A maturity framework for engineering leaders navigating the shift from AI-assisted coding to governed autonomous software production

Fig 1: The DRD continuum — from fully manual engineering (Level 0) to governed autonomous operation (Level 5)

Artificial intelligence (AI) is reshaping software engineering at a fundamental level — not just by making individual developers faster, but by changing who, or what, does the implementation work at all. If you’re a CTO, VP of Engineering, or senior architect, you’re already navigating this shift. The challenge isn’t whether to adopt AI tools. It’s knowing what “good” looks like at each stage of adoption, and what governance architecture you need to get there safely.
This paper introduces Dark Room Development (DRD) — a strategic maturity framework defining a six-level continuum from fully manual development to AI-enabled autonomous software systems. The name comes from lights-out manufacturing: industrial facilities that run with minimal human presence on the floor, not because they’re ungoverned, but because governance and quality assurance are embedded in the production infrastructure itself. DRD applies that same logic to software engineering. The name signals that governance is embedded in the infrastructure, not that humans have left the room.
A DRD-mature environment isn’t one where humans have withdrawn accountability — it’s one where specification precision, validation infrastructure, and governance automation are sufficiently mature that autonomous execution becomes safe and auditable. Human authority is never removed. It’s elevated — from execution to design, oversight, and governance of intelligent production systems.
The Evidence Is Clear — and Complicated
The case for AI in software engineering is well-supported by controlled research. Across independent randomized controlled trials, AI tools show meaningful productivity gains:

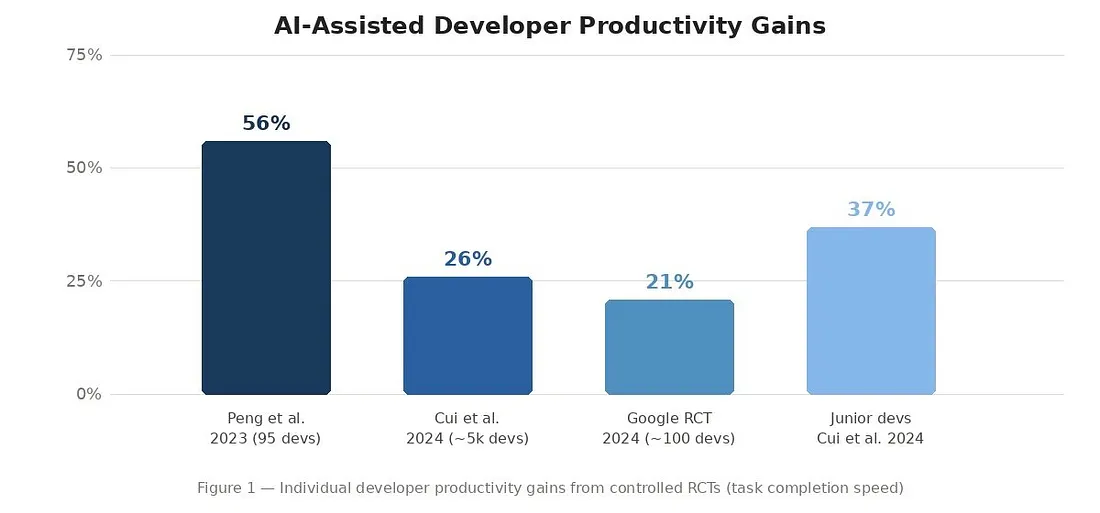
Figure 1 — Individual developer productivity gains from controlled randomized controlled trials (RCTs). Note the range: 21–56% at the individual level — yet system-level delivery gains remain elusive. All findings: Observed
But here’s the problem. Faros AI’s 2025 analysis documented something the authors of this paper call the AI Productivity Paradox: while 75% of engineers now use AI tools — a figure broadly consistent with Stack Overflow’s Developer Survey — most organizations report no measurable improvement in delivery performance at the system level. Individual gains are getting absorbed by cross-team dependencies and integration bottlenecks. Observed
The implication for engineering leaders is direct: AI tooling alone doesn’t produce system-level performance gains. Structural transformation — in workflow design, specification discipline, and governance — is required to convert individual productivity into organizational throughput. The Faros Paradox is, in DRD terms, the consequence of organizations operating at Level 1–2 tooling maturity while retaining Level 0 workflow and governance structures.
The broader transition to autonomous agents is also accelerating. Gartner projects that by 2028, 33% of enterprise software applications will include agentic AI capabilities, up from less than 1% in 2024. Projected Deloitte estimates 50% of companies using generative AI will deploy autonomous agents by 2027. Projected LangChain’s 2024 State of AI Agents survey corroborates the momentum from the developer tooling side. These are directional indicators, not certainties — but they’re consistent across independent sources.
What the Research Actually Shows
Controlled Experiments
The productivity gains cited above come from peer-reviewed or independently published randomized controlled trials — the most rigorous evidence available. They measure individual developer productivity on bounded coding tasks. They don’t measure system-level delivery throughput, architectural quality, or long-term maintainability. That distinction matters enormously for how you interpret them.
Experience level shapes the results significantly. In the Cui et al. multi-company study, junior developers saw speed-ups of 35–39%, while senior engineers saw gains of 8–16%. AI tooling disproportionately lifts junior engineers, but it doesn’t replace senior architectural judgment — a finding with direct implications for how organizations should model talent evolution as they advance through DRD levels. Observed
Figure 2 — Productivity gain by experience level (Cui et al., 2024). Junior developers gain 35–39%; seniors gain 8–16% — AI lifts the floor more than the ceiling. Observed
What the Industry-scale Data Adds
Beyond individual productivity, a distinct evidence stream is now emerging from large-scale agentic deployment data. Anthropic’s February 2026 analysis — a first-party study, which readers should weigh accordingly — documented production agentic behavior across roughly 500,000 Claude Code sessions and approximately one million API tool calls.
