actually matter.

The principle: The models are already smart enough. The constraint is what you put in front of them. Context engineering — not bigger windows — is the highest-leverage investment a team can make.
The Road Ahead
So is it getting better? Yes — but not in the way the press releases suggest.
Test-Time Training
The most promising approach may be NVIDIA’s TTT-E2E (Test-Time Training, End-to-End), first submitted in December 2025.[6] Instead of holding all context in the attention window, TTT-E2E compresses long context into the model’s weights via next-token prediction during inference — effectively letting the model “learn” from its context rather than just reading it.
The results are significant: constant inference latency regardless of context length, with a 2.7× speedup over full attention at 128K tokens and a projected 35× speedup at 2M tokens.[6] More importantly, the researchers observed no performance wall across their experiments — a first for any long-context method. One trade-off worth noting: full attention still dramatically outperforms TTT-E2E on needle-in-a-haystack tasks, because compression into weights loses exact token-level detail. TTT-E2E excels at comprehension and gist, but may sacrifice precise retrieval — a relevant consideration for code-search workloads.
Hybrid Architectures
Full attention across all tokens is starting to look like a dead end. K-EXAONE (LG AI Research, January 2026) uses a 3:1 hybrid of global and sliding-window attention, cutting memory usage by 70%.[6] Megalodon achieves sub-linear perplexity scaling to 2 million tokens. State Space Models like Mamba process sequences in linear rather than quadratic time. Where this is heading: different parts of the context need different levels of attention. One-size-fits-all attention is giving way to hybrid architectures that mix mechanisms.
Compression as a Feature
This next finding genuinely changed how I think about context management: compressed context can outperform uncompressed context. CompLLM demonstrated that 2× compressed context surpasses full context on long sequences because removing noise improves the signal-to-noise ratio of what remains.[12] This validates the core argument of this article — and suggests that future systems will compress by default, not as a fallback.

Sources: TTT-E2E[6] Cerebras[7] Morph[12]
The Counterargument: Effective Context Is Improving
To be fair to the other side: models are getting better at using long context. Epoch AI’s analysis (June 2025) found that while frontier context windows have grown at roughly 30× per year, the input length at which top models maintain 80% accuracy has improved even faster — rising by over 250× in just nine months on benchmarks like Fiction.liveBench and MRCR.[14]
This is real progress. Worth acknowledging. But two caveats matter. First, the benchmarks measuring this improvement are still simpler than real production workloads — Paulsen’s research showed that complex reasoning tasks collapse at a fraction of the context length where retrieval tasks succeed.[13] Second, even as the effective window grows, the gap between signal-rich and signal-poor contexts remains the dominant factor in output quality. A model that can effectively use 500K tokens will still perform better with 5K tokens of focused signal than with 500K tokens of noise.
The argument doesn’t shift from “models can’t use long context” to “models can.” It shifts to: models use long context better with engineering, and that advantage persists even as raw capability improves.
The Industry Is Starting to Agree
The strongest signal that the industry is converging on the context-engineering thesis is that providers are emphasizing usable long-context reasoning over raw window size. OpenAI’s GPT-5.2 ships with a 400,000-token context window and a 128,000-token max output, and the surrounding documentation foregrounds long-context reasoning workflows rather than headline window numbers. The cap on the input side is what it is; the signaling around it is different from a few years ago, when “bigger window” was the story.
What Needs to Change
Paulsen’s research makes a pointed recommendation: model providers should report both the Maximum Context Window and the Maximum Effective Context Window for standard task types.[13] Until that happens, the gap between marketing and reality will continue to cost teams time and money. Practitioners should treat any advertised context window as a ceiling, not a guarantee — and empirically measure the effective limit for their specific workloads.
The Bottom Line
We started with a question: your model can see your entire codebase — so why does it keep suggesting functions that don’t exist?
The answer, across the broader published literature and our own audited row-backed evidence, is not that long context is broken. Is it that a larger context window does not automatically become a larger reasoning window? The window holds the tokens; what determines reliability is what you put in it and what you keep out.
Across 1,296 audited solve runs in our experiments, four patterns held up. Context size raised hallucination pressure without producing a clean universal accuracy collapse on frontier models. Retrieval quality dominated raw context volume: perfect retrieval hallucinated at ~1%, brute-force loading at ~30%. Inline related distractors did far more damage than file-level padding (GPT-5.4 dropped 31pp when similar code was injected directly into the signal file). Targeted full-file context beat full-codebase and compressed context for code on every dimension that mattered — 88.5% vs 68.8% accuracy, 18.8% vs 54.2% hallucination, at roughly 20× lower cost. Different mechanisms, one direction: the engineering lever is context management, not context size.
