The AI race isn’t about which model scores highest. It’s about who owns what your AI learns.
Every time we evaluated a new AI platform, the same question kept running through my mind: “What would it cost us — in time, context, and productivity — to move to a better tool tomorrow?”
I could never get a straight answer. We were clearly building something — preferences, workflows, institutional knowledge — but nobody could tell me who it belonged to, or whether we could take it with us.
That discomfort sent me down the rabbit hole of AI memory architecture. What I found was that most enterprises hadn’t asked the question at all — and were quietly building someone else’s moat, one AI interaction at a time.

The Real AI Competitive Advantage Isn’t the Model
The AI market has fixated on model benchmarks — which system scores higher, which generates faster, which hallucinates less. For enterprises deploying AI at scale, this is the wrong race to watch.
The durable competitive advantage lies not in which model your team uses today, but in who owns the accumulated context that makes AI genuinely useful.
Why Memory Is the Backbone of Enterprise AI
By default, AI foundation models are stateless — every session begins from zero. Modern AI products increasingly layer platform-level memory on top, but this memory is typically vendor-controlled and non-portable.
Consider what I call the Contractor Analogy:
Imagine hiring a brilliant contractor. On Day 1, you invest two hours briefing them — your brand voice, your target audience, your Q3 priorities, the competitors you track. They deliver excellent work. Then they leave, return the next morning, and remember nothing. After six months, you’ve paid for six months of briefings and captured perhaps six weeks of fully productive output. That is AI without memory.
Effective AI memory operates at two levels:
Short-Term Memory is analogous to a whiteboard during a meeting. It holds everything relevant to the current conversation. Most modern AI handles this reasonably well within a single session.
Long-Term Memory is a durable organizational asset. It stores three categories of information:
- Experiences— you rejected formal tone last month
- Knowledge— your brand guidelines and product catalog
- Skills— exactly how you like reports structured
When AI has true long-term memory, its usefulness compounds like interest. The performance gap between two identical models — one starting fresh, one carrying six months of context — is enormous and widens every week.
In typical usage patterns, ten knowledge workers spending just 20 minutes per day re-briefing AI tools lose over 800 hours per year — the equivalent of nearly half a full-time headcount spent repeating context that should already be known.
The Walled Garden: How AI Vendors Engineer Lock-In
Every major AI platform wants to be where your memory lives. The result is memory architectures that make switching costly — by design.
Think of the CRM Parallel: businesses that built their customer databases inside a CRM with a proprietary data format discovered that switching vendors meant losing years of data structure and workflow logic. The switching cost was engineered into the product. AI vendors are replicating this model with memory — except it’s worse. Unlike a CRM migration, you can’t even export a tidy spreadsheet. You simply start from zero.
If your team spends six months teaching an AI platform your internal terminology, approval workflows, and communication style, none of that transfers when you open a competing tool. Every correction, every preference, every piece of feedback flows into the vendor’s moat — not yours.
An important shift to watch: As of Q1 2026, Anthropic launched a memory import feature for Claude that lets users transfer context from ChatGPT, Gemini, Copilot, or Grok via prompt-based import. It’s currently labeled experimental, and it’s prompt-based rather than structured interoperability — but it signals that portability is becoming a competitive differentiator. Vendor positions on portability reveal who benefits from lock-in.
Breaking Free: Owning Your AI’s Briefcase
The core architectural insight is simple: think of AI as two separable components — the engine (the language model that generates text) and the briefcase (everything your AI knows about your organization). Current vendor products force you to store your briefcase inside their engine. The strategic move is to own the briefcase separately.