- Autonomous session length is extending: The 99.9th percentile turn duration grew from under 25 minutes to over 45 minutes between October 2025 and January 2026. This means agentic autonomy is increasing in practice, not just in capability Observed
- Human oversight is shifting from approval-based to exception-based: Among new users, about 20% of sessions use full auto-approve. Among experienced users with 750 or more sessions, that rises to over 40%, while the interrupt rate simultaneously rises from 5% to about 9% of turns. Engineers don’t trust AI less as they gain experience; they check it differently. Observed
- Production agentic deployments today are predominantly supervised: Across Anthropic’s public API, 80% of agentic tool calls have at least one safeguard, 73% have a human in the loop, and only 0.8% of actions are irreversible. True autonomy-without-oversight remains rare in measured deployments — consistent with Level 3–4 operating patterns, not Level 5. Observed
Software engineering is, right now, the proving ground for agentic AI. Independent data from Jellyfish’s August 2025 analysis of engineering workflows corroborates this pattern, documenting measurable shifts in how engineering teams allocate time as agentic tooling matures — with review and validation cycles expanding to absorb the increased volume of AI-generated output.

The Economics Are Changing, Not Just the Tools
Traditional software cost estimation models — COCOMO II, SLIM, Function Point Analysis — are fundamentally labor-centric. Cost scales directly with human effort. DRD proposes a structural shift in this model as engineering autonomy increases.
Consider a representative feature: a customer notification preferences API with rule-based filtering logic, roughly 800 lines of production code with associated tests and documentation. The numbers below are illustrative — they show where cost gravity shifts, not a quantitative budget template. Illustrative
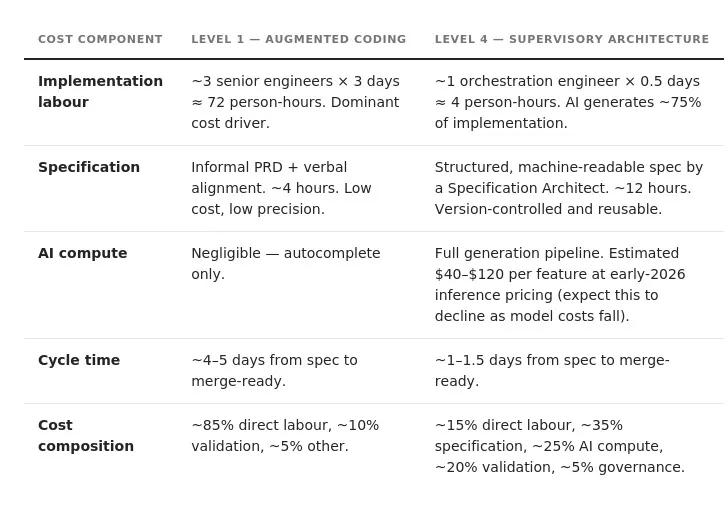
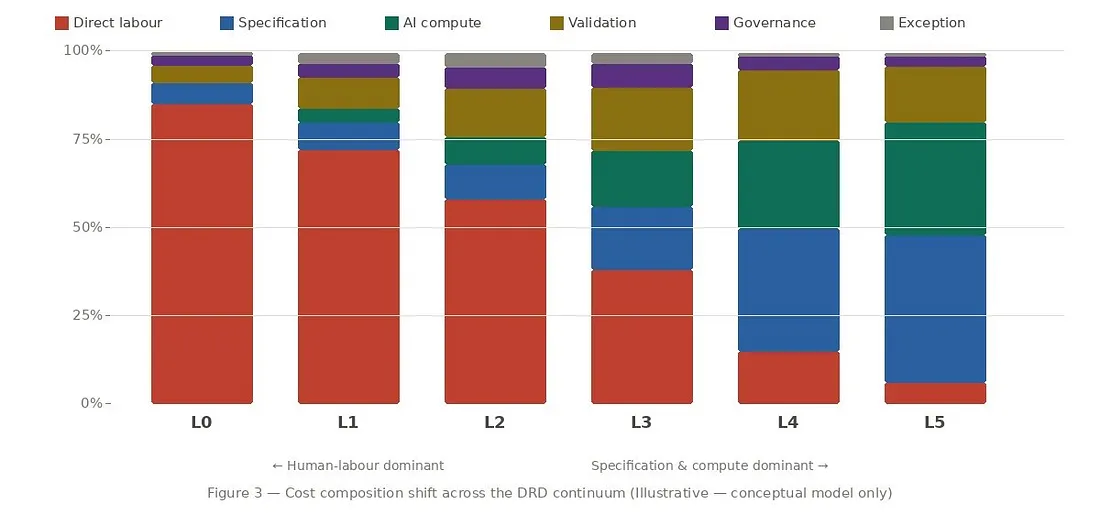
Figure 3 — Cost composition shift across the DRD continuum. Direct labor shrinks from ~85% to ~5%, but total cost redistributes into specification, AI compute, and validation — the economic advantage is throughput at scale, not lower absolute cost. Illustrative — conceptual model only.

At Level 4, direct labor cost per feature falls sharply — but total feature cost doesn’t disappear. It redistributes. Specification precision, AI compute, and validation infrastructure become the dominant inputs. The economic advantage of Level 4 isn’t lower absolute cost per feature in isolation — it’s throughput at scale. When the same specification infrastructure and validation pipeline serves ten or a hundred features, the fixed costs amortize and the marginal cost per feature falls substantially below Level 1.
The six levels
The Autonomous Engineering Continuum defines six levels of AI integration in software production. This is an original framework proposed by the authors of this paper — not an empirically validated industry standard. PROPOSED The levels are practical decision instruments for engineering leaders assessing the current state and planning transitions.
