Frontier-grade tokens are 99.5% cheaper than GPT-4’s launch price. Enterprise AI spending tripled in a year (Menlo Ventures, December 2025). The two facts can both be true because the rate card you’re being quoted no longer maps to the bill you actually pay — and the distortion is widest in the same places the closed-source premium is hardest to defend: reasoning-heavy workloads and Pro/Fast service tiers.

If you take one thing from this piece, take this: the right unit for cross-model procurement comparison is cost per completed task, not dollars per million tokens. Each term above is a place where the rate-card price diverges from the bill — tokenizer adjustments range roughly 0.65–1.35 across recent model generations, reasoning tokens add 1.18×–9× to the output count, and discounts apply only to the workload shapes that fit them.

What 99.5% Off Actually Bought You
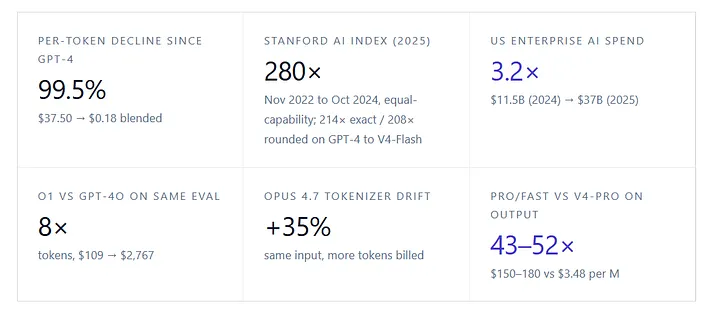
When OpenAI launched GPT-4 in March 2023, the published price was $30 per million input tokens and $60 per million output. Blended at a 3:1 input-to-output ratio that is closer to most enterprise workloads than 1:1, that’s $37.50 per million tokens. By April 2026, DeepSeek V4-Flash sat at $0.14 input, $0.28 output — $0.175 blended on the same formula, which rounds to $0.18. That’s a 214× ratio exact, or 208× with the V4-Flash blended price rounded — same order of magnitude either way, on this specific basket. The Stanford 2025 AI Index documented a 280× decline in inference costs between November 2022 and October 2024 using its own equal-capability methodology — measured against GPT-3.5-level performance on MMLU, a different basket of frontier-equivalent capabilities. The 2026 Index extends the trend on more recent baselines. Epoch AI clocks the broader trajectory at 5–10× per year and up to 32× per year for high-performance models specifically. The headline is real either way: per-token, frontier-class capability is now nearly two orders of magnitude cheaper than it was three years ago.
And yet. Enterprise generative AI spending tripled over that period. Menlo Ventures’ 2025 State of Generative AI in the Enterprise (~500 US enterprise decision-makers, December 2025) puts US enterprise generative AI spend at $11.5 billion in 2024, rising to $37 billion in 2025 — a 3.2× year-over-year jump described as the fastest enterprise category expansion in history. Either every enterprise on the planet is suddenly running 100× more workloads than they were in 2023 — which is not, on the production-deployment data, what is happening — or the cost-per-token compression is being substantially offset by something else. The “something else” is the subject of this piece. There are three of them, and they compound.
The quoted price and the invoice are no longer the same document. The first arrives as a clean rate card. The second arrives after invisible reasoning tokens, tokenizer changes, cache misses, and service-tier routing have all done their work. CFOs noticing the gap aren’t watching procurement fail; they’re watching a unit of measurement break under load.
Gotcha 1 — Reasoning Tokens
The first hidden tax arrived with OpenAI’s o1-preview in September 2024 (and the production o1 release that December). Unlike the models that came before it, o1 generated an internal chain of reasoning — visible to the model, billed to the user, and not displayed back. Those reasoning tokens were billed at o1’s $60 per million output rate; the same as the final answer. Independent measurement by Artificial Analysis on a fixed seven-benchmark evaluation suite found that o1 produced 44 million tokens to GPT-4o’s 5.5 million on the same problems — an 8× multiplier that turned a $109 evaluation into a $2,767 one. The visible portion of the answer was unchanged. The bill was 25× larger.
That ratio is the high end of the range. Across the model field as of early May 2026, the multipliers — measured on benchmark suites that stress reasoning and not necessarily reflective of production traffic mix — vary considerably:
- DeepSeek V4-Flash thinking mode:18× (very token-efficient — adds about $0.0005 per task)
- DeepSeek V4-Pro standard thinking:62×
- DeepSeek V4-Pro Max:up to 4.3× on benchmark reasoning workloads (the top reasoning effort tier)
- Claude Opus 4.6 extended thinking:2–5× depending on workload
- OpenAI o1-mini:4×
- OpenAI o1:8×
- OpenAI o1 pro:~9×
The buyer sees this in absolute dollars. Token inflation is a multiplier on the existing per-token base rate, so it hurts expensive APIs more than cheap ones. A 3.5× thinking multiplier on Claude Opus 4.7 at $25 per million output tokens yields an effective rate of $87.50 per million. The same 1.62× multiplier on DeepSeek V4-Pro at $3.48 per million yields $5.64. The headline rate-card gap was 7.2× on output. The effective gap, with both models in their default thinking modes, is closer to 16×. Push Opus into its 5× max-thinking range, and it widens further. At the extreme — o1 pro at $600 per million output, 9× thinking multiplier — the effective output rate is $5,400 per million, against V4-Pro Max’s $14.96. That’s a ratio of about 360×, on a workload class where the published rate-card ratio looks like 170×.
A separate strand of academic work has begun stress-testing the assumption that more reasoning tokens always help. Tomlinson et al.’s February 2026 preprint Reasoning about Reasoning establishes asymptotic Ω(n) lower bounds on chain-of-thought length for several reasoning tasks — token costs scale at least linearly with input size, with attention compute superlinear on top of that. Lee et al.’s How Well do LLMs Compress Their Own Chain-of-Thought? (March 2025) is the complementary result: every task has an intrinsic token complexity, a minimum number of reasoning tokens below which accuracy collapses. The procurement-relevant inference is what sits above that floor.
Lee et al. also document that current reasoning models operate well above the theoretical minimum on a substantial share of model–task combinations — meaning a meaningful fraction of the “thinking” you are paying for sits in the headroom between the floor and the default budget, where compression has bounded accuracy cost. That should make buyers nervous in a specific way: not “reasoning is free to compress” — it isn’t, below the floor — but “default reasoning budgets exceed the floor by enough margin on enough workloads that the procurement question is whether you are routing reasoning effort or paying for it by default.” Whether that’s a defect of the reasoning training, a property of the workload, or both is an open research question. Most enterprise AI deployments use it as a default. That is now an explicit cost decision rather than a free upgrade.[1]
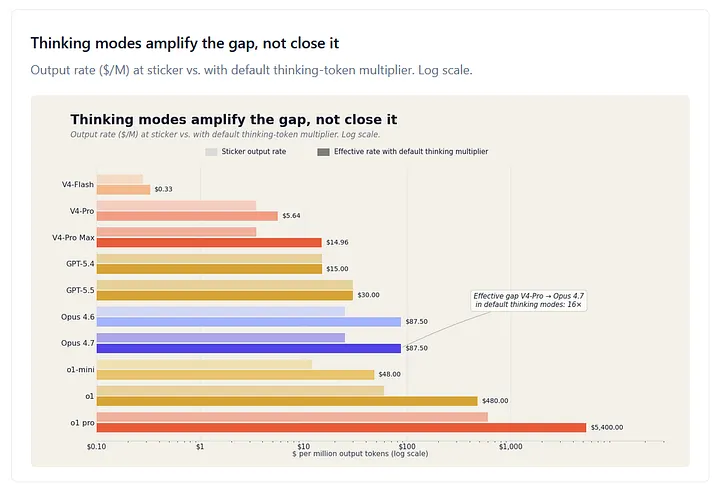
Figure 1. Output rate ($ per million tokens) at sticker price versus the effective rate once the model’s default thinking-token multiplier is applied. The Opus 4.7 vs V4-Pro effective gap in default thinking modes is approximately 16× — wider than the 7.2× sticker-price ratio. The o1 pro vs V4-Pro effective gap reaches roughly 360×. Multipliers from Artificial Analysis and DeepSeek V4 technical report §5.3.2; output rates from vendor pricing pages, May 2026.