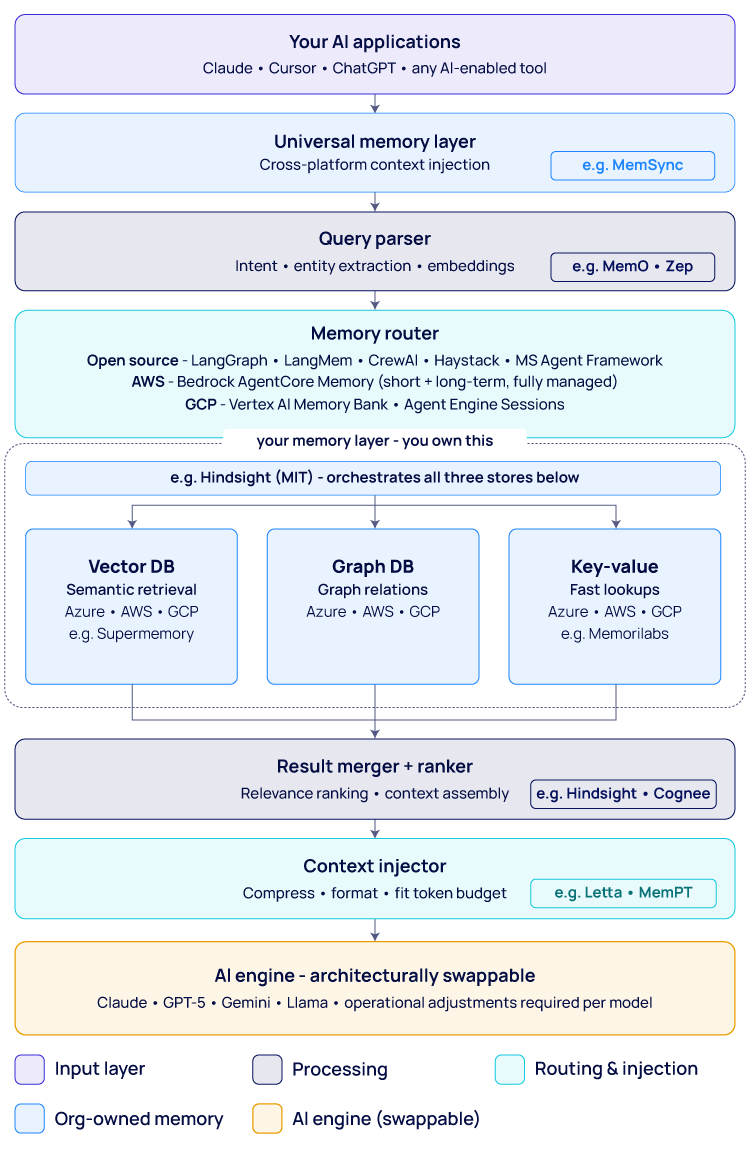
Architecture Diagram
The full architecture for a portable memory layer looks like this, from top to bottom:
- Your AI applications— Claude, Cursor, ChatGPT, any AI-enabled tool
- Universal memory layer— cross-platform context injection (e.g., MemSync)
- Query parser— intent and entity extraction, embedding (e.g., Mem0, Zep)
- Memory router— directs queries to the right store; open-source options include LangGraph, CrewAI, Haystack, and MS Agent Framework; managed options via AWS Bedrock or GCP Vertex AI
- Your memory stores(the layer you own): Vector DB for semantic retrieval, Graph DB for relational context, Key-value store for fast lookups
- Result merger and ranker— relevance ranking and context assembly
- Context injector— compresses and fits context into the model’s token budget (e.g., Letta/MemGPT)
- AI engine— architecturally swappable: Claude, GPT-5, Gemini, Llama
The key design principle: only the storage layer is cloud-specific. Everything above it is cloud-agnostic, meaning your organizational memory can migrate between hyperscalers without restructuring the architecture.
Practical Entry Points (No Engineering Required)
You don’t need to build the full stack to start. Four practical paths to get started:
- Memory import tools— transfer preferences from competing platforms via copy-paste prompt. Claude’s import feature (claude.com/import-memory) is free and requires no engineering.
- Universal memory layers— set a preference once and every connected AI picks it up. MemSync (a16z-backed, Chrome extension) and Onoma (14-platform sync) are early examples.
- Private memory databases— your organizational context lives in a database you control, governed by your own access policies. Mem0 (Apache 2.0, 41k+ GitHub stars) and Supermemory are solid starting points.
- Self-managing recall agents— agents that autonomously manage their own memory without manual prompt engineering. Letta (formerly MemGPT, UC Berkeley) is the leading open-source option.
Memory as a Compounding Asset
The most underappreciated dimension of AI memory isn’t what it stores — it’s how its value accelerates over time.