Each level below includes a disqualifying condition — the characteristic that means a team does not yet qualify for that level, even if they use AI tools.
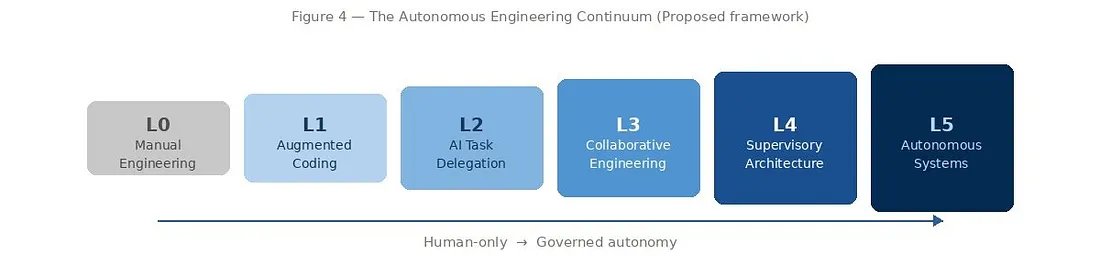
Figure 4 — The Autonomous Engineering Continuum. Each level has a disqualifying condition — the characteristic that means a team does not yet qualify, even if they use AI tools. PROPOSED framework.
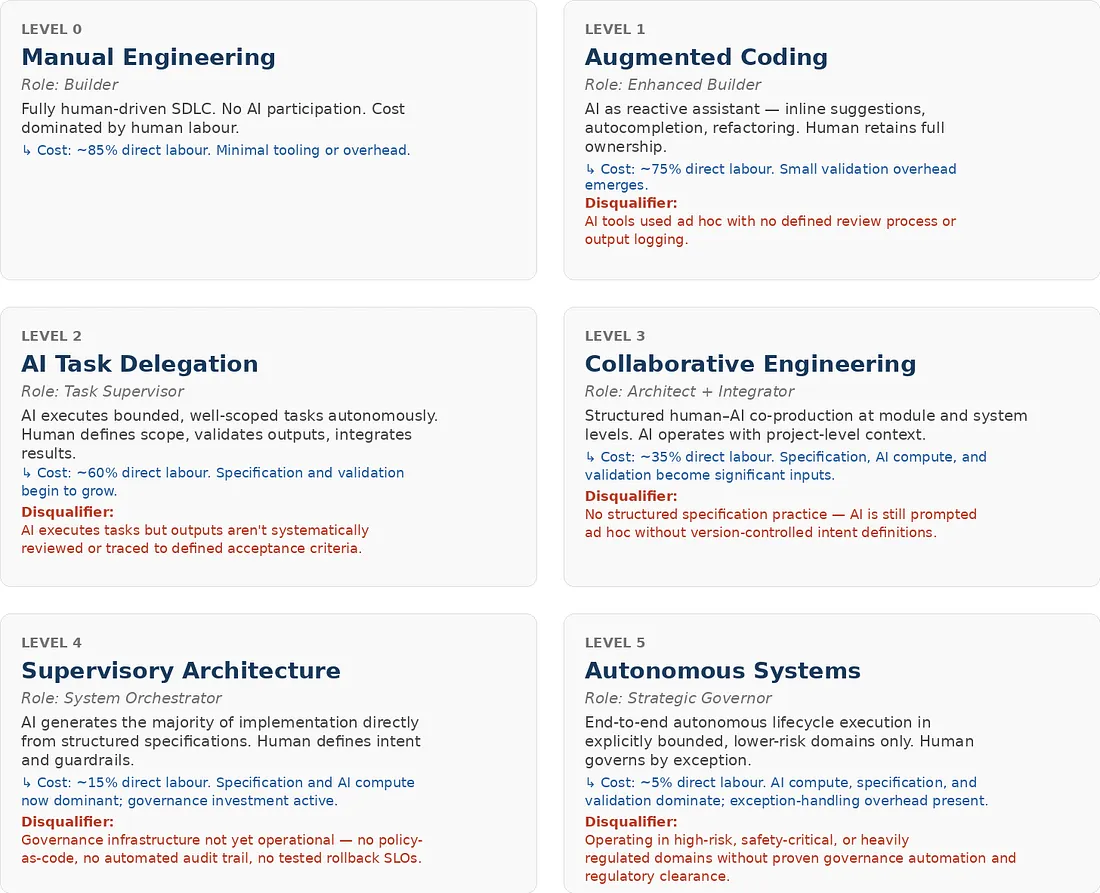
What Actually Distinguishes Adjacent Levels
The jump from Level 2 to Level 3 is not a question of which AI tool you’re using. It’s structural. At Level 2, AI executes discrete tasks from human-written prompts, with no persistent project context. At Level 3, AI operates with structured, version-controlled specifications as its primary input — not ad hoc prompts. The shift is from reactive assistance to specification-driven co-production.
The Level 3 to Level 4 transition is equally structural. At Level 3, humans still author the majority of architectural decisions and integration logic. At Level 4, AI generates the majority of implementation artifacts directly from formal specifications. The shift is from collaborative authoring to human-supervised AI generation with exception-based human correction.
Level 5 is different in kind from all others. At Level 4, humans approve releases and retain override authority at every decision point. At Level 5, the release and deployment pipeline is autonomous within policy-defined boundaries. The shift is from supervisory approval to governance-by-exception, and no organization has yet publicly documented a deployment that qualifies.