Here’s where it all lands:
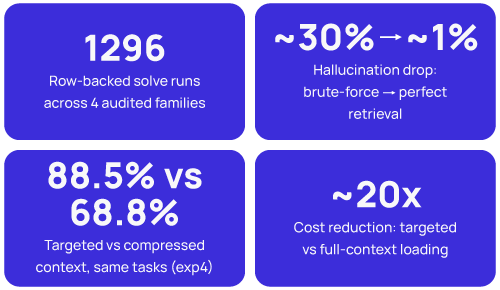
Sources: our EXP1 (n=600), EXP2 (n=360), EXP3 (n=192), EXP4 (n=144); raw JSONL on request.
So the engineering response writes itself:
Retrieve fewer, better files.
A handful of correct files beats a full-codebase dump on both accuracy and cost, every time we tested it. Treat retrieval quality as a first-class engineering target, not a downstream concern.
Keep exact code identifiers; don’t compress them away.
Compression preserves enough surface structure that the model will happily generate against the summarized codebase — and invent function names that don’t exist. For code, summaries are not lossless on the dimension that matters.
Avoid inline related distractors.
File-level padding (similar or unrelated) is mostly within noise on flagship models. Similar code injected inside the file the model is supposed to reason over is the failure mode: it corrupts the diagnosis by competing for identity with the real task.
Treat the context window as a budget to curate, not a bucket to fill.
Bigger windows let you fit more in. They don’t tell you what should be in. That’s still an engineering decision, and on the evidence we have, it’s the decision that dominates.
Your system isn’t failing because the model is weak.
