When AI agents can visually capture functionality and rebuild it from scratch, where do the IP boundaries actually lie? And what does it mean for your next platform migration?
The Premise: Two Agents, One Wall, Zero Code Sharing
I fell into malus.sh during a late-night rabbit hole — the kind where you start with one tab and end up with thirty. By the time I finished reading Nolan’s blog post, I had two reactions. First: this is going to break open source. Second: wait — could we use the same technique to migrate our own platform configurations? The legal question between the two use cases became the entire article.
In March 2026, a service called Malus started charging for something that made many engineers very uncomfortable: you upload your dependency manifest, and their AI agents rebuild every package from scratch under a license that owes nothing to the original. No attribution. No copyleft. No obligations. They call it “liberation.”
The question underneath is older than it looks: if one AI agent reads public documentation and produces a specification, and a completely separate agent implements that spec without ever touching the original code, have you violated anyone’s intellectual property?
Clean room engineering has been doing something like this with humans since the 1980s. What changed is that AI collapsed the cost from months and teams to minutes and tokens. That speed is what makes this feel different. It’s what forces engineering leaders on both sides of the equation to actually think about where the legal lines are.
This piece walks through the legal foundations, where they hold up, where they crack under the weight of AI, and what the practical options look like if you’re considering building from observed functionality, or trying to protect your own platform from someone who is.
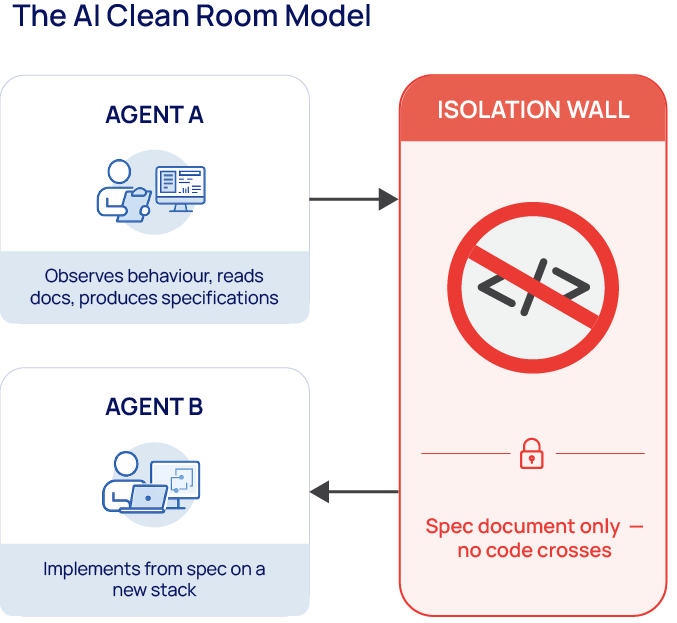
Figure 1: AI Clean Room Model
The Legal Foundations: What Actually Holds Up
Malus’s pitch rests on a chain of legal precedents, each forged before AI existed. Some of these links are solid. Others are being stress-tested in ways their authors never imagined. Knowing which is which matters if you’re going to make real decisions based on any of this.