Gotcha 2 — Tokenizer Drift
Each new model generation often comes with an updated tokenizer. The tokenizer is the piece of the pipeline that breaks input text into the units the model actually counts and bills against. When the tokenizer changes, the same input — your customer-support transcript, your contract, your codebase — counts differently. The price card doesn’t move. The bill does.
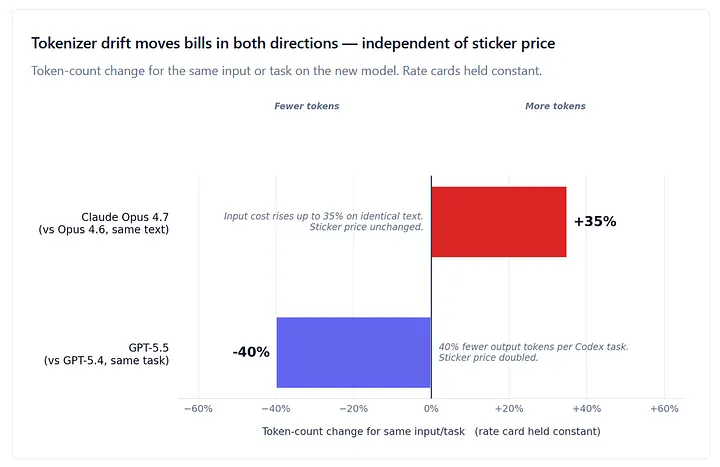
Two examples on opposite sides of the ledger illustrate the point. Claude Opus 4.7, released April 16, 2026, kept the same $5 input / $25 output per million token sticker price as Opus 4.6. Anthropic’s own pricing documentation acknowledges that “this new tokenizer may use up to 35% more tokens for the same fixed text,” a figure consistent with FinOps-platform measurements on representative production workloads (Finout, May 2026). With no change to the published rate, the effective input cost on a typical enterprise workload rose by up to 35%. Anthropic did not announce this as a price change. Several developer-community analyses have called it a “stealth price hike,” and the description fits: the input is the same, the model is positioned as an upgrade, and the bill goes up.[2]
GPT-5.5, released April 23, ran the same play in the opposite direction. OpenAI doubled the per-token rate over GPT-5.4, from $2.50 input / $15 output to $5 input / $30 output, and from $5.63 blended to $11.25 blended. Independent measurement by Artificial Analysis (and corroborated by Vellum’s launch analysis) recorded GPT-5.5 producing approximately 40% fewer output tokens than GPT-5.4 on Codex coding tasks at matched per-token latency. So, a 2× sticker increase paired with a 40% output-token reduction. The natural assumption is that those two effects roughly cancel out. They don’t — and walking through why is the cleanest illustration in the whole piece of why rate cards have stopped being the right unit.
The GPT-5.5 Paradox
Walk through the math with a concrete coding task that consumed 800 input tokens and 4,000 output tokens on GPT-5.4 — a typical agentic-coding shape, where the prompt is small, and the generated patch or trace is large.
On GPT-5.4 at $2.50 / $15.00, that task cost $0.0020 in input and $0.0600 in output. Total: $0.062.
On GPT-5.5 at $5.00 / $30.00, with output tokens reduced 40% to 2,400, the same task costs $0.0040 in input (input rate doubled, input tokens flat) plus $0.0720 in output (output rate doubled, output tokens down 40%). Total: $0.076.
Net change: +22.6%. Round to “approximately 20% net cost increase per task,” which is what OpenAI’s own launch position acknowledges and what Vellum’s analysis lands on independently.
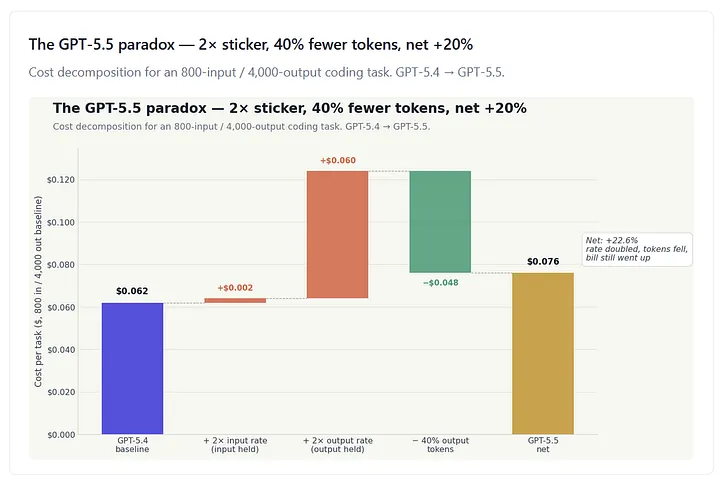
Figure 2. Cost decomposition for an 800-input / 4,000-output coding task moving from GPT-5.4 to GPT-5.5. The 2× input-rate increase adds $0.002. The 2× output-rate increase, holding output tokens constant, would add another $0.060. The 40% reduction in output tokens at the new rate gives back $0.048. Net: +$0.014, or +22.6% per task. Calculations applied to OpenAI’s published rate cards and Vellum’s independent measurement of GPT-5.5 output-token usage on Codex.
The arithmetic is not the interesting part. The interesting part is the structural asymmetry. Output tokens fell because the model generates more concise responses — a real efficiency gain that translates directly to lower compute expenditure for OpenAI on each query served. The 2× rate increase, however, applies to both input and output tokens. So, the efficiency gain accrues to the vendor; the price increase accrues to the buyer. A model can simultaneously be more efficient (fewer tokens per task) and more expensive (higher total cost), and GPT-5.5 is exactly that.
There is a parallel academic finding from a March 2026 paper that arrived at this same observation from the opposite direction: lower-priced API models can cost more per task than higher-priced ones once token efficiency is properly accounted for. The paper’s specific result — GPT-5.2’s per-token API price was 4.5× that of Gemini 3 Flash, but its actual per-task cost was 81% of Gemini’s — is not directly transferable to the V4-Pro vs. Opus 4.7 comparison this series cares about, but the methodological point is. Per-token rate-card comparisons are now structurally unreliable as cross-model cost estimates. The right unit is per-task on a fixed evaluation harness. Artificial Analysis publishes one as part of its Intelligence Index. By that measure, evaluating the entire Intelligence Index on GPT-4o (November 2024 snapshot) cost $196.97 end-to-end. The same evaluation on a contemporary reasoning model often runs $500–$1,500 because of thinking-token expansion. The rate card hasn’t been useful as a cross-model cost estimator since approximately mid-2024.[3]
What Would Change This Conclusion
One specific empirical claim cuts directly against the framing of this section. Part 1 flagged it, and this piece has to deal with it head-on.