It’s failing because nobody is managing what goes into the context window. Treat context as a finite resource you curate, not a bucket you fill. Measure your model’s actual limits on the tasks you actually run. The models are good enough. The context isn’t — until you make it so.

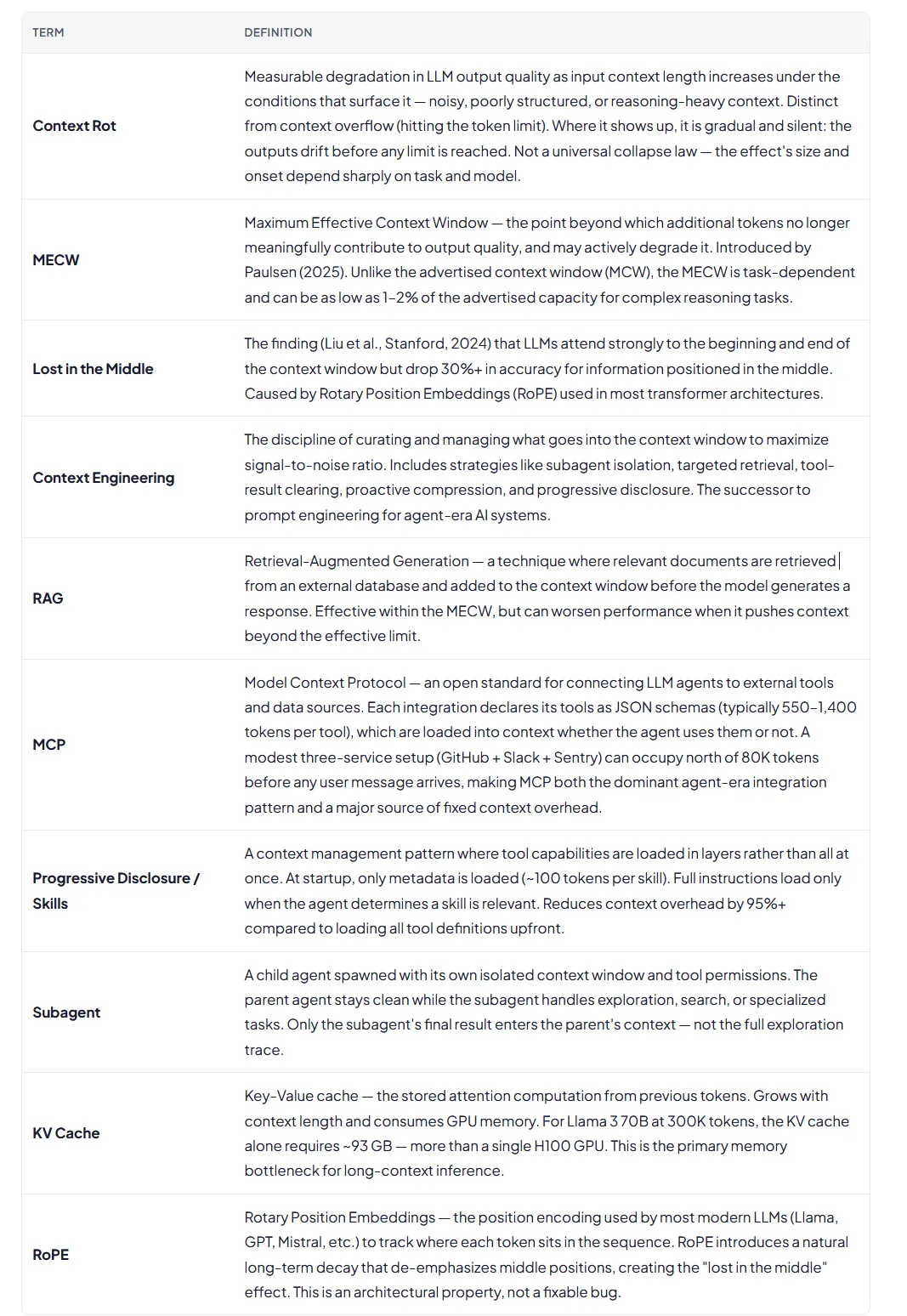
Appendix: Glossary of Context Window Terms
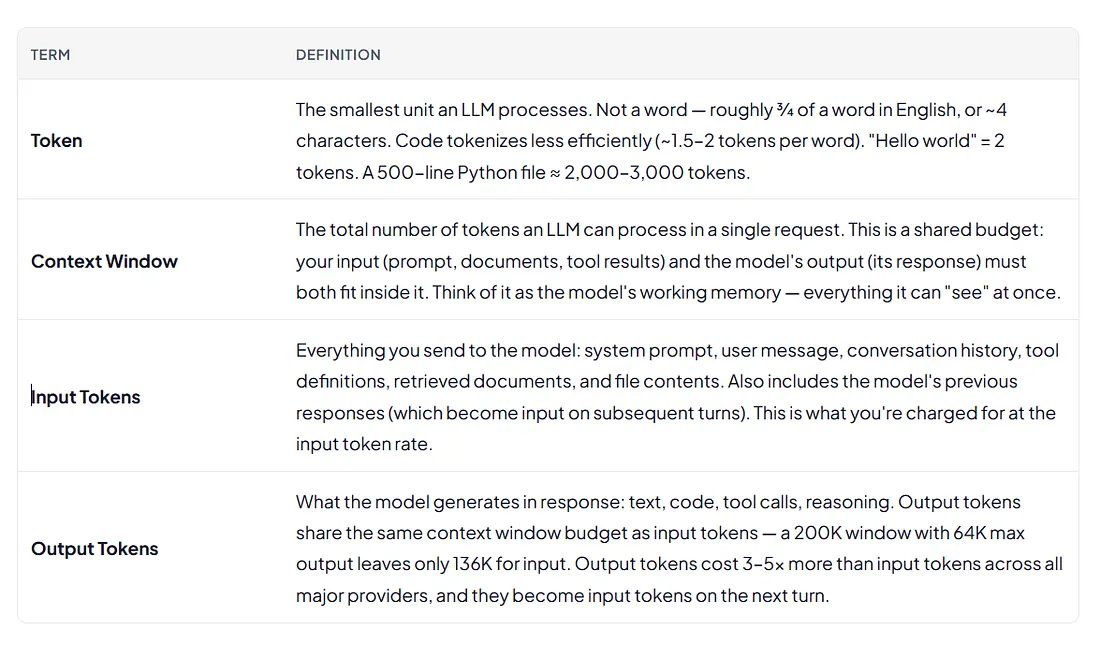
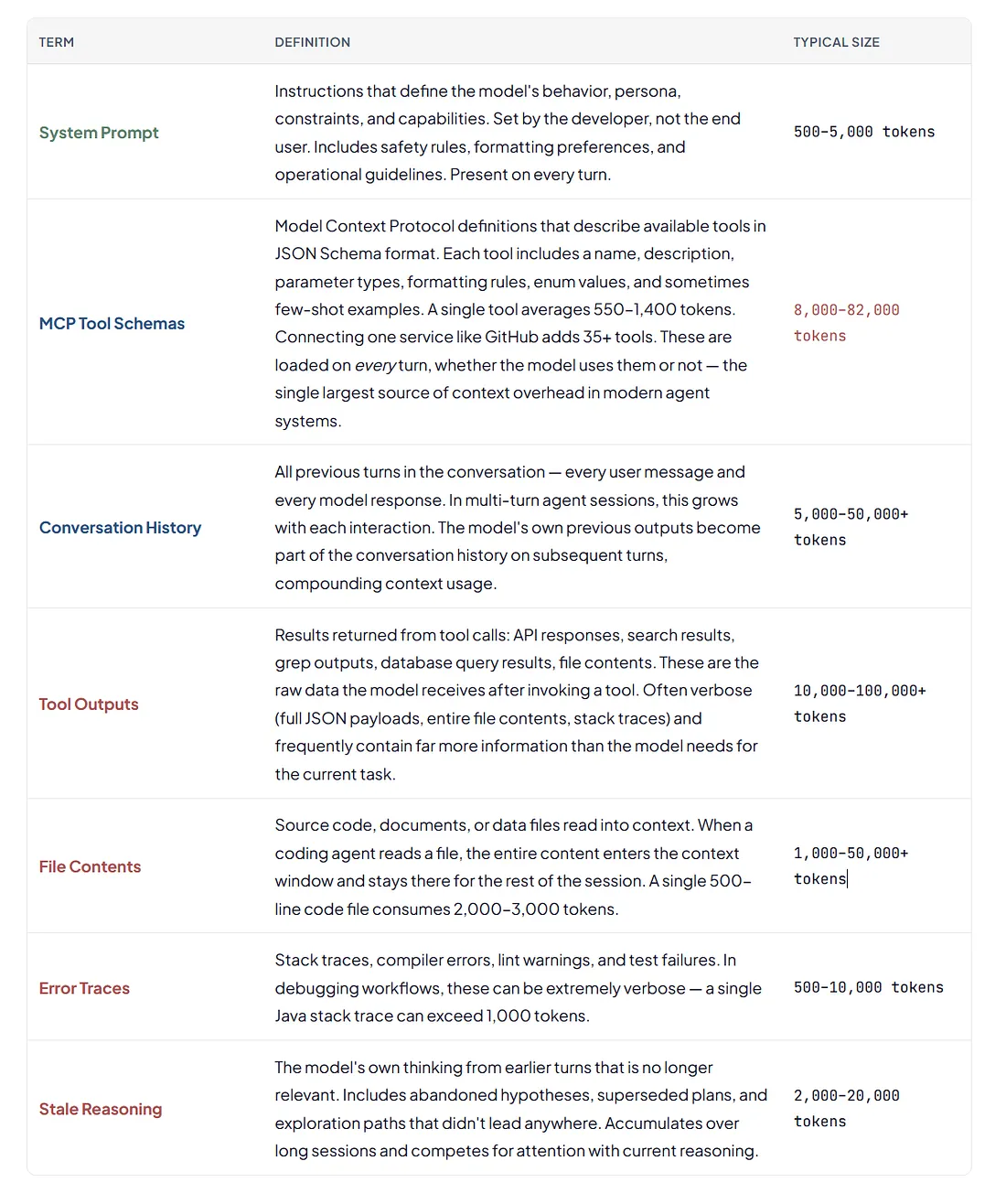
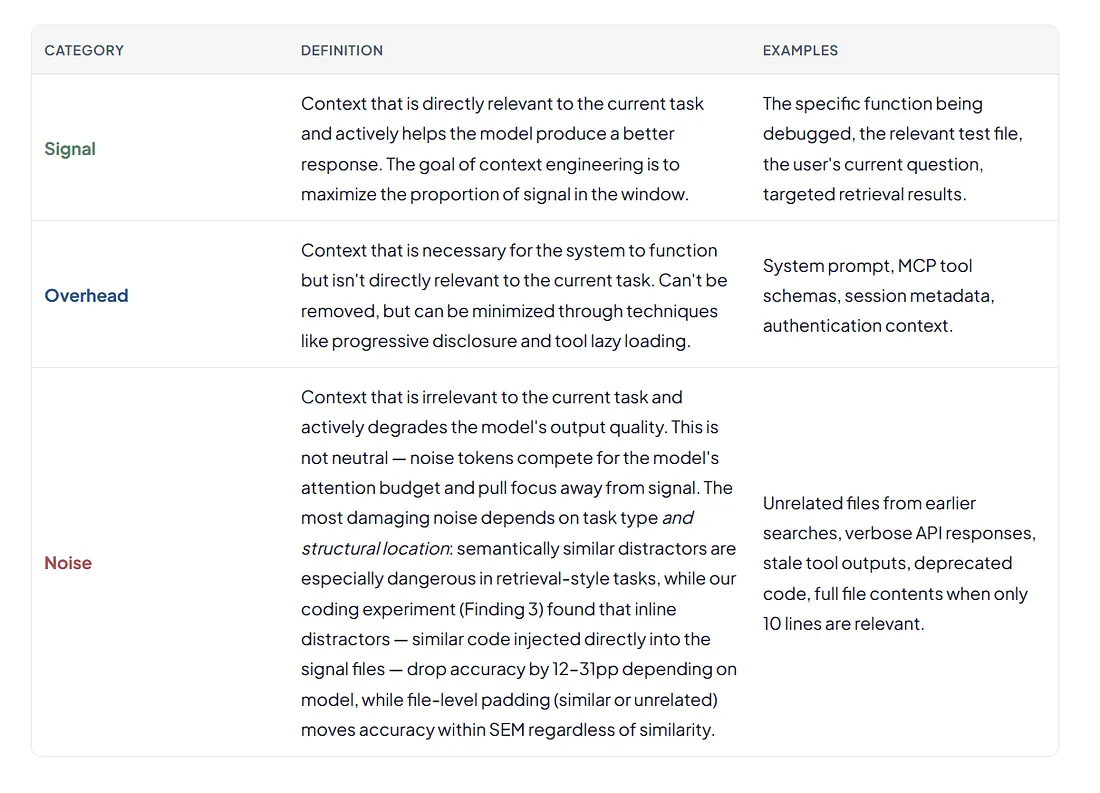
The terms below are used throughout this article and in the “What Occupies the Context Window” visual. They’re organized by category to help readers unfamiliar with LLM internals follow the argument.
Fundamentals
What Goes Into the Window
Context Quality Categories
Key Concepts
Appendix A: Our Experimental Setup
For readers who want to interrogate our numbers directly. All experiments run on a pinned application subset of a production codebase — a mid-sized internal web application with backend services and a browser-based frontend. The released tasks.json records the larger repository’s metadata at the pinned commit SHA (file count in the tens of thousands; token count in the tens of millions). The experiments themselves draw on a curated ~400-file application subset; prompt construction uses padding from that subset plus unrelated open-source padding files. Temperature 0 across all runs. LLM-as-judge scoring