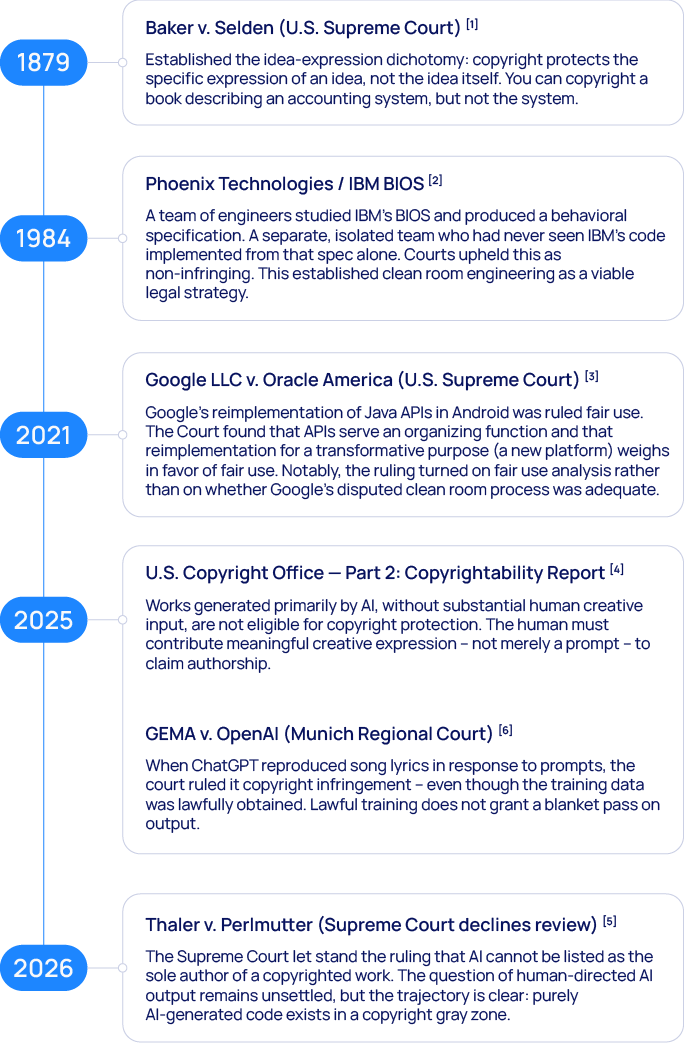
Infographic 1: Legal Foundations
Key Insight
Most engineers get this backwards: clean room engineering is not a legal requirement. It’s a litigation strategy. The actual legal test is simpler — did you produce a derivative work? Clean room procedures just make it much easier to prove you didn’t. If you independently created something, that’s a complete defense to copyright infringement, formal clean room or not.
Malus: The Provocation That Made It Real
Earlier this year, developers Dylan Ayrey and Mike Nolan gave a talk called “The Death of Open Source,” then backed it up by launching Malus — a service billing itself as “Clean Room as a Service.” The pitch is blunt: upload your dependency manifest (package.json, requirements.txt, whatever), and their AI agents will independently recreate every package from scratch. You get the result under their proprietary-friendly MalusCorp-0 License. Zero attribution. Zero copyleft. Zero obligations.
How it works: one set of AI agents examines only public-facing documentation (READMEs, API specs, type definitions) and produces a specification. No code in the spec. Then a completely separate set of agents, with no connection to the first, is implemented from that spec. The two sets never talk to each other. The result ships under Malus’s MalusCorp-0 License.
The whole site is dripping with irony. Fake testimonials from “Marcus Wellington III” of “Definitely Real Corp” and “Patricia Bottomline” of “MegaSoft Industries.” A legal guarantee that promises to “relocate our corporate headquarters to international waters” if infringement is found. You read it and think, ‘This has to be satire.’ And it is. But they also take your money and ship you code. That’s where the joke stops being funny.
What Malus Actually Claims
Nolan’s blog post doesn’t dance around it. Clean room engineering has been legal since 1879. Phoenix Technologies used it with two human engineers over four months to clone the IBM BIOS. Malus does the same thing with AI agents in under five minutes. His line: copyright was the immune system that made open-source licenses enforceable. Their machines “walk straight through it.”
Where Malus Gets the Law Right
Give them credit for the legal foundation. It’s real. Copyright protects expression, not ideas or functionality. Write your own code that does the same thing as someone else’s, without copying their actual code, and you haven’t infringed. That’s been true since Baker v. Selden in 1879, and Google v. Oracle reinforced it in 2021. The idea-expression dichotomy isn’t a loophole. It’s a foundational copyright doctrine.
Malus also has the economics right: enterprises really do spend millions a year on open-source compliance: SCA tooling, OSPOs, legal reviews, CLA administration, emergency response when some maintainer they’ve never heard of has a bad week. If you could make all of that go away, the ROI case writes itself.
The Supply Chain Argument
The part of Nolan’s blog post that actually lands is the supply chain case. He walks through a timeline that most engineering leaders will recognize: left-pad breaking the internet in 2016, Log4Shell ruining everyone’s Christmas in 2021, the colors.js maintainer protesting corporate exploitation by sabotaging his own packages in 2022, the node-ipc package deciding to conduct its own foreign policy via file-wiping payloads, and the Shai-Hulud 2.0 npm worm spreading through compromised packages in 2025.
Nolan’s distinction between accidental and deliberate failures is sharp. The accidental ones are scary enough. The deliberate ones are worse, he argues, because they reveal something the community would rather not think about: the people writing your dependencies have opinions, grievances, and leverage, with no contractual obligation to exercise restraint. Your whole product sits on top of an arrangement with no SLA.