OpenAI’s GPT-5.5 launch position is that the model uses approximately 40% fewer output tokens than GPT-5.4 on Codex tasks at matched per-token latency. A separate third-party measurement by MindStudio reports 72% fewer output tokens than Claude Opus 4.7 on identical coding tasks. If those gains generalize beyond Codex to the workloads most enterprises actually run — RAG pipelines, document extraction, classification, customer support automation, document analysis — and if the per-task cost (not the per-token cost) for GPT-5.5 lands at or below DeepSeek V4-Pro’s on independent measurement, the headline 8.6× output-rate gap this piece relies on is misleading, and the rate-card framing this series runs needs to be reframed in tokens-per-completed-task rather than dollars-per-million-tokens.
That is the falsification condition for the Part 2 thesis. It is worth taking seriously. There are three reasons it has not yet been met.
First, the 40% figure is self-reported by OpenAI and scoped narrowly to Codex. OpenAI has not published a broader workload comparison, and the independent replication that exists is limited to coding workloads. RAG, classification, extraction, and support workloads have a different token-shape profile and different sensitivity to verbosity. The 40% Codex number is plausible. Its generalization is not yet demonstrated.
Second, the 72% Opus comparison is third-party but limited to coding, and Opus is by Anthropic’s own positioning a verbose model. The comparison flatters GPT-5.5 partly by using a high baseline. A separate Substack 38-task benchmark (FundaAI) reports V4-Pro produces denser output than Claude on coding and analytical workloads, fewer boilerplate disclaimers, and more substantive content per response. That observation is consistent with what other reviewers describe qualitatively, but the FundaAI piece’s quantitative comparison mixes units (output tokens for DeepSeek vs character counts for Claude), so it should be read as illustrative rather than as a primary measurement. Any token-efficiency comparison serious enough to drive procurement should be against V4-Pro specifically, not against the Anthropic baseline, and should run on consistent units across both models.
Third, even on the OpenAI claim’s own terms, a 40% output-token reduction on Codex, the math lands at +20% net cost per task vs. GPT-5.4, not parity with V4-Pro. To collapse the V4-Pro gap, GPT-5.5 would need to be using close to 90% fewer output tokens than V4-Pro on the same workload. The rate-card ratio is 8.6× on output, so per-task parity requires the token count to fall by the same factor. That is well outside the published range and not corroborated by independent harness runs.
So, the test is specific and currently unmet. If a credible independent measurement publishes per-completed-task costs across mixed enterprise workloads (not just coding) showing GPT-5.5 within shouting distance of V4-Pro, the analysis here gets re-anchored. Until then, rate-card multiples adjusted for thinking and tokenizer effects are the best available proxy, and they say what Part 1 said: the gap is real, it is wide, and it is widest exactly where the premium is widest.[4]
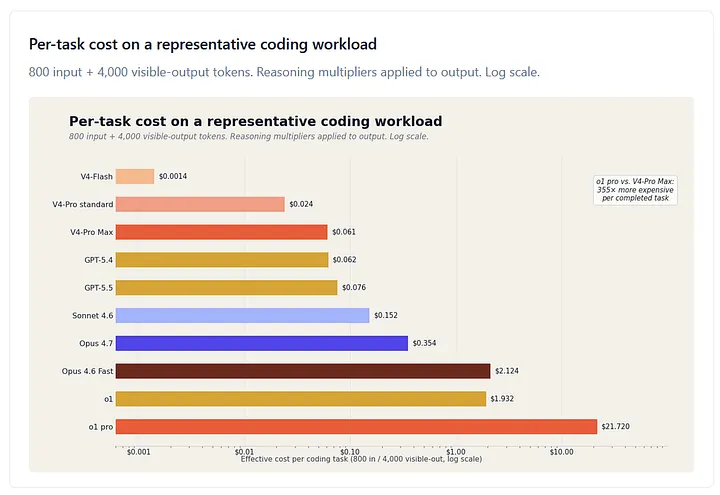
Figure 3. Effective cost per task on an 800-input, 4,000-visible-output coding workload. Reasoning-token multipliers applied to the output portion (V4-Flash thinking 1.18×, V4-Pro standard thinking 1.62×, V4-Pro Max 4.3×, Sonnet 4.6 thinking 2.5×, Opus 4.7 default thinking 3.5×, o1 8×, o1 pro 9×; GPT-5.5 0.6× to reflect 40% token reduction; GPT-5.4 1.0×). V4-Flash standard mode at $0.0014 sits 15,000× below o1 pro at $21.72 on the same task — a procurement spread that no rate-card comparison surfaces. The V4-Pro Max vs Opus 4.7 ratio on this workload is roughly 6×, close to the 5.7× rate-card frontier ratio Part 1 carried (1:1 blended; 5.33× at the 60/40 mix used elsewhere in this piece).
What Batch and Cache Do — and Don’t — Change
It’s worth going through the discount mechanics before turning to the tier and self-host arguments because most procurement conversations get hung up here.
Batch APIs.
OpenAI, Anthropic, and Google all publish batch endpoints that return responses asynchronously — typically within 24 hours rather than seconds. The discount is consistent across providers at roughly −50% on both input and output rates. Batch is genuinely useful for offline workloads — overnight document classification, large-scale embeddings generation, evaluation harnesses, content moderation pipelines that don’t need real-time latency. It is genuinely not useful for interactive workloads, which is most consumer-facing AI usage.
DeepSeek as of early May 2026 does not publish a separate batch API. Its equivalent is off-peak pricing: the standard rate already sits below most providers’ batch rate, and DeepSeek further reduces it during off-peak hours. The effect on a procurement comparison is that the batch discount narrows the gap between standard-tier closed-source pricing and standard-tier open-weight pricing, but does not close it: GPT-5.4 batch at half-rate is $1.25 input / $7.50 output, blended around $2.81 per million; V4-Pro standard is $2.18 blended; V4-Flash standard is $0.18 blended. The gap compresses but doesn’t collapse.
Prompt caching.
All three major closed-source providers offer cached-prefix discounts when the same long context (a system prompt, a knowledge-base passage, a code repository) is reused across queries. Discounts range from −50% to −90% on the cached portion specifically, not the whole request. For workloads with high prefix-reuse such as agentic coding with the same codebase, RAG over a stable document corpus, or customer-support flows with a long system prompt, cache savings can be substantial. For workloads where every query has a different context, they are zero.