with a 216-row manual re-scoring validation sample. Code identifiers in quoted examples have been anonymized for publication; relative semantics (which identifiers are real vs. hallucinated) are preserved. Row-level JSONL logs are available on request.
Raw model evaluation, not deployed-system evaluation. Every run in this article is a single direct API call against the provider endpoint with a fully constructed prompt. No agentic harness was in the loop: no tool use, no sub-agent routing, no mid-task compaction or summarization, no skill packs, no CLAUDE.md-style instruction scaffolding, no live retrieval pipeline, no scratchpad or memory layer. EXP2’s four retrieval conditions are simulated retriever outputs at pre-defined quality levels (perfect / model-retrieved / noisy-retrieved / brute-force), not the output of a running retriever. This frame is intentional: it isolates raw model behavior on the context it’s handed, which is the variable Findings 1–4 are about. Every accuracy and hallucination number in this article should be read as a floor on what a well-engineered harness (Claude Code, Cursor, an internal RAG agent, etc.) would produce on the same tasks — a harness exists precisely to do better than this baseline. Conversely, the four findings double as the four classes of problem any production harness has to solve: context-size hallucination pressure, retrieval-quality dependence, inline-distractor sensitivity, and identifier-preservation under compression.
Model naming. The raw-log API string is google/gemini-3.1-pro-preview and that is the canonical identifier used throughout this article. Provider-side preview versioning resolved API calls to the dated build google/gemini-3.1-pro-preview-20260219 during our test window; the raw-log API string is what the article uses for model identification. Model strings for the other three models are listed above.
Statistical note. All reported intervals are 95% Wilson score intervals on binomial rates (correctness and hallucination are discretized to binary for interval calculations: correctness ≥ 1 or = 2; hallucination ≥ 1). Sample sizes per audited experiment: n=30 per (model × size) cell in EXP1 (4 models × 5 sizes × 30 = 600 rows); n=45 per (model × condition) cell in EXP2 (2 models × 4 conditions × 45 = 360 rows); n=16 per (model × condition) cell in EXP3 (3 models × 4 conditions × 16 = 192 rows); n=16 per (model × condition) cell in EXP4 (3 models × 3 conditions × 16 = 144 rows). Where individual-point CIs overlap, we rely on trend direction across multiple conditions and cross-model consistency as evidence rather than single-cell comparisons. Fully certified effect sizes would require ~10× our sample.