Fair point. But here’s where Malus plays a sleight of hand: the supply chain problem (which calls for better dependency management, vendoring, and auditing) is a different problem from the licensing problem (which calls for… stripping licenses?). They’re bundling a real security concern with a much more questionable IP maneuver and hoping you won’t notice the seam.
The Economics of “Free”
Malus’s most commercially effective argument is economic. Their blog post estimates that an average enterprise with 500+ engineers spends approximately $4 million annually on open-source compliance: $1.2M on SCA tooling (Snyk, Black Duck), $850K on OSPO staffing, $700K on legal review, $980K on incident response, and $270K on CLA administration. Against this, they position their “Total Liberation Package” at $50K per year — a claimed 98.75% cost reduction. These are Malus’s own figures, from a company with an obvious incentive to make the compliance burden look as painful as possible. Take them as directional, not gospel.
For individual package liberation, their pricing is $0.01 per kilobyte of the original package’s unpacked npm size, with a $0.50 minimum per order. Liberating lodash costs $13.80. Liberating express costs $0.73. Liberating is-number costs a minimum of $0.50.
Whether those numbers are real or inflated for effect, they point to something true: open-source compliance has gotten expensive. Really expensive. And when someone shows up offering to make that cost disappear for $50K, people are going to listen — which is exactly why the legal and ethical questions can’t be hand-waved away.
What Malus Gets Wrong — or Where the Argument Breaks Down
Copyright analyst Jonathan Bailey’s review in Plagiarism Today puts a pin in Malus’s central sales pitch — the claim that you’ll “own” the liberated code outright. Under current U.S. law, that’s wrong. AI-generated works without substantial human creative input can’t be copyrighted. The output is effectively unprotectable under current guidance from the Copyright Office. You can use it, sure, but you don’t own it in any enforceable sense. Anyone else can too.
More telling is what Nolan admits in his own blog post. When he gets to the objection that the open-source commons will wither if AI can trivially sidestep its protections, he doesn’t push back. He writes: “This is, I concede, probably true.” Then he argues the commons was broken anyway — maintainers burning out, critical infrastructure hanging by a thread on the backs of unpaid individuals, the social contract between users and contributors being honored in bad faith. His real position: this was going to happen regardless, so why shouldn’t we be the ones making money from it?
That concession is worth sitting with. Malus isn’t claiming that what they do is harmless. They’re claiming the harm is inevitable and monetizing the transition. That’s a business argument, not a legal one — and it won’t help much if a judge decides the output is a derivative work.
There’s also the question of what’s under the hood. Malus doesn’t disclose which LLMs power their agents or what training data those models ingested. That’s not a footnote. It’s the entire crux of whether the clean room analogy holds. If the implementing agent was trained on the code, it’s “independently” recreating, the isolation isn’t real. It’s theater.
And then there’s the scope problem. Malus talks exclusively about copyright and ignores everything else: patents, trade dress, trade secrets, and contractual restrictions. For a small npm utility, copyright might be the only protection that matters. For a commercial software platform? It’s usually the least important layer.
Where the Precedents Fracture: The AI-Specific Complications
All those precedents were set in a world where the “clean room implementer” was a human being who could raise their right hand and swear they’d never seen the original code. Swap in AI agents and the analogy starts to wobble. The training data issue is the one I keep coming back to
The Training Data Problem
When Phoenix cloned the IBM BIOS, the implementing team had genuinely never laid eyes on IBM’s code. That’s what made the clean room work — actual, verifiable ignorance. Today’s LLMs have been trained on effectively all of GitHub. For any popular project, the original source code is almost certainly baked into the model weights. The implementing agent hasn’t “never seen the original.” It’s seen the original countless times, folded into billions of parameters.
Think about what that does to the analogy. It’s like having two teams meet in a “clean room” after both of them spent the previous night studying the source code. The wall between them is real. The ignorance is not. This came up immediately in the chardet controversy: critics pointed out that Claude, the tool used for the rewrite, was almost certainly trained on the very LGPL codebase it was “independently” reimplementing. The maintainer didn’t seriously dispute it. He argued it didn’t legally matter.