DeepSeek’s V4 series ships with on-disk KV cache management built into the inference stack — a substantial architectural advantage at long context (the V4 technical report claims 10× KV cache size reduction versus V3.2 at million-token context (V4-Pro uses 10% of V3.2’s KV cache; V4-Flash 7%)). And as of April 26, 2026, DeepSeek’s API publishes cache-hit pricing as a separate tier alongside cache-miss: V4-Pro at $0.145/M input on cache hit versus $1.74/M on miss, V4-Flash at $0.014/M versus $0.14/M — roughly a 90% discount on cached input, comparable to what Anthropic, OpenAI, and Google offer.[6]
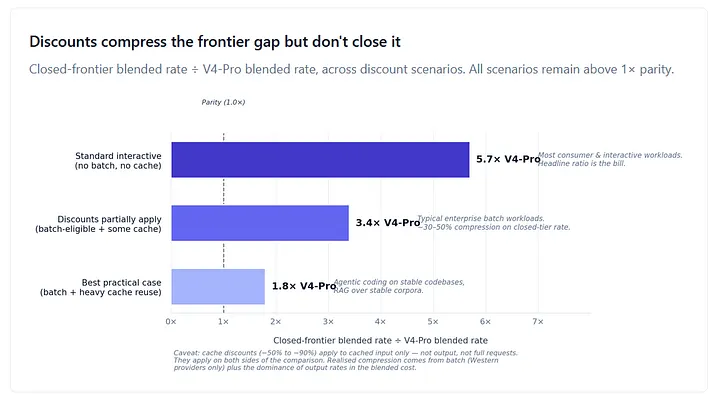
Which means cache discounts compress the gap on both sides of the comparison. With aggressive cache reuse (90% hit rate on input), V4-Pro’s blended rate falls from $2.44 to roughly $1.58, while Opus 4.7 falls from $13 to roughly $10.57 — a ratio that actually widens slightly to ~6.7×, because output dominates the blend in a 60/40 mix and DeepSeek’s $3.48 output is already 7× cheaper than Opus’s $25, and cache discounts apply only to input. It is the asymmetric discount — batch — that compresses the closed-vs-open ratio. Western providers offer it; DeepSeek doesn’t (its analogue is off-peak pricing, baked into the headline rate). With cache plus batch on Opus and cache only on V4-Pro, the ratio compresses to ~3.4×. GPT-5.5 sits in the same tier at $5/$30 ($15/M blended), putting the GPT-5.5 vs V4-Pro sticker ratio at 6.1× — slightly wider than the Opus comparison, and the same compression dynamics apply.
So, discounts help — but they don’t rescue the rate card, and they don’t compress the gap as cleanly as a one-sided view would suggest. Cache compresses input symmetrically on both sides; output rates carry no cache discount. Batch is the one truly asymmetric discount, and that’s where the realized compression actually comes from. At hyperscaler volumes and on workloads that don’t fit the batch or cache profile, the headline 5.7× frontier ratio is closer to 3–4× after discount, which is still an enormous gap. At standard-tier interactive workloads with no cache reuse, the headline ratio is the bill. And none of those discounts apply to the part of the rate card that is hardest to defend on any operational metric: the premium service tier above standard frontier.
The Pro/Fast tier — Where the Premium Stops Looking Operational
Standard-tier rate cards are at least defensible on operational grounds. The Pro and Fast tiers are not.
GPT-5.5 Pro and GPT-5.4 Pro are priced at $30 input / $180 output per million tokens. Claude Opus 4.6 Fast Mode lists at $ 30/$150. Both are roughly 6× the standard rate of the same underlying model, and there is no equivalent in the open-weight world because what you are buying at this tier is not capability — it’s service quality. Latency SLAs, dedicated capacity, premium support, no-noisy-neighbor throughput guarantees. Real things, and worth paying for in narrow circumstances.
The question is the multiple. Against DeepSeek V4-Pro at $3.48 per million output, the Pro/Fast tier is 43–52× more expensive on output rate alone, before any thinking-token effects. One technical caveat: this is a rate-card-to-rate-card comparison. Self-hosted open-weight inference doesn’t expose a per-token equivalent — it bills as TCO, not per token — so the 43–52× is a sticker comparison, not perfectly apples-to-apples. The broader case against the tier rests on the operational-quality argument that follows. Even granting the most generous account of what dedicated-capacity premium service is worth in operational terms — call it 2× over standard, which is the range where most enterprise SLA contracts price comparable upgrades — that leaves a 20–25× gap unexplained by anything except market structure.
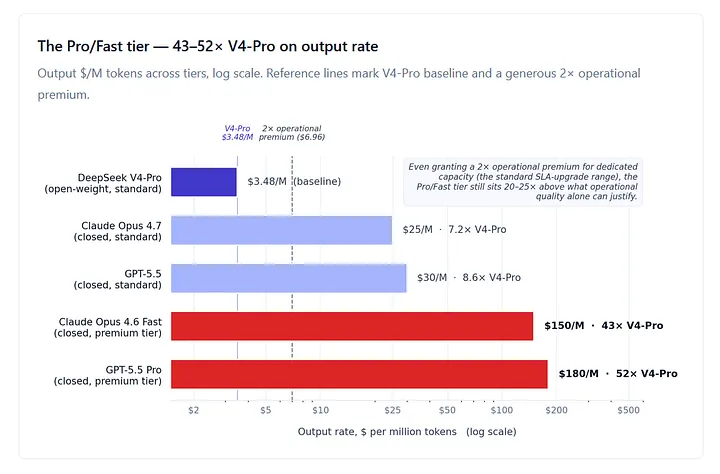
What the Pro/Fast tier reveals is that the closed-source frontier has weak price discipline at the top of its stack. There is no open-weight Pro/Fast equivalent because the buyer running self-hosted inference is the dedicated capacity. Self-hosting is, in effect, the open-weight analog of the Pro tier, and at hyperscaler volume it costs 50–100× less than the closed-source Pro/Fast pricing for the same effective dedicated-capacity profile. That comparison is the next section.
Self-host Economics — What the Rate Card Doesn’t Price
The argument so far has stayed on the API side of the comparison. The other half of the cost calculus is what self-hosting actually costs once you build the bill honestly. The claim Part 1 deferred to Part 2 was specifically that self-hosting open-weight frontier models on H200-class hardware deliver 79–182% twelve-month ROI against Claude Opus 4.7 at hyperscaler volumes in the deployment scales modeled here. The lower-bound case is the small-deployment, mid-volume scenario; the upper-bound case is the high-volume, large-cluster scenario. Either case rests on a TCO model that needs to be walked through, because every line item in it is a place a credible critic can push back.
Hardware
The NVIDIA H200 (141 GB HBM3e, 4.8 TB/s memory bandwidth) has emerged as the practical workhorse for production frontier-model inference in 2026. Its 76% memory advantage over the H100 enables a 2:1 consolidation on DeepSeek V4-Pro (1.6T total parameters, 49B active in FP8): one H200 does the job of two H100s. Market price as of early May 2026 sits at $40,000–$45,000 per SXM unit, down from $55,000 MSRP. The B200 (Blackwell) at $50,000–$60,000 is the upgrade path on a 36-month deployment, but H200 is the pragmatic 2026 choice given Blackwell availability constraints.
Operating Cost
Facility OpEx — GPU power, cooling, rack space, cross-connects, networking, and premium support — runs about $800 per H200 per month at the rack densities and SLAs required for production frontier-model inference. (First-principles GPU power alone, at $0.12/kWh and PUE 1.3, accounts for roughly $80 of that; the remainder is what it costs to be in a real data center with redundant networking, premium support contracts, and the rack/colo overhead that hyperscalers absorb but on-prem operators pay directly.) Software licensing for the inference stack (vLLM, TensorRT-LLM, Triton — most production-grade open-source, but enterprise support contracts run real money) adds 5–10% on top.