That said, the preconditions for Level 5 are becoming identifiable. Organizations approaching this threshold would exhibit several leading indicators: governance automation reliability consistently above 95% in a bounded domain; a specification architecture mature enough that AI-generated output passes acceptance criteria without human modification in the majority of cases; rollback infrastructure that has been triggered, tested, and recovered from in production — not just documented; and a regulatory posture that explicitly permits autonomous deployment in the target domain. The absence of any one of these signals means Level 5 is premature, regardless of how capable the underlying models are.
Specification Is the Gating Mechanism — Not Tooling
Organizations commonly interpret the Level 2 → Level 3 transition as a question of which AI tool to adopt. It isn’t. The same tool — even the same model — can operate at Level 1, 2, or 3 depending entirely on how its input is structured. The specification is the mechanism that converts reactive AI assistance into governed AI co-production.

A specification qualifies for DRD Level 3 and above if it satisfies all five of the following properties. The absence of any one reverts the interaction to Level 2 or below, regardless of the AI system used:
- Structured:Organized into defined, parseable fields: intent, scope boundaries, constraints, acceptance criteria, and context. Not free-form prose.
- Version-controlled: Stored in a version-control system with full history, authorship tracking, and review workflow — identical to source code.
- Machine-readable:Formatted so that it can be consumed directly by an AI-generation pipeline without human re-interpretation.
- Acceptance-criteria-bound: Specifies, in deterministic terms, what constitutes a correct output — test cases, behavioral assertions, performance bounds, security constraints — defined before generation begins.
- Refinable from output feedback: Defects in AI-generated outputs are traced back to the specification and used to improve it — not treated as one-off corrections.
What This Looks Like In Practice
The difference between a Level 1 prompt and a Level 3 specification is easier to show than to describe. Consider a feature request: add filtering to the notification preferences API.
Level 1 input (ad hoc prompt)
“Add a filter parameter to the GET /notifications/preferences endpoint. Users should be able to filter by channel type (email, SMS, push). Return 400 if the filter value is invalid.”
This is adequate for a human developer who can ask clarifying questions. For an AI-generation pipeline, it leaves critical decisions unspecified: What are the valid channel types — is the list hardcoded or database-driven? What does the response shape look like when filtered? How does this interact with pagination? What about authorization — can users only see their own preferences?
Level 3 specification (structured, version-controlled)
Feature: Notification preference filtering
Intent: Allow authenticated users to retrieve their notification preferences filtered by communication channel.
Endpoint: GET /api/v2/notifications/preferences?channel={channel_type}
Scope boundary: This feature modifies the query layer only. It does not alter the preference data model, the write path, or the notification dispatch pipeline.
Constraints: Valid channel types are defined in config/channels.yml (currently: email, sms, push, in_app). The source of truth is the config file, not a hardcoded enum. Filtering is case-insensitive. Multiple channel values are comma-separated.
Auth: Requires valid Bearer token. Users can only retrieve their own preferences (enforce via user_id from JWT claims). Return 403 if user_id mismatch.
Pagination: Filtered results respect existing cursor-based pagination contract (see specs/pagination-v2.md).
Acceptance criteria:
• GET with valid channel returns 200 + filtered results matching schema in schemas/preference-response.json
• GET with invalid channel returns 400 + error body per specs/error-contract.md
• GET without channel parameter returns unfiltered results (backward-compatible)
• GET with mismatched user_id returns 403
• Existing pagination tests pass unchanged
Spec version: 1.0 | Author: @spec-architect | Reviewed: @api-lead | Linked to: FEAT-4821
The difference is not verbosity — it’s precision. The Level 3 spec eliminates the ambiguity that forces AI to guess. It explicitly references existing system contracts (channels.yml, pagination-v2.md, error-contract.md) that the AI would otherwise need to discover in a codebase it can’t fully attend to. And crucially, it defines acceptance criteria before generation begins — making validation deterministic rather than subjective.
The specification is the mechanism that converts reactive AI assistance into governed AI co-production. The same tool — even the same model — can operate at Level 1, 2, or 3 depending entirely on how its input is structured.
The Specification Lifecycle
A specification isn’t a static document. In a DRD-mature organization, it’s a production artifact with its own lifecycle, analogous to source code. Intent gets captured by a Specification Architect. The spec goes through peer review before AI engagement begins. It gets committed to version control, linked to the feature or change record. AI consumes it as primary input. Generated artifacts are tested against the acceptance criteria in the spec. Failures are traced to specification gaps, not model errors to patch. The spec is refined, and the cycle repeats.
At Level 4 and above, generation, validation, and testing execute autonomously within governance policy. DRD doesn’t prescribe a specific format or tooling stack — the five properties above are format-agnostic.
How DRD Relates to Frameworks You Already Use
DRD doesn’t replace existing software engineering frameworks. It addresses a dimension none of them were designed to cover: the governance of AI as a production participant.