I’ve gone back and forth on whether the training data issue is a genuine legal vulnerability or just a credibility problem. Whether courts will care is genuinely unclear — the doctrine of independent creation predates machine learning by decades and there’s no precedent squarely on point. Honestly, I’m not sure the distinction holds. The “our AI never saw the original” defense is going to become harder to make with a straight face as models get larger and training datasets more comprehensive — and in litigation, credibility problems and legal exposure tend to collapse into each other pretty quickly.
What You Get Back Might Not Be Yours
The irony Malus doesn’t dwell on. Under current U.S. Copyright Office guidance, AI-generated works without substantial human creative input can’t be copyrighted. So you might successfully strip someone else’s license off a package — only to receive code that has no enforceable copyright of its own. Anyone can copy it, including your competitors. Malus’s whole pitch is that you’ll “own” the liberated code. Under the 2025 Copyright Office report and the trajectory set by Thaler v. Perlmutter, you might own nothing you can enforce. You’ve paid to strip a license and received a public-domain deposit. That’s not ownership — it’s just a receipt.
What Counts as a Derivative Work?
When Agent A reads copyrighted code and produces a specification, is that spec already a derivative work? When Agent B implements from the spec, is the result a derivative of the original? No court has answered this. It probably comes down to what the spec actually says. Business-level behavior — inputs, outputs, rules — is the kind of functional content Baker v. Selden holds can’t be copyrighted. But if the spec carries structural organization or naming conventions from the source, the argument for derivative work strengthens. Bailey notes in his Plagiarism Today piece that code gets narrower protection than fiction: you can’t copyright what code does, only how it does it. That’s why this argument works better for software than for, say, rewriting a screenplay. “Works better” still isn’t “settled.”
The Paper Trail You Didn’t Mean to Leave
If you ever end up in court, one of the worst things you can have on the record is a blog post from your tool vendor explaining that the entire purpose of the service is to circumvent open-source licenses. Nolan’s essay doesn’t hedge — he describes the business as extracting ideas from open source while leaving behind the people who built it, and he owns that framing. Admirably honest. But honesty about intent is exactly what establishes willfulness in a copyright dispute, and willfulness changes the damage calculation substantially.
Engineers tend to think about legal compliance the way they think about a compiler: correct procedure, correct output, done. Courts look at the whole picture: the preponderance of circumstances, the stated purpose of the tools used, and what the vendor was advertising when you signed up. “I used a service whose entire marketing pitch is license circumvention” is not a sentence that lands well before a judge, regardless of whether the technical procedure was clean.
Real-World Test: The chardet Relicensing
Malus might be partly performance art. But the underlying practice had already surfaced in production. In March 2026, the maintainer of chardet (a Python character encoding library depended on by pip and thousands of other projects) shipped version 7.0.0 as a complete rewrite under MIT, replacing the LGPL codebase. He used Claude Code. It took roughly five days.
Mark Pilgrim, the original author, filed a GitHub issue: “No right to relicense this project.” His argument: the maintainer had deep familiarity with the LGPL code, and Claude was almost certainly trained on that codebase. This was no clean room.
The community split almost immediately. One camp: clean room is a litigation tactic, not a requirement: if the code is genuinely different, there’s no infringement. The other camp: the rewrite kept the same API, same package name, same pip namespace, and was shipped as “chardet v7.0.0” rather than a new project, which makes it look like a continuation, not an independent creation. Plagiarism detection tools showed low textual overlap — Blanchard cited JPlag results showing under 2% structural similarity — but matching class names, variable names, and method signatures kept surfacing in the discussion.
I went through the GitHub thread — all 373 comments, which took longer than I expected. A lot of it is the same three arguments cycling back, and the exchanges worth reading are buried roughly two-thirds in, after a long detour into pip packaging philosophy that isn’t really the point. But they’re there: the people arguing most confidently in either direction are largely the ones with the least at stake. The actual maintainer and the actual original author are, by the end, talking past each other in a way that doesn’t resolve. No lawsuit yet as of this writing. But the chardet episode is the first time this stopped being theoretical. Whoever files the first suit sets the precedent, and right now both sides are probably hoping the other one blinks.
I’ll admit something: I went into this section thinking the training data contamination argument was the strongest objection to the whole clean room model. Having actually read through the thread, I’m less sure. The independent creation defense is more resilient than I gave it credit for — not because it’s settled, but because courts have applied it flexibly before, and there’s enough genuine ambiguity to argue both sides with a straight face. The chardet case may resolve that ambiguity. Or it may settle quietly and leave the question open for another few years.