MLOps Headcount
This is the line item most TCO models underweight, and it is the line item enterprise critics most often correctly call out. AISuperior’s 2026 self-hosting cost analysis finds that personnel costs typically consume 30–55% of total self-hosted TCO depending on deployment scale and operational maturity — the share is highest at small scale (where the FTE base can’t shrink below a credible 2-FTE minimum and absorbs a disproportionate share of the bill), and falls toward 20% at hyperscaler volumes (where hardware CapEx scales faster than headcount). In the deployments modeled in Figure 4, MLOps lands at roughly 38% of monthly TCO at small scale, 25% at medium, and 20% at large. A small open-source LLM deployment requires 10–20 hours per month of senior engineering time for maintenance — at $75–$150/hour fully loaded for senior DevOps or ML engineers, that’s $750–$3,000/month in labor cost on top of infrastructure. The minimum credible TCO for an enterprise-grade self-hosted deployment is around $125,000 annually; large implementations easily exceed $1–12 million annually in personnel alone.
SLA and Reliability
A self-hosted deployment that maintains 99.9% uptime is a serious engineering operation: redundant inference clusters, automatic failover, monitoring, on-call rotation, capacity planning. Buyers comparing self-host TCO against API spend systematically underweight this. A team that cannot actually run inference reliably is comparing the wrong number to the wrong number.
Data Residency and Audit
For regulated industries (healthcare under HIPAA, finance under SOX and PCI-DSS, government under FedRAMP), data residency and audit trail aren’t optional features. They can be the entire reason a closed-source API is off the table, even when its rate-card economics would otherwise win. Self-hosting collapses this question: the data never leaves your infrastructure. Whether that’s worth the operational overhead depends on how strict the regulatory environment is, but for some buyers it isn’t a cost-optimization argument at all. It’s a compliance prerequisite.
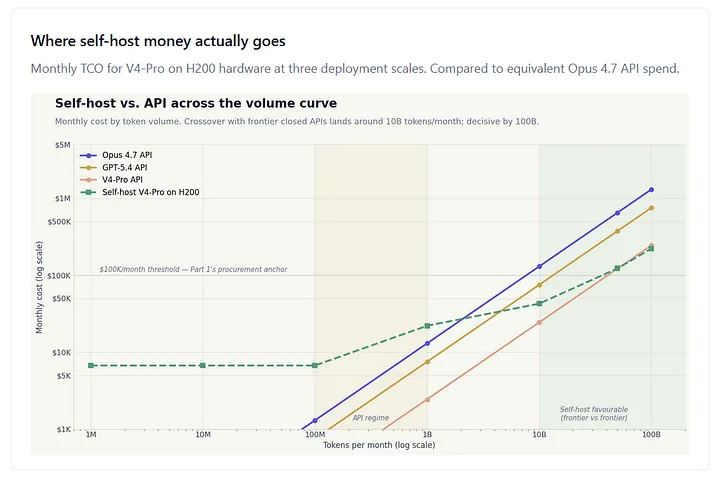
Figure 4. Monthly TCO composition for self-hosted V4-Pro on H200 hardware at three deployment scales. CapEx amortized straight-line over 36 months. MLOps headcount scales 2 → 4 → 6 FTE at $120K/yr fully loaded. Network/storage/software lines absorb residual operating cost (rack space, NVLink fabric, software licensing, monitoring infrastructure). Comparison annotations show equivalent Opus 4.7 API monthly spend at the same token volume.
The TCO model in the underlying research is calibrated on these assumptions at three scales:
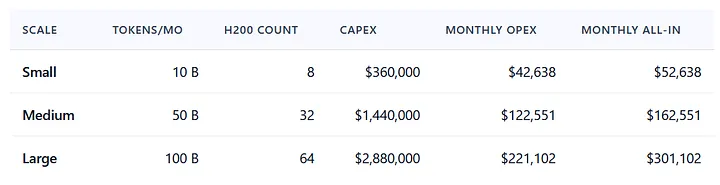
CapEx amortized straight-line over 36 months. Monthly OpEx includes power, cooling, networking, software, and 2/4/6 FTE MLOps headcount at $120,000/year fully loaded, scaled by deployment size. Monthly all-in is the right comparison number against API monthly spend; OpEx-only is the right number for cash-flow modeling once the hardware is paid down.
Against frontier closed-source APIs at the same volume — Claude Opus 4.7 at $5/$25, blended around $13 per million on a 60/40 input-output mix — the comparison is decisive at the top of the volume range and unfavorable at the bottom:
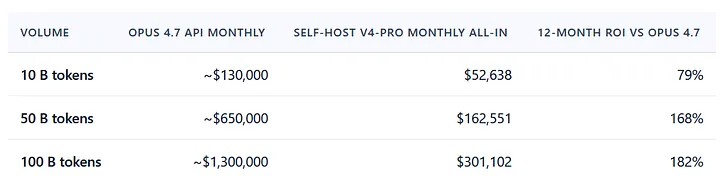
ROI calculated as (Year-1 Opus 4.7 API spend − Year-1 self-host total cost) / Year-1 self-host total cost, where Year-1 self-host = CapEx + 12 × monthly OpEx. Steady-state ROI after CapEx amortization is materially higher; see body for the $12M/year figure at the 100B scale.
At 100 billion tokens per month, the year-one net cash benefit against the like-for-like frontier closed API is roughly $10.1 million — that figure is computed against the full $2.88M CapEx hit upfront, plus 12 months of OpEx, against 12 months of API spend. On the steady-state, amortized monthly comparison the piece carries elsewhere — $1.3M Opus monthly minus $301K self-host monthly — recurring annual savings work out to roughly $12.0 million. Both figures are correct in their respective accounting frames; the $10.1M number is right for first-year cash budgeting. The $12.0M number is right for ongoing budget forecasting once hardware is in place. The H200 cluster CapEx pays for itself in approximately three months at this run rate.
The same comparison against GPT-5.4 (cheaper than Opus 4.7 at $2.50/$15) is materially less dramatic — the ROI stays positive across every volume modeled here, but the gap that justifies the operational complexity of self-hosting really only opens up at the high-volume frontier-model comparison, not against mid-tier closed-source pricing.
A separate cloud-rental pathway eliminates the CapEx requirement entirely. Committed-use H200 pricing on CoreWeave and Nebius runs around $2.30/hour per GPU as of early May 2026, which is $1,679/month per H200. At 10 billion tokens monthly, an 8-GPU rental cluster runs about $55,800/month plus personnel — somewhat more than owned hardware on a per-month basis, but with no upfront CapEx. ROI against Opus 4.7 still lands at 132% twelve-month, against GPT-5.4 at 34%. For organizations that cannot or will not commit capital, cloud rental keeps the open-weight frontier economically rational at every scale considered.