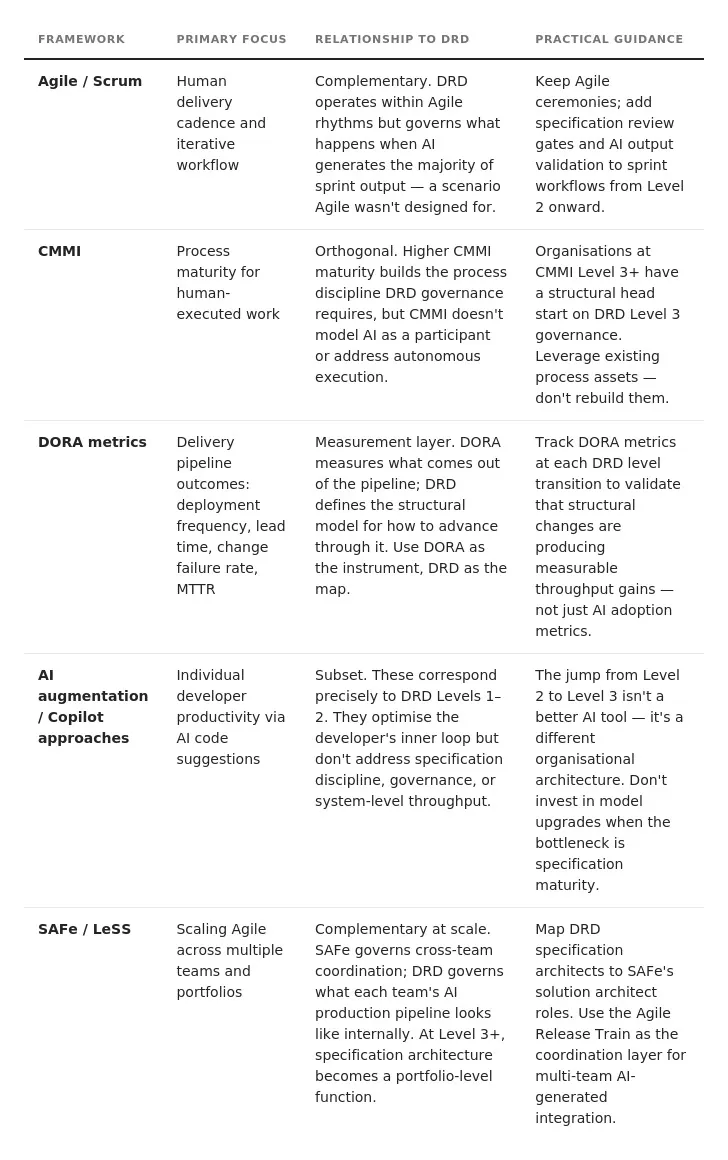

The practical takeaway: if you’re already running Agile sprints and tracking DORA metrics, don’t discard either. Use DORA as your measurement instrument and DRD as the structural model for what to change to move those metrics. If you’re at CMMI Level 3 or above, you have a head start on the process discipline DRD governance requires — leverage it rather than rebuilding it.
Governance Is Enabling Infrastructure, Not Compliance Overhead
As engineering autonomy increases, systemic risk exposure expands non-linearly. PROPOSED This is the dynamic the Dark Room name was chosen to capture: a lights-out production floor isn’t ungoverned — its governance is embedded so deeply in the infrastructure that the floor can operate safely without continuous human presence.
The organizations that treat governance as pure overhead will constrain their own autonomy ceiling. Those who treat it as enabling infrastructure will advance faster and more safely. Governance is what makes the dark room possible, not what limits it.
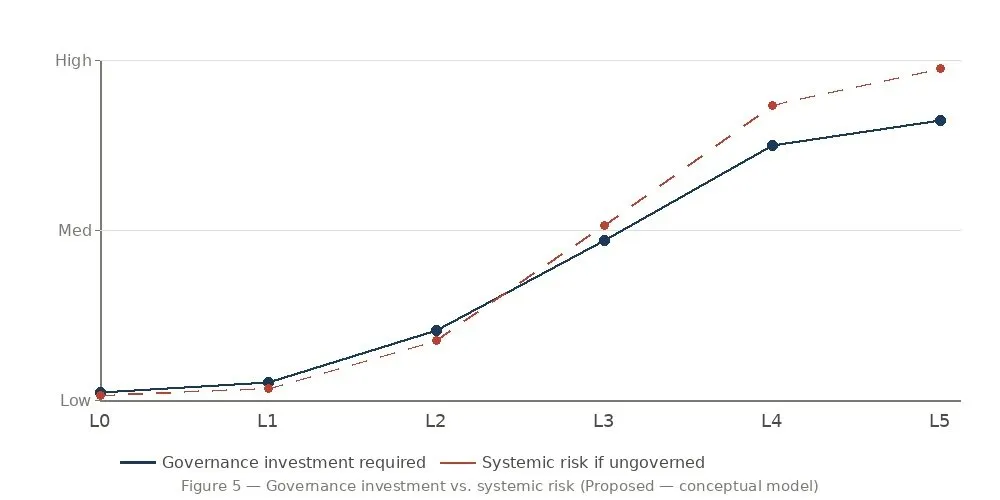
Figure 5 — Governance investment vs. systemic risk. The gap between the lines represents unmanaged exposure. PROPOSED — conceptual model.
Governance requirements vary significantly by domain risk. You need to know which tier you’re in before advancing to Level 3 and above:
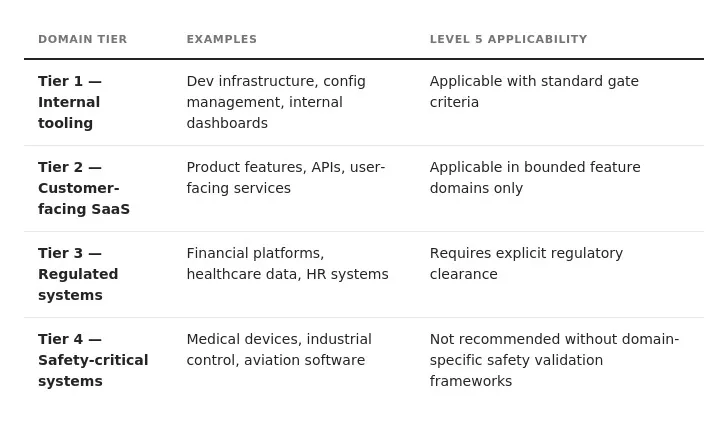
Six governance principles apply across all DRD levels: traceability (all AI-generated artifacts traceable to approved specifications — active from Level 2); accountability (non-transferable at all levels; shifts from implementation to specification and policy as autonomy increases); continuous validation (automated checks — manual gate reviews are insufficient at Level 3 and above); security controls (embedded in generation workflows, not post-generation layers — active from Level 2); deterministic rollback (predefined triggers and recovery procedures with defined SLOs — active from Level 3); and regulatory alignment with NIST AI RMF and the EU AI Act where applicable.