A Signal from Europe: GEMA v. OpenAI
One early judicial signal, not from the U.S., but instructive. In November 2025, the Munich Regional Court ruled in GEMA v. OpenAI that when ChatGPT reproduced song lyrics in response to prompts, it counted as copyright infringement. Even though the training data was lawfully obtained. The court drew a line: scraping data for training may be permissible under text-mining exceptions, but when the model memorizes and reproduces specific copyrighted content in its output, the training provenance doesn’t save you.
This doesn’t directly address code reimplementation, but the principle it sets is worth paying attention to: legal training doesn’t mean legal output. If a model’s output looks too much like something it was trained on, the fact that training was lawful won’t immunize the output. For anyone relying on the “our robots never saw the source code” defense, the GEMA ruling suggests that defense has a shelf life.
Beyond Copyright: The Full IP Stack
Almost every conversation about AI clean room engineering gets stuck on the issue of copyright. That’s a mistake. Copyright is one layer of protection, and for most commercial software platforms it’s probably the weakest one. If you’re only thinking about copyright, you’re looking at maybe a third of the actual risk surface. The patent row in the table below is the one that should genuinely unsettle most engineering teams. Clean room helps with none of it.
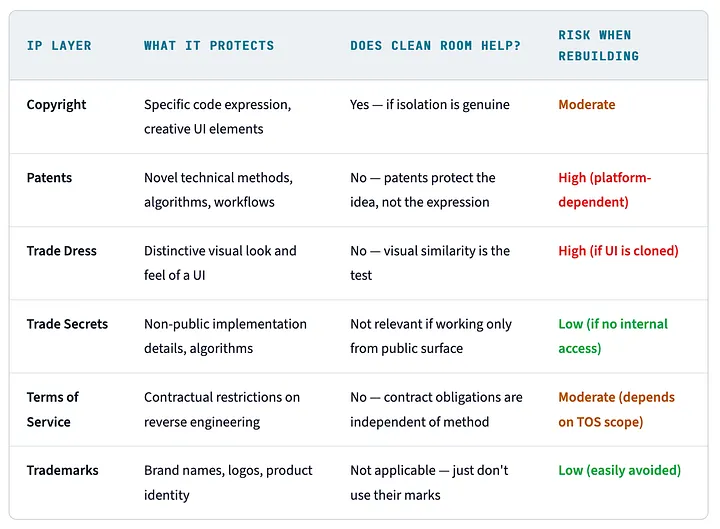
Table 1: The Full IP Stack
Critical Warning for Engineering Leaders
If your legal analysis of a rebuild project starts and stops at copyright, you’ve covered a third of the risk. Patents and trade dress are where the real litigation comes from. Well-funded platform vendors have armies of patent lawyers, and no clean-room procedure helps with either.
The Spectrum of Risk: From Cloning to Migration
Not every rebuild carries the same legal weight. “Rebuilding from observation” spans an enormous range, and where you sit on that range changes the picture almost completely.
The riskiest version is full platform cloning — observe a commercial platform’s screens, replicate the UI pixel-for-pixel, reproduce the workflows identically, ship a competing product on a different backend. This is where everything piles up at once. Trade dress (visual similarity is the test, regardless of how you got there), patents (which protect the idea, not the expression — clean room doesn’t help), TOS, and potentially copyright. It’s not that any one of these is necessarily fatal; it’s that you’re fighting on four fronts simultaneously against a vendor with more legal budget than you and an incentive to make an example.
The Malus model (AI agents rewriting GPL packages under a permissive license) sits in genuinely unsettled territory. The copyright derivative work question is live, the training data contamination weakens the clean room defense, and the output may not even be copyrightable under current guidance. The legal risk here is moderate-to-high, and the “high” is doing real work in that phrase.
Competitive reimplementation — studying a competitor’s public-facing product and building something that does the same job with different architecture and UI — is how most software competition has always worked. Main risks are patents and whatever the TOS says about competitive analysis. Low-moderate, manageable with reasonable diligence.
And then there’s platform migration: you document your own business processes running on a platform you license, and rebuild them on a new stack, with a different UI. This is what companies have done through every major platform transition over the last thirty years. The AI makes the documentation step faster. The legal picture hasn’t changed much.