A team that owns its memory layer is building what I call an Enterprise Memory Fabric (EMF): a persistent, portable, organization-controlled layer of accumulated intelligence that grows more valuable with every interaction.
In month one, an EMF saves your team from repeating context. In month six, it captures nuanced preferences, workflow patterns, and decision history that no new hire — human or AI — could replicate quickly. By month twelve, the gap between a team with owned memory and a team starting fresh is difficult to close by simply switching to a better model.
Three mechanisms drive the compounding effect:
Feedback loops. Memory doesn’t improve passively. Production systems need a reinforcement loop: usage generates outcomes, outcomes are evaluated, and evaluated outcomes update what gets stored. Without this loop, memory becomes an archive. With it, memory becomes intelligence.
Accumulating institutional knowledge. Individual preferences are the first layer. Over time, an EMF accumulates organizational patterns — the decisions your teams consistently make, the language your brand actually uses, the edge cases your domain has encountered and resolved. This layer is yours by definition, and irreplaceable if lost.
The switching cost asymmetry. If context lives in your own fabric, you can upgrade models, negotiate on price, or adopt new tools without sacrificing what your organization has built. If it lives in a vendor’s platform, that same compounding effect works against you.
Here’s how the value horizon breaks down:

Where Does Your Organization Stand?
Use this maturity model to assess your current position:
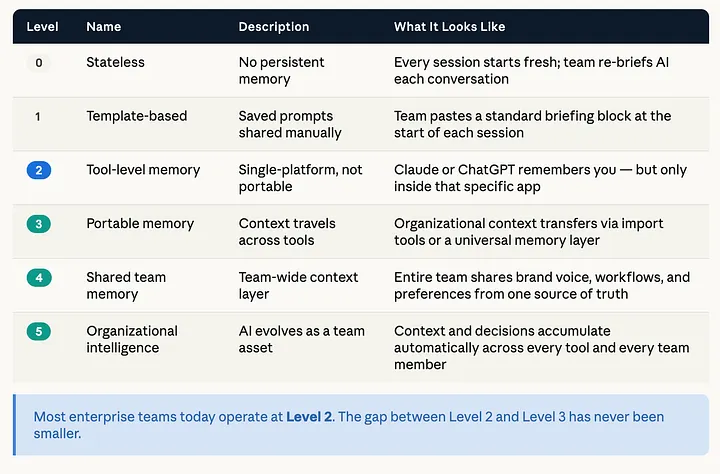
- Level 0 — Stateless:Every session starts fresh. Team re-briefs AI on each conversation.
- Level 1 — Template-Based:Saved prompts shared manually. Team pastes a briefing block at the start of each session.
- Level 2 — Tool-Level Memory:Single-platform memory that isn’t portable. Claude or ChatGPT remembers you — but only inside that specific app.
- Level 3 — Portable Memory:Context travels across tools via import features or a universal memory layer.
- Level 4 — Shared Team Memory:Entire team shares brand voice, workflows, and preferences from a single source of truth.
- Level 5 — Organizational Intelligence:Context and decisions accumulate automatically across every tool and every team member.
Most enterprise teams today operate at Level 2. The gap between Level 2 and Level 3 has never been smaller — entry-level portable memory is now accessible without significant engineering investment.
The Strategic Question Leaders Aren’t Asking
The model landscape will continue to change rapidly. GPT-5, Claude 4, Gemini Ultra, and open-source alternatives will each claim benchmark leadership at different moments. Organizations that have tied their AI strategy to any single model are exposed to this churn.
Organizations that own their memory layer are not. When models are interchangeable, you adopt the best tool for each job — without losing accumulated context, without negotiating migration costs you engineered yourself into.
The right strategic question isn’t “which model is smartest right now?” It is:
“Who owns the memory?”
If the answer is your vendor, you are renting an asset you are actively building.
Every preference corrected, every workflow taught, every piece of feedback given is either compounding into your organization’s most valuable AI asset — or quietly deepening a vendor’s switching cost. That answer is being decided right now, by default, in every AI interaction your team has today.
The organizations that will define the next decade of enterprise AI are not those that picked the best model in 2026. They are the ones who started building their memory layer before anyone else thought to ask who owned it.


