What This Means for Talent and Competitive Advantage
New roles — not replacement
With the rise of autonomous engineering, routine implementation becomes increasingly automated. Value shifts upstream to specification design, architectural judgment, and governance. Senior engineering judgment remains critical — it migrates from implementation to specification rigor, architectural guardrails, and governance design.
Three new role archetypes emerge at higher DRD levels. Specification Architects (from Level 3) translate business intent into structured, machine-readable specifications that serve as AI generation input. AI Orchestration Leads (Level 3–4) oversee AI-driven development workflows, validation pipelines, and output quality management. AI Governance Directors (Level 4–5) define policy guardrails, compliance controls, audit frameworks, and regulatory alignment.

Competitive Dynamics
The organizations that will compound competitive advantage aren’t those that adopt AI tools earliest. They’re those that build the specification architecture, governance scaffolding, and talent model capable of operating AI as a governed production system. Organizations operating at Level 3–4 gain compound advantages simultaneously: faster cycle compression, lower marginal implementation cost, embedded quality, improved talent leverage, higher specification maturity, and broader system intelligence. These advantages are structural, not tool-dependent — which means they’re defensible.
The Risks You Need to Manage
Moving up the DRD continuum without adequate governance doesn’t just introduce bugs — it introduces systemic failure modes. The following are ordered by compound severity.
Specification debt accumulates when requirements are ambiguous and propagate systemic defects under autonomous execution. This is arguably the most dangerous risk because it’s invisible until it’s very large.
Context window limitations and context rot represent a structural bottleneck that constrains how far autonomous generation can scale — and one that gets more severe, not less, as you advance through the DRD continuum. At Level 1–2, the constraint is largely invisible. At Level 3 and above, the AI must reason about module boundaries, system contracts, shared data models, cross-service dependencies, and architectural invariants simultaneously.
Current frontier models offer context windows of 128K–1M+ tokens — enough, on paper, to hold a significant codebase. But raw window size is misleading. Models systematically lose fidelity on content in the middle of their context window — a phenomenon researchers call lost in the middle. In Liu et al.’s controlled experiments (Stanford/TACL, 2024), accuracy dropped by more than 30% when relevant information was placed mid-context versus at the start or end.
Technical note for architects: The root cause is structural. The transformer’s self-attention computes pairwise relationships between all tokens — at 100K tokens, that’s 10 billion pairs — and modern positional encodings (notably Rotary Position Embedding) introduce a long-term decay effect that de-emphasizes middle-positioned content. This is an architectural property, not a training gap.
Chroma’s 2025 research formalized this as context rot — the measurable degradation in LLM output quality as input context grows longer. Their study tested 18 frontier models and found that every single one degrades at every input length increment tested. In practice, most long-context models show sharp performance drops past 32K tokens, well before reaching their nominal window limits.
A natural assumption is that agentic architectures sidestep the context window problem. They don’t. They make it worse. Each tool call dumps results back into the context. An agent that reads 10 files at 15K tokens each has consumed 150K tokens of context before generating a single line of implementation code.
This has direct architectural implications for DRD. At Level 3–4, the specification must compensate for what the context window cannot reliably hold. In DRD terms, specification precision is not just a governance requirement — it’s a technical workaround for a fundamental model limitation.

- Integration fragilityis a pattern specific to autonomous generation: AI-generated code is often syntactically correct but architecturally misaligned with broader system contracts.
- Autonomy overreach— expansion of AI authority beyond validated guardrails — requires policy-based execution boundaries, deployment authority constraints, and automated rollback triggers.
- Skill atrophyis a medium-severity risk that’s easy to underestimate. As implementation becomes automated, deep system understanding can erode.
The Objection: Won’t Better Models Make This Unnecessary?
The most common pushback against DRD is that the framework is solving a temporary problem. This objection deserves a direct answer because it’s partially right. Model capabilities are improving rapidly.
But the objection conflates two fundamentally different categories of problem. Model capability is a technology curve. Specification discipline, governance maturity, and organizational trust are institutional capabilities. They operate on different timescales, respond to different interventions, and compound in different ways. A more capable model doesn’t automatically produce a more governable production pipeline. It produces a more powerful one, which, without governance, is a more dangerous one.
DORA’s decade of delivery performance research supports this directly. The Accelerate State of DevOps reports have consistently shown that capabilities and discipline — not tools — predict elite delivery performance. DRD’s thesis is the same argument applied to AI: the tool is necessary but not sufficient.
Why Enterprises Stall — The Level-skipping Trap
The most common failure mode in enterprise AI adoption isn’t choosing the wrong tool or underinvesting in compute. It’s attempting to operate at a DRD level that the organization hasn’t structurally earned. We call it the level-skipping trap, and it has three characteristic variants:
Variant 1: The tooling leap
A CTO sees the productivity data, procures an enterprise agentic coding platform, and rolls it out to 500 engineers. Within weeks, individual developers are producing more code. Within months, the organization discovers that PR review queues have doubled, integration defects are up, and delivery velocity hasn’t improved — or has worsened. In DRD terms, they deployed Level 3–4 tooling into a Level 0–1 governance and specification environment.

Variant 2: The governance skip
This variant appears when an engineering organization has genuinely built specification discipline (Level 3 maturity) but attempts to operate at Level 4 or 5 without governance apparatus. The organization is flying a commercial aircraft without air traffic control: the plane works, but the system is one edge case away from a collision.