The Platform Migration Model: Building from Observed Functionality
Of all the scenarios on that spectrum, the one with the best risk profile — and the most practical value for most engineering organizations — is what I’m calling the Platform Migration Model. This is the case where you capture the functionality of an application you already operate and have customized, then rebuild it on a different technology stack.
This isn’t software cloning. It’s fundamentally different, for reasons that matter in court:
What You’re Actually Capturing
The distinction that matters: Agent A isn’t reading the vendor’s proprietary source code. It’s looking at your screens — the forms, workflows, business rules, and configurations that you built on their platform. The “spec” it produces is really just a set of your business requirements, not a reverse-engineered description of how the platform works under the hood.
This is exactly what a business analyst does when you’re migrating between platforms. Companies do this all the time: moving from ServiceNow to Jira Service Management, from Salesforce to HubSpot, from SAP to Oracle ERP. The AI just makes the documentation step faster.
What You’re Building
Agent B gets business requirements: “When an incident comes in, auto-categorize it, route to the right team based on these criteria, escalate if nobody acknowledges within 4 hours.” Then it builds that on a completely different stack. Different backend. Different database. Different UI framework. Different look and feel entirely.
The result does the same thing as your current platform configuration, but it shares essentially zero copyrightable expression with the vendor’s product. Functional equivalence isn’t infringement. It’s a competition.
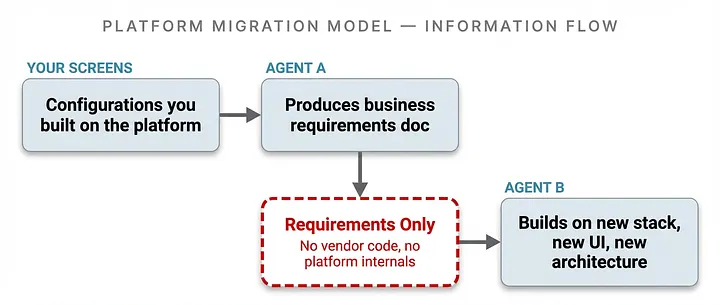
Figure 2: Platform Migration Model – Information Flow
IP Layer Analysis for Platform Migration
The same IP framework, narrowed to the platform migration scenario. The risk profile is much more favourable across every layer:
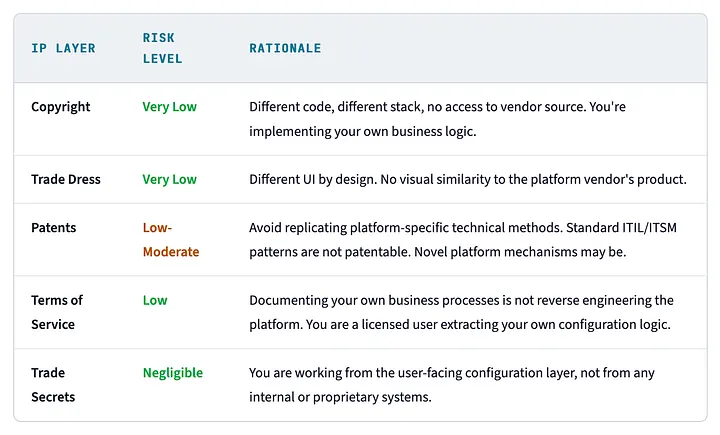
Table 2: IP Layer Analysis for Platform Migration
Practical Framework: Doing This Safely
If you’re going to do this, here’s how to keep it clean. These aren’t just good practices. They’re the difference between “we migrated our business processes” and “we cloned their platform,” and that distinction matters more than you’d think if someone sends a letter.
The framing matters — and it’s not wordplay. You’re moving your business processes off a vendor’s platform, not reverse engineering their internals. Call it migration in every document, charter, and architecture decision from day one. What Agent A produces needs to match: business-level requirements, not a technical description of how the vendor built something. “When an incident is P1 severity, notify the on-call team via the configured channel within 5 minutes” is business logic. “ServiceNow uses GlideRecord queries against the sys_user_group table with an encoded query matching assignment_group” is platform internals. A lawyer will see the difference even if an engineer doesn’t think about it.