Where the Breakeven Sits
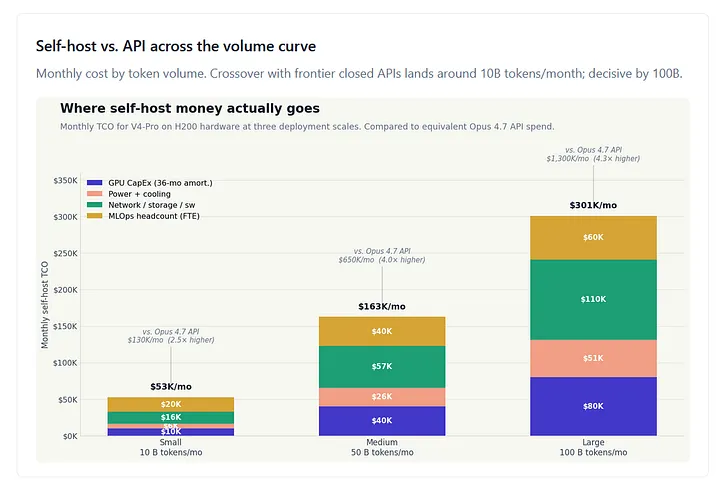
Figure 5. Monthly cost by token volume for three frontier APIs (Opus 4.7, GPT-5.4, V4-Pro) and self-hosted V4-Pro on H200 hardware. Both axes log scale. The self-host curve starts flat — fixed overhead at low volume — and tracks linearly at high volume as additional GPUs are added. The crossover with Opus 4.7 sits between 1B and 10B tokens/month; with GPT-5.4 between 10B and 50B; against DeepSeek’s own V4-Pro API, self-host never wins at the volumes shown.
The published case-study literature (SitePoint’s Self-Hosted LLM Costs 2026, Spheron’s On-Premise vs GPU Cloud 2026 Break-Even Analysis, DigitalApplied’s Self-Hosting Frontier AI Models 2026 TCO, Lenovo’s formal Token-Economics framework, OpenMalo’s True Cost of Running Your Own LLM) converges on three breakeven thresholds once full TCO including personnel is included.
Below ~100 million tokens per month
APIs are almost always cheaper after accounting for full TCO. The fixed costs of self-hosting — minimum hardware footprint, minimum engineering headcount, minimum operational overhead — don’t amortize across the volume. A startup at 5 million tokens monthly that moves from Claude API to a self-hosted Llama-class model can find nominal savings on the per-token bill, but if the deployment requires even 0.5 FTE of DevOps attention, the math reverses. This is the regime where the closed-source operational simplicity argument is at its strongest.
Between roughly 100 million and 10 billion tokens per month
Hybrid architectures dominate. The pattern that has emerged as the production default — and the one Prem AI’s fintech case study describes when it documents an 83% monthly-cost reduction (from $47,000 to $8,000) — is to route the bulk of volume to a self-hosted open-weight model and reserve the closed-source API for the top 10–15% of queries that genuinely need frontier capability or specific operational guarantees. Hybrid cuts AI infrastructure costs by 40–83% in published case studies without sacrificing the capability ceiling on the workloads that need it.
Above approximately 10 billion tokens per month
Self-hosting at the frontier tier wins outright, and the curve gets steep fast. At 100 billion tokens monthly — the volume serious enterprise AI deployments are now reaching — self-hosting V4-Pro on H200 hardware costs roughly $301,000/month all-in with CapEx amortized over 36 months, or $221,000/month on OpEx alone after the hardware is paid down. Against the equivalent Opus 4.7 API spend at roughly $1.3 million/month, the all-in monthly savings are about $1.0 million. The $2.88M cluster CapEx pays back in approximately three months at this run rate.
Three caveats, and the third is the one most procurement teams underweight.
First, against DeepSeek’s own V4-Flash API ($0.18 blended), self-hosting is never economically justified. The Flash API is cheaper than self-host TCO at every scale considered, because DeepSeek is essentially passing through hardware-efficiency gains directly to the customer. The economic case for self-hosting is specifically against frontier closed-source APIs — not against the open-weight provider’s own commercial endpoints.
Second, V4-Pro’s own API at $1.74/$3.48 list pricing (roughly $2.44 blended at a 60/40 input-output mix) is similarly aggressive. At 10 billion tokens monthly, the V4-Pro API costs roughly $24,400/month against $52,638 monthly all-in for self-hosting; at 50 billion, $122,000 vs. $162,551 — essentially break-even; at 100 billion, $244,000 vs. $301,000. Self-hosting V4-Pro becomes cheaper than V4-Pro’s own API only at high volume combined with longer (36-month) deployment horizons and modest amortization favorability. One pricing context worth flagging: as of early May 2026, DeepSeek is running a 75% promotional discount on V4-Pro through May 31, 2026, putting effective pricing at $0.435/$0.87 ($0.61 blended). At promotional pricing, the gap to closed-source frontier APIs widens by another 4×, and self-hosting V4-Pro becomes economically uncompetitive against the V4-Pro API at every volume. Promotional pricing is, by definition, unstable; the list-price comparisons in this section are the conservative procurement-defensible numbers. Data residency, audit, and compliance considerations remain valid drivers for self-hosting at any volume — the per-token economic case against the open-weight vendor’s own API is much narrower than against the frontier closed-source APIs.
Third — and this is the one most worth internalizing
The entire framing assumes you actually need V4-Pro-class capability. A lot of production traffic doesn’t. If V4-Flash, or a smaller open-weight model, handles your workload at adequate quality, the relevant comparison isn’t against the frontier-tier closed-source rate card at all. It’s against the cheapest commercial endpoint that meets your spec. That reframe alone is the highest-leverage cost reduction available in most enterprise AI stacks today, and it doesn’t require self-hosting anything.
What the bill looks like — across tiers and discount scenarios
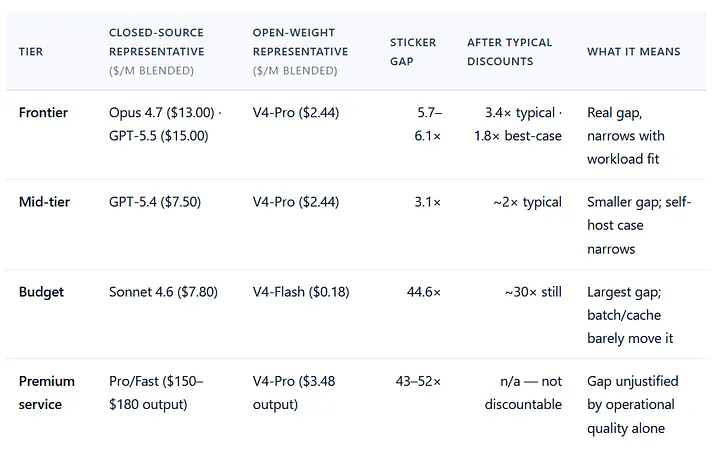
Blended rates use a 60/40 input-output token mix. Frontier sticker ratio (5.7×) and budget ratio (44.6×) follow the methodology in the underlying research paper. Premium service ratio is on output rate; no open-weight equivalent exists at this tier — self-hosting is the open-weight analogue. Discount estimates assume batch (−50%) where applicable plus cache discounts (−50% to −90%) on cached portions only; see the discount-stack figure above for the full compression curve at the Frontier tier.
Three Questions for the Next 90 Days
In operator terms: a procurement team looking at the rate card sees a clean spreadsheet — input price, output price, committed volume. The engineering bill tells a messier story. Cached prefixes on Monday, uncached RAG on Tuesday, reasoning-heavy escalations on Wednesday, and a model upgrade somewhere in the middle that changes token counts without changing the quoted rate. The same workload, billed against the same nominal price card, can land 30% above forecast or 20% below depending on which combination of those effects dominates that month. The questions below are about closing that gap.