Variant 3: The cultural bypass
This is the subtlest and hardest to detect. An organization has invested in tooling, written governance policies, and even hired a Specification Architect — but the engineering culture hasn’t shifted. Engineers still treat AI output as “something I need to rewrite” rather than “an artifact I specified and now validate.”

If you recognize your organization in any of these variants, the correct response is not to retreat from AI adoption. It’s to honestly identify which layer is lagging and invest there.
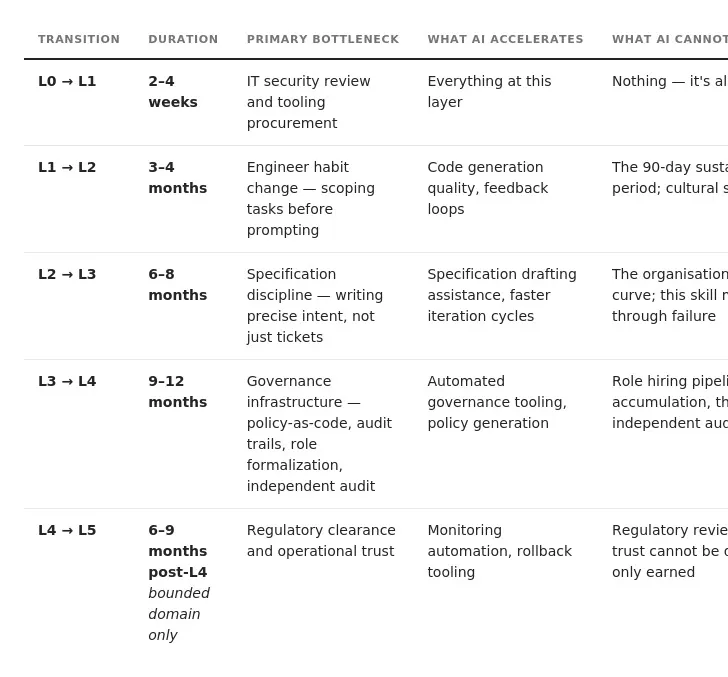
The Transition Gates
The following gates are proposed operating benchmarks, not validated industry thresholds. PROPOSED: Adapt them to your domain, risk class, and regulatory environment.
- Level 0 → Level 1requires no formal gate. Deploy an AI coding assistant, put output logging and a basic review practice in place.
- Level 1 → Level 2requires defined task scoping protocols, a structured human validation process, and documented baseline metrics. Exit criteria: AI output acceptance rate ≥65% sustained over 90 days.
- Level 2 → Level 3requires at least 50% of new features defined in structured, version-controlled specifications before AI engagement. There’s also a cultural gate: engineers need to shift from “reviewing code I wrote” to “validating outputs I specified.”
- Level 3 → Level 4requires the specification architecture function formalized as a distinct engineering role, policy-as-code implemented with automated governance checks running in CI/CD, and demonstrated rollback capability within one hour.
- Level 4 → Level 5is a high-risk gate, domain-bounded only. Governance automation reliability must be ≥95% in the target domain. Legal or regulatory review must be completed.
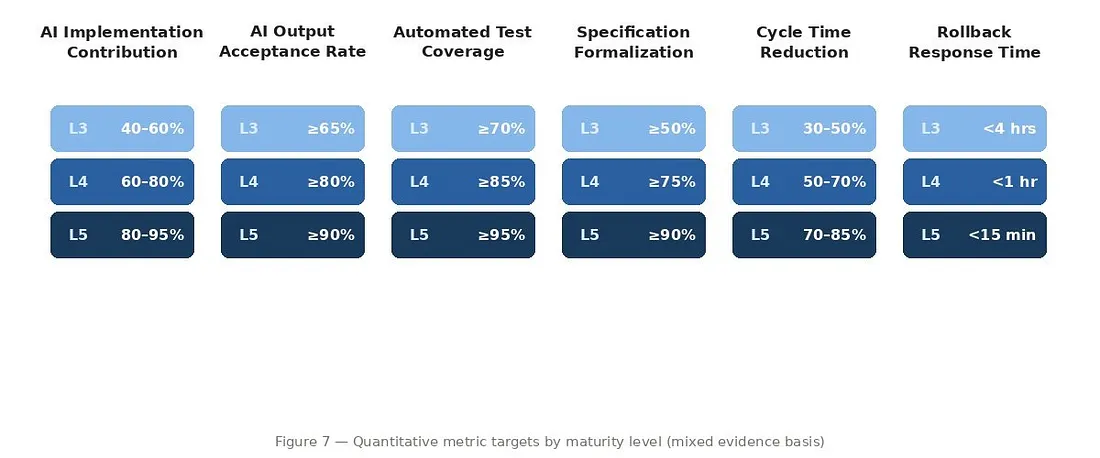
Figure 6 — Quantitative metric targets by maturity level (L3–L5). These are proposed operating benchmarks, not validated thresholds — adapt to your domain risk class. MIXED EVIDENCE
How Long Does this Actually Take?
The honest answer is that the journey to Level 4 takes 18–24 months, ESTIMATED for a typical enterprise moving with intent. Level 5, in a single bounded domain, is a further 6–9 months beyond that.
The DRD timeline is not sequential — it’s three overlapping layers of organizational change running in parallel:
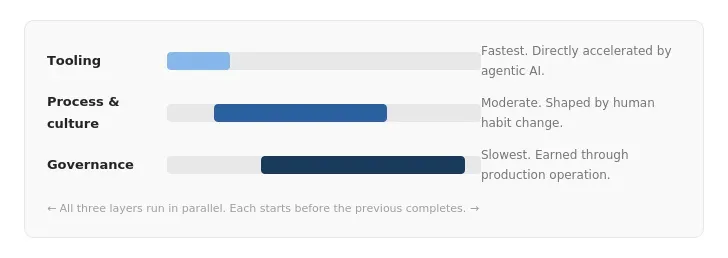
Tooling — Fastest. Directly accelerated by agentic AI.