Agent B stays in its lane
The implementing agent works from the business requirements document and nothing else. No access to the original platform, no vendor documentation, no API references. It picks its own architecture, libraries, and patterns. The wall between observation and implementation needs to be real, not cosmetic.
Make your own unique UI
Don’t replicate or try to clone the vendor’s visual design. This eliminates trade dress risk entirely. It’s also just a better outcome. You get a UX optimized for your workflows instead of one that was designed to work for everyone and therefore fully satisfies no one.
Keep a paper trail
Save the requirements Agent A produced. Save the prompts you gave Agent B. If anyone asks questions later, you want contemporaneous documentation that shows a migration process, not a cloning operation.
Know the patent landscape
Before you rebuild any workflows, spend an afternoon looking at the vendor’s patent portfolio. If they’ve patented specific technical mechanisms (not just business processes), make sure your implementation takes a different technical route. Standard ITIL patterns — incident management, change management, CMDB structures — aren’t patentable. But novel platform-specific algorithms might be.
The Bottom Line
The Platform Migration Model (capturing your own business processes from a platform you operate, then rebuilding on a new stack with a different UI) is the safest application of AI-accelerated clean room engineering. It’s also, when you strip away the controversy, just what enterprises have always done during platform migrations. The AI part makes it faster. The legal part hasn’t changed much.
Implications for the Industry
The ripple effects of all this go well beyond any single migration project. If you’re running an engineering organization, you need to be thinking about this from both sides: as someone who might benefit from rebuilding, and as someone whose platform might get rebuilt by someone else.
If You’re Thinking About Rebuilding
Platform migration just got an order of magnitude cheaper. Work that used to eat months of business analysis and years of reimplementation can now compress into weeks. The build-vs-buy math changes when building gets that much faster. Vendor lock-in loses its leverage when the switching-cost drops from “two-year project” to “two-week sprint.” Even the big, deeply customized platforms start to look escapable.
But cheaper doesn’t mean careless. The legal ground is still shifting, especially around AI-generated code and derivative works. The organizations that move carefully, treating this as migration rather than cloning, keeping documentation clean and getting legal eyes on it, will be in a much better position than those who move fast and hope for the best.
If You’re a Platform Vendor
If your moat is “it’s too expensive to reimplement what customers built on us” — well, look around. That moat is shrinking. The vendors who keep customers will be the ones where the value lives in things AI can’t easily replicate: a thriving integration ecosystem, real community, continuous innovation, operational reliability that’s been proven under fire, compliance frameworks that took years to build, and support teams that actually pick up the phone. Switching costs alone won’t hold.
For years, enterprise SaaS has relied on the assumption that platform-specific configurations are sticky. AI-accelerated migration is testing that assumption in real time.
If You Maintain Open Source
Malus and chardet are early warnings. Copyleft licenses were designed for a world where reimplementation was expensive enough to be a deterrent. When AI collapses that cost to $14 and a package.json, the enforcement mechanism weakens whether courts intervene or not.
The part of Nolan’s blog post I keep thinking about is his concession. He doesn’t argue that stripping copyleft is harmless — he says it will probably damage the commons, and he says it anyway. His actual position is that the combination of AI capability and economic pressure on maintainers was always going to get here, so he’d rather have a business model than pretend otherwise. That’s an uncomfortable argument to dismiss, because it’s not wrong about the direction of travel. It’s just making money from the transition instead of mourning it.
Open source isn’t finished. But if the code itself becomes trivially reproducible, the value proposition has to shift — to community, governance, ongoing maintenance, security response, the things that don’t exist in a package tarball and can’t be cloned in four days with Claude Code.
The Verdict: It Depends — But Not in a Useless Way
AI clean room engineering isn’t uniformly legal or illegal. Where you land depends on what you’re observing, what crosses the wall in the specification, how genuinely isolated the implementing agent is, and what comes out the other side. The spectrum runs from routine platform migration (solid ground, low risk) to deliberate license-stripping of copyleft code (untested, ethically messy, legally risky).
The practical takeaway for engineering leaders: if you’re migrating your own business processes to a new stack with a different UI, you’re fine. If you’re trying to clone a commercial platform screen-for-screen or launder open-source licenses through AI, you’re in uncharted territory and you should expect to be tested.
The law will catch up. It always does. The people who’ll come out best are the ones who documented their intent honestly, kept clean boundaries between observation and implementation, and built something genuinely their own from migrated requirements — rather than something that’s technically someone else’s with the serial numbers filed off.