If you are responsible for AI procurement at any organization spending above $100,000 a month on frontier-tier AI tokens — roughly six to seven billion tokens of monthly volume at $15–17.50 per million blended — three questions are worth answering this quarter, and each maps to a specific section above.
Are We Measuring Cost Per Task, Or Cost Per Token?
The rate card has stopped being a usable cross-model cost estimator. Most enterprise procurement teams are still negotiating against per-million-token figures because that’s the number on the contract. The number that matters for budget forecasting is dollars per completed task on your actual workload mix — input tokens consumed, output tokens generated (including reasoning tokens billed but not displayed), tokenizer-adjusted, with cache and batch discounts applied where applicable. For most enterprises, this calculation has never been done. It can be done in two weeks with a representative sample of production traffic, and it tends to surprise procurement teams in both directions: some workloads cost less than the rate card implies, and some cost considerably more.
Have We Modeled the Breakeven At Our Current Volume?
The thresholds in the section above are convergent across the published TCO literature, but they are sensitive to specific workload composition, MLOps maturity, and cost-of-capital assumptions. At ten billion tokens per month, self-hosting frontier open-weight on H200 hardware is favorable but not overwhelming — a credible operations team might run that workload either way. At a hundred billion tokens per month, it is decisive. Most enterprises have not modeled where on that curve they sit, partly because the assumption that the gap was “too large to bother modeling” is the same assumption that anchored the procurement default before the open-weight frontier closed.
What Workloads Are Routed Through the Most Expensive Tier When the Cheapest Tier Would Do?
This is the single highest-leverage question for any enterprise that uses multiple models. The most common pattern in production AI deployments is that everything runs through whichever endpoint the team integrated first — often Opus or GPT-5.x — regardless of whether the workload needs frontier capability. Customer-support classification, content tagging, simple retrieval-augmented generation, document summarization, and code completion on common patterns are all workloads where mid-tier or budget-tier models perform within rounding distance of frontier models, at 5–50× lower cost. A workload audit that classifies production traffic by capability requirement and routes accordingly typically uncovers more savings in two weeks than any contract renegotiation will. Most enterprises haven’t run one.
What This Isn’t
A few things this argument isn’t, since the framing is sharp enough to invite misreading. The closed-source vendors aren’t being systematically dishonest; the rate-card distortions described above are mostly structural artefacts of how reasoning models, tokenizer changes, and tier fragmentation interact, not deliberate concealment. Most enterprises also shouldn’t be self-hosting — at most volume bands they really shouldn’t, and the breakeven analysis above makes that explicit. And batch and cache discounts genuinely matter on the workloads they fit; any honest comparison includes them.
The argument is narrower. Per-token rate cards have stopped being a usable cost-estimation tool for cross-model procurement. Cost per completed task on a fixed harness is the unit that maps to the bill. Self-hosting at hyperscaler volume changes the cost structure decisively. And the Pro/Fast tier — at 43–52× the V4-Pro standard rate on output — sits structurally outside any defensible operational-quality premium. Take those three together and the procurement defaults that survived the 2023–2024 era are now actively misaligned with the underlying economics.
One nuance to that arithmetic: the +22.6% earlier assumes the 40% Codex token reduction OpenAI cited applies to the 800-input shape modeled. One independent measurement that landed after this piece was drafted suggests it doesn’t. OpenRouter’s switcher-cohort analysis of users who moved from GPT-5.4 to GPT-5.5 found that the 40% output-token reduction only applies at long prompts (above 10K tokens, where GPT-5.5 produces 19–34% fewer tokens). At medium prompts (2K–10K), GPT-5.5 produces 52% more tokens. At short prompts (under 2K — which is where this section’s 800-input arithmetic sits), completion lengths are roughly unchanged. If the OpenRouter measurement is right and your workload is short-prompt-dominated, the GPT-5.5 paradox is not +20% but closer to +90–100%, because the 40% token reduction simply isn’t there. The waterfall arithmetic earlier is the floor of the cost increase under OpenAI’s own claim, not the ceiling.
What would change this conclusion is the falsification condition spelled out earlier: a credible, independent measurement of per-completed-task costs across mixed enterprise workloads (RAG, extraction, classification, support, document analysis — not only coding) showing GPT-5.5 or Opus 4.7 within rough range of V4-Pro after accounting for tokenizer and reasoning effects. That measurement does not currently exist in the public record. If it appears, the rate-card framing this piece runs needs to be reworked. Until then, the burden of proof sits on the premium.
Where This Leaves Us
The performance argument that closed-source vendors leaned on through 2024 has, on the published numbers, narrowed to a workload-specific 0–7 percentage points on the public benchmark suite Part 1 covered. The pricing argument that came next — that the operational simplicity, support, and integration polish of a managed API justify the premium — has narrowed too, once you look at what the rate card maps to in the bill. At standard tier, after thinking-token inflation and tokenizer drift, the frontier closed-API premium is something like 3–4× over the open-weight frontier on real workloads. At Pro/Fast tier it’s 43–52×. At hyperscaler self-host volumes it’s nearly two orders of magnitude.
Which leaves the third leg of the closed-source argument: the legal and political moat. Anthropic’s $30 billion Series G at a $380 billion valuation on February 12, 2026 — followed eleven days later by the company’s disclosure that DeepSeek, Moonshot AI, and MiniMax conducted “industrial-scale distillation campaigns” against Claude, then by White House OSTP memo NSTM-4 on April 23 framing distillation as a national-security concern — has reframed the conversation in a way that has nothing directly to do with model capability or pricing. Part 3 takes that argument apart. Whether the legal claims hold under U.S. copyright law as it stands. Whether the volume math behind the “industrial-scale” framing supports the headline. Whether the timing — funding round, then corporate disclosure, then federal policy memo, all within 70 days — describes a coordinated security response or a coordinated commercial-protection strategy. Whether it matters which.
DeepSeek leads the coverage. It is also under 1% of the disclosed exchange volume.
That installment is next.
Sources
Reasoning-token cost and chain-of-thought efficiency
The 8× o1 vs GPT-4o token multiplier is the original measurement, published by Artificial Analysis in October 2024, using a fixed seven-benchmark evaluation suite ($109 vs $2,767 to evaluate the same workload). The thinking-token multiplier table draws from current vendor documentation: DeepSeek-V4 technical report §5.3.2 for V4-Pro reasoning effort tiers (April 2026); Anthropic Claude Opus 4.7 model card and platform.claude.com pricing documentation for adaptive thinking; OpenAI o1 pricing documentation. The academic context for whether reasoning tokens deliver proportional accuracy comes from Tomlinson, Schnabel, Swaminathan, and Neville, “Reasoning about Reasoning: BAPO Bounds on Chain-of-Thought Token Complexity in LLMs,” arXiv preprint, February 4, 2026, which proves Ω(n) lower bounds on CoT token count for canonical BAPO-hard tasks (with attention compute superlinear on top); Lee et al., “How Well do LLMs Compress Their Own Chain-of-Thought? A Token Complexity Approach,” arXiv:2503.01141, March 2025, which finds 30–50% length compression with bounded accuracy loss; and the LeapNonprofit “Scaling for Reasoning” survey (December 2025) on test-time-scaling market dynamics.