Accuracy rubric note. We report three related metrics. Strict full credit counts only rows with correctness = 2. Weighted correctness computes mean(correctness score) / 2 × 100 and is the headline prose metric unless otherwise stated. At least partial counts rows with correctness ≥ 1. Gemini 3.1 Pro Preview in EXP1 illustrates why the distinction matters: it scores 0–7% strict, 37–45% weighted correctness, and 73–83% at-least-partial. That means Gemini often identified the general area but failed to produce a complete, correct fix. For the other three EXP1 models, the three metrics converge near the top of the scale at small context sizes; the strict rubric is plotted on Fig 1 because it shows the clearest degradation signal across the logged range.
Known limitations. Single-codebase generalization: findings may be repo-specific; replication on other codebases would strengthen Finding 3 (distractors) in particular. Gemini coverage is limited to Gemini 3.1 Pro Preview as it stood in our test window — whether production Gemini 3.1 Pro (post-Preview) closes the gap on coding tasks is an open question. LLM-as-judge introduces minor circularity, which we partially mitigated via a 216-row manual validation sample; we did not compute a rolling inter-rater agreement statistic, so we do not claim a specific agreement rate. EXP2 did not find the clean S/N threshold we hypothesized on frontier models; we report this as a null result in the “What didn’t hold up” section above rather than hiding it.
References
- Zeng, W., Huang, Y., & He, J. (2026). “LOCA-bench: Benchmarking Language Agents Under Controllable and Extreme Context Growth.” arXiv:2602.07962. Link
- Hong, K. et al. (2025). “Context Rot: How Increasing Input Tokens Impacts LLM Performance.” Chroma Research. Link
- Liu, N. F. et al. (2024). “Lost in the Middle: How Language Models Use Long Contexts.” TACL, Stanford. Link
- Zhu, T. et al. (2025). “SkyLadder: Better and Faster Pretraining via Context Window Scheduling.” NeurIPS 2025. Link
- Hsieh, C.-P. et al. (2024). “RULER: What’s the Real Context Size of Your Long-Context Language Models?” COLM 2024.
- Sun, Y. et al. (2025). “TTT-E2E: Reimagining LLM Memory Using Context as Training Data.” arXiv:2512.23675. NVIDIA Research. Link
- Cerebras (2025). “Variable Sequence Length Training for Long-Context Large Language Models.” Link
- Anthropic (2025). “Building Effective Agents.” Anthropic Blog. Link
- ai (2025). “The Context Window Problem: Scaling Agents Beyond Token Limits.” Link
- Augment Code (2025). “Context Window Wars: 200K vs 1M+ Token Strategies.” Link
- Veseli, B. et al. (2025). “Positional Biases Shift as Inputs Approach Context Window Limits.” arXiv:2508.07479. August 2025.
- Morph (2026). “Context Engineering: Why More Tokens Makes Agents Worse.” Link
- Paulsen, N. (2025). “Context Is What You Need: The Maximum Effective Context Window for Real World Limits of LLMs.” Advances in Artificial Intelligence and Machine Learning, 2026. arXiv:2509.21361. Link
- Burnham, J. & Adamczewski, T. (2025). “LLMs Now Accept Longer Inputs, and the Best Models Can Use Them More Effectively.” Epoch AI Data Insights, June 2025. Link
- Hosseini, P. et al. (2025). “Efficient Solutions For An Intriguing Failure of LLMs: Long Context Window Does Not Mean LLMs Can Analyze Long Sequences Flawlessly.” COLING 2025.
- Anthropic (2025). “Code Execution with MCP: Building More Efficient AI Agents.” Anthropic Engineering Blog. Link. The 98.7% context reduction figure is widely cited from analysis of this approach; see also Prashant, M. (2025), “Scaling Agents with Code Execution and the Model Context Protocol.”
- Anthropic (2025). “Effective Context Engineering for AI Agents.” Anthropic Engineering Blog, September 2025. Link
- Hakim, M.A. (2026). “Brevity Constraints Reverse Performance Hierarchies in Language Models.” arXiv preprint, arXiv:2604.00025, March 2026. Link


