One angle I didn’t go into here: the moral rights question under EU law, which sits entirely outside the copyright framework I’ve been working from. In several EU jurisdictions, moral rights can’t be waived — and they may complicate the AI clean room picture in ways that U.S. analysis doesn’t cover. It’s worth its own piece.
Sources & Case References
All legal cases, regulatory publications, and primary sources cited in this article are linked below for independent verification.
Legal Precedents
- Baker v. Selden, 101 U.S. 99 (1879)— Established the idea-expression dichotomy in U.S. copyright law.
justia.com/cases/federal/us/101/99/ - Phoenix Technologies — Clean Room IBM BIOS (1984)— First major commercial clean room reverse engineering of software.
wikipedia.org/wiki/Phoenix_Technologies
en.wikipedia.org/wiki/Clean-room_design - Google LLC v. Oracle America, Inc., 593 U.S. 1 (2021)— Supreme Court ruled Google’s reimplementation of Java APIs was fair use.
gov — Official Opinion (PDF)
oyez.org/cases/2020/18–956
Harvard Law Review Analysis - Thaler v. Perlmutter — Supreme Court Denies Certiorari (March 2, 2026)— AI cannot be listed as sole author under the Copyright Act.
Baker Donelson — Analysis
Mayer Brown — Analysis
Holland & Knight — Analysis - GEMA v. OpenAI — Munich Regional Court (November 2025)— Ruled that LLM reproduction of copyrighted content in outputs constitutes infringement even if training data was lawfully obtained.
CMS Law — Analysis
Bird & Bird — Analysis
Regulatory & Government Publications
- S. Copyright Office — Copyright and Artificial Intelligence, Part 2: Copyrightability (January 2025)
copyright.gov — Full Report (PDF)
copyright.gov/ai/ — AI Reports Hub - S. Copyright Office — Part 3: Generative AI Training (May 2025)
copyright.gov — Full Report (PDF)
The Malus Provocation
- Malus — Clean Room as a Service— The service and its claims. Malus.sh
- “Thank You for Your Service” — CEO Blog Post by Mike Nolan— The full economic and legal argument for AI clean room engineering.
Malus.sh/blog.html - “The Death of Open Source” — Dylan Ayrey & Mike Nolan— The original presentation.
YouTube — The Death of Open Source
The chardet Controversy
- “No right to relicense this project” — GitHub Issue #327— Mark Pilgrim’s challenge to the chardet 7.0 relicensing. github.com/chardet/chardet/issues/327
- Simon Willison — “Can coding agents relicense open source through a ‘clean room’ implementation?”— Comprehensive technical analysis. simonwillison.net/2026/Mar/5/chardet/
- Hacker News Discussion — “No right to relicense this project”— 373+ comments from the developer and legal community. ycombinator.com/item?id=47259177
Supply Chain Incidents Cited
- Shai-Hulud / Shai-Hulud 2.0 npm Supply Chain Worm (September–December 2025)
CISA Alert — Widespread Supply Chain Compromise Impacting npm Ecosystem
Palo Alto Unit42 — “Shai-Hulud” Worm Compromises npm Ecosystem
Intel471 — Emerging Threat: Shai-Hulud Worm 2.0 (PDF)
Analysis & Commentary
- Jonathan Bailey, Plagiarism Today— “Cleanroom as a Service: AI-Washing Copyright” — Copyright analyst’s detailed review of Malus’s claims and their legal validity. plagiarismtoday.com — Full Article
- net Discussion — “Vibe-coded ext4 for OpenBSD”— Linux kernel community perspective on AI-generated code and copyright.
lwn.net/Articles/1064826/ - Trade Dress Protection for Software GUIs— Cornell Law Review analysis of trade dress as a mechanism for UI protection.
Cornell Law — Full Paper (PDF)
A Note on Scope
I’m a tech guy, not a lawyer. This article pulls together legal precedents, regulatory positions, and expert commentary to give engineering leaders a working understanding of the landscape — but it’s not legal advice. The law around AI-generated code and derivative works is moving fast and hasn’t settled. If you’re planning a significant migration or rebuild project, get IP counsel involved who knows the current case law and your specific jurisdictions.


