Process and culture — Moderate. Shaped by human habit change.
Governance — Slowest. Earned through production operation.
Total to Level 4: 18–25 months. Total to Level 5: 2–3 years. For regulated domains, add 3–6 months at the L4 → L5 gate for regulatory review alone.

Why Agentic AI Compresses Some Gaps But Not Others
The rapid advances in agentic AI in 2025–2026 are genuinely compressing the tooling and parts of the process layer. But the governance layer has its own clock. It matures through production experience, not through better models.

What This Looks Like in Practice: A Projected Scenario
DRD is a new framework, and no organization has yet completed a publicly documented journey through it. The following composite scenario is illustrative.
A mid-sized fintech company (400 engineers, Series D, customer-facing API platform) deploys GitHub Copilot in Q1 2026. Within weeks, individual developers report writing code faster. By Q2, engineering leadership notices a paradox: PRs merged per sprint are up 30%, but deployment frequency hasn’t changed, and the review queue has doubled. They’ve hit the tooling leap — Level 2–3 tooling running on Level 0–1 governance.
In Q3 2026, the VP of Engineering hires two senior engineers into a new specification architecture function. They begin converting the top 20 most-changed API endpoints from Jira-ticket-plus-Slack-thread specifications into structured, version-controlled, machine-readable specs with explicit acceptance criteria. Progress is slow: engineers resist the discipline.
By Q1 2027, 55% of new feature work follows the structured specification workflow. AI-generated implementation quality has improved measurably — not because the model changed, but because the input changed. The team is operating at a genuine Level 3.
Projected timeline to Level 4: Q3–Q4 2027, approximately 18–20 months from initial deployment. The bottleneck will not be AI capability. It will be the independent governance audit, role formalization, and the accumulated trust in AI-generated output at production scale.
Where To Start: A 90-day Plan
The framework’s practical entry point isn’t a level target — it’s an honest assessment of where you actually are, followed by three specific investments.
- Assess your actual level honestly.
Apply the disqualifiers from the six-level descriptions to your current AI deployment. Most organizations using Copilot or similar tools are operating at Level 1. Misdiagnosing your starting point means investing in the wrong layer.
- Begin specification practice now, whatever level you’re at.
Start defining task scope, acceptance criteria, and AI output review processes explicitly — even for Level 1 usage. The specification discipline required for Level 3 takes 6–8 months to develop. It can’t be installed at the point of adoption.
- Build governance infrastructure ahead of autonomy, not in response to it.
Establish audit logging, rollback procedures, and policy baselines at Level 2 — before you need them. Governance infrastructure is the dominant bottleneck at the L3 → L4 transition.
The future of software engineering isn’t the elimination of human expertise — it’s its elevation. The Specification Architect, the AI Orchestration Lead, and the Governance Director aren’t diminished roles. They’re the roles that will define which organizations build durable structural advantage in the next era of software delivery.
Organizations that pursue this transition deliberately — with clarity about what’s proven, what’s proposed, and what remains to be validated — won’t just adopt the next generation of software engineering. They’ll define it.
Limitations — Scope and Boundaries of This Framework
Several limitations should be weighed when applying DRD to organizational planning. First, the framework is proposed by the authors — it is not an empirically validated industry standard. The transition gates, timeline estimates, and metric thresholds represent calibrated expert judgment informed by available evidence, not outcomes measured across a statistically representative sample of organizations.
Second, the controlled productivity studies cited measure individual developer performance on bounded coding tasks. Extrapolating these gains to system-level throughput requires assumptions about workflow composition, integration overhead, and organizational friction that the underlying studies do not test.
Third, the cost composition model is illustrative. The dollar values and percentage splits are conceptual anchors, not budget-grade estimates.
Fourth, DRD does not address non-software engineering applications of agentic AI.
Finally, the framework assumes access to frontier-class AI models with multi-step tool use, code generation, and specification consumption capabilities.
References
- Peng et al., “The Impact of AI on Developer Productivity: Evidence from GitHub Copilot,” arXiv:2302.06590, 2023.
- Cui et al., “The Effects of Generative AI on High-Skilled Work: Evidence from Three Field Experiments with Software Developers,” MIT Economics / SSRN, 2024.
- Google Internal RCT, 2024, reported in Faros AI, “The Reality of AI-Assisted Software Engineering Productivity,” 2025.
- GitClear, “AI Copilot Code Quality 2025: Research on Code Churn and Cloning,” 2025.
- Faros AI, “The Reality of AI-Assisted Software Engineering Productivity,” 2025.
- Gartner, “Predicts 2025: Agentic AI Shifts Enterprise Software Engineering,” 2024.
- Deloitte, “Autonomous Generative AI Agents: Under Development,” Technology Predictions, 2025.
- LangChain, “State of AI Agents Report,” 2024.
- DORA / Google Cloud, “Accelerate State of DevOps Report 2024.”
- McCain et al. (Anthropic), “Measuring AI Agent Autonomy in Practice,” Feb. 2026.
- Jellyfish, “What New Data Tells Us About the Rise of Agentic AI in Engineering Workflows,” Aug. 2025.
- GitHub / Accenture, “Research: Quantifying GitHub Copilot’s Impact in the Enterprise,” May 2024.
- NIST, Artificial Intelligence Risk Management Framework (AI RMF 1.0), Jan. 2023.
- European Commission, Regulation (EU) 2024/1689 — Artificial Intelligence Act, Jul. 2024.
- Stack Overflow, “Developer Survey 2024.”


