Tokenizer drift on Opus 4.7
Anthropic platform documentation, accessed May 2026 (platform.claude.com/docs/en/about-claude/pricing), explicitly acknowledges “this new tokenizer may use up to 35% more tokens for the same fixed text.” FinOps-platform analysis on production workloads from Finout, “Claude Opus 4.7 Pricing 2026: The Real Cost Story Behind the ‘Unchanged’ Price Tag” (May 2026); also Finout, “Anthropic API Pricing in 2026: Complete Guide” (April 29, 2026). Both pieces walk through three production workloads showing 18–28% effective cost increases at constant input.
GPT-5.5 paradox arithmetic and per-task cost methodology
OpenAI launch announcement, “Introducing GPT-5.5,” April 23, 2026 — source of the 40% Codex output-token reduction figure. Vellum.ai, “Everything You Need to Know About GPT-5.5,” April 2026, walks through the +20% net cost arithmetic independently. The broader per-task measurement framework — and the observation that “LLM pricing tables lie” until you measure cost per successful task — is articulated cleanly in Grizzly Peak Software, “LLM Provider Pricing in 2026: What It Actually Costs Per Task” (February 2026), which provides a Node.js benchmarking harness for measuring it. Pricing data cross-referenced with BenchLM.ai’s “LLM API Pricing Comparison 2026” (March/April 2026 update), CostGoat’s “LLM API Pricing Comparison & Cost Guide” (May 2026), and Inference.net’s “LLM API Pricing Comparison 2026: 30+ Models” (February 2026).
Falsifiability framing on GPT-5.5
OpenAI launch material as above. MindStudio third-party comparison, “GPT-5.5 vs Claude Opus 4.7: Real-World Coding Performance Compared” (April 2026) — the 72%-vs-Opus token-reduction figure, supported by their illustrative math (2,000 GPT-5.5 tokens vs ~7,100 Opus 4.7 tokens on equivalent 500-task-per-day pipelines); cross-referenced across multiple MindStudio comparison pieces published April–May 2026. FundaAI Substack 38-task benchmark, “DeepSeek V4 vs Claude vs GPT-5.4” (April 2026), supports the qualitative finding that V4-Pro produces denser output than Claude on coding and analytical workloads. Caveat on FundaAI: the published quantitative comparison mixes units (output tokens for DeepSeek vs character counts for Claude), which complicates direct numerical claims; the qualitative density observation is consistent with other reviewers, but the specific token-count comparison should be re-run with consistent units before being treated as load-bearing. All cited figures are scoped to coding workloads as of early May 2026; no published replication on RAG, extraction, classification, or document-analysis workloads. This footnote fulfills the per-task falsifiability commitment made in Part 1, footnote [14].
Self-host TCO and breakeven thresholds
Hardware pricing converges across multiple recent surveys: SitePoint, “Self-Hosted LLM Costs 2026” (March 13, 2026) — H200 on-demand $4.50–$6.00/hr at hyperscalers, $3.50–$4.50/hr at neoclouds; Jarvis Labs, “NVIDIA H200 Price Guide 2026” (April 2026) — $30,000–$40,000 outright purchase, $3.72–$10.60/hr cloud; Introl Local LLM Hardware Guide (December 2025 update) — $40,000–$55,000 channel-partner pricing for H200; Julien Simon, “What to Buy for Local LLMs (April 2026),” Medium — $3.00–$4.00/GPU-hr H200 confirmed across providers. Breakeven analysis from DigitalApplied, “Self-Hosting Frontier AI Models: 2026 TCO Analysis” (April 2026) — finds ~600M tokens/month for code workloads, ~1.2B for chat; OpenMalo, “The True Cost of Running Your Own LLM in 2026” (November 2025) — anchors breakeven at 35–50M tokens/month for Llama-class on prosumer hardware, scaling to 500M+ for high-volume regimes; Spheron, “LLM Inference On-Premise vs GPU Cloud: 2026 Cost and Break-Even Analysis” (April 2026) — adds the staffing cost dimension (engineer time as the largest 3-year line item, larger than hardware itself); Lenovo Press, “On-Premise vs Cloud: Generative AI Total Cost of Ownership (2026 Edition)” (February 2026) — the formal Token-Economics framework cited in §7.1 of the underlying research; Introl, “Cost Per Token Analysis: Optimizing GPU Infrastructure” (January 2026) — for the per-token compute economics. ROI calculations use straight-line 36-month CapEx amortization; alternative depreciation schedules shift the numbers but not the qualitative conclusion at hyperscaler volume.
Batch and cache discount mechanics
Anthropic platform documentation (May 2026): cache hit at 0.10× standard input rate (90% discount), cache write at 1.25× for 5-minute TTL or 2.0× for 1-hour TTL, batch API at 50% discount on both input and output. OpenAI published rates: 50% cache discount on cached input, 50% batch discount. TokenMix.ai, “Prompt Caching Guide 2026: Save 50–95% on AI API Costs” (April 2026) compiles the cross-provider comparison: OpenAI 50% cache discount, Anthropic 90%, Google 75%, with stacked cache + batch reaching 95% off on Anthropic Sonnet 4.6. DeepSeek’s lack of a separate batch endpoint, with off-peak pricing as the operational equivalent, confirmed against DeepSeek API documentation, accessed May 2026.
Disclosure & methodology notes
Snapshot dates
Pricing figures reflect vendor rate cards as of early May 2026; reasoning-token multipliers reflect Artificial Analysis measurements through April 2026 plus the Q1 2026 academic literature on chain-of-thought token complexity; self-host TCO figures reflect H200 hardware pricing as of early May 2026 across multiple converging supplier surveys. These figures shift quarterly. Procurement decisions taken months after publication should re-verify the headline numbers against the current state of those sources.
Source quality tiers
Sources in this piece carry different evidentiary weights. Primary vendor documentation (OpenAI, Anthropic, DeepSeek release notes and pricing pages) and academic preprints (arXiv) are the strongest evidence for pricing and capability claims. Independent benchmarkers (Artificial Analysis, Vellum) and major analyst publications (Stanford AI Index, Epoch AI) carry strong but secondary weight. Industry analyses and case-study writeups from infrastructure providers (SitePoint, Spheron, DigitalApplied, Lenovo Press, Finout, Jarvis Labs) provide useful corroboration on practitioner-level numbers but are not load-bearing on their own; they are cited where they converge across multiple sources. Substack analyses, vendor-comparison shop content (MindStudio, BenchLM, CostGoat, TokenMix, Inference.net), and developer-community commentary appear as observational support, not primary evidence. The FundaAI 38-task Substack benchmark is illustrative-only — its qualitative finding is consistent with other reviewers, but its specific numerical comparison mixes units and should not be cited as a primary measurement.
No vendor relationships
The author has no consulting, advisory, equity, or commercial relationship with any of the labs, hardware vendors, cloud providers, or analytics shops named in this piece. No vendor or provider has reviewed or commented on this draft.
Methodology
Per-task cost calculations assume the workload shapes specified in each example (typically 800 input + 4,000 visible-output tokens for coding workloads). Real workloads vary; the example shapes are representative of published benchmarking traffic but not universal. Self-host TCO assumes the personnel and operational overhead specified explicitly; deployments with materially different MLOps maturity will see different breakeven points. The 5.7× frontier ratio carried forward from Part 1 is rate-card blended at 1:1; real workloads, weighted toward output (most coding, most agentic tasks), shift the ratio toward an output-rate ratio of 7.2×.


















