Our guide is designed for business leaders, data owners, compliance teams, and technology stakeholders responsible for managing data risk, storage cost, and regulatory exposure. From the viewpoint of Amazon Web Services (AWS), ILM is implemented through policy-driven automation, where data is continuously managed based on access patterns, business value, and retention requirements—using lifecycle rules, storage tiering, and automated archival or deletion.
With our guide you build a perspective that aligns information lifecycle management with business outcomes across your functions, domains, and units, showing how enterprises can reduce compliance risk, control data growth, and enforce consistent retention and disposal policies while maintaining operational efficiency at enterprise scale.
Key Takeaways
- ILM on AWS uses policy-driven automation (lifecycle rules, storage tiering, archival/deletion) to manage data based on access, business value, and retention requirements.
- A well-designed ILM framework reduces compliance risk, controls storage growth, and enables defensible disposal while preserving operational efficiency at enterprise scale.
- Implementing ILM requires cross-functional collaboration, metadata-driven controls, and automated audit trails to achieve enterprise-grade compliance and cost savings.
- Example outcomes from cloud-native ILM deployment include up to 80% improvement in purge sequencing accuracy, up to 90% reduction in manual retention effort, 40% lower storage/backup costs, and 100% policy-driven compliance enforcement.
Most ILM frameworks talk about individual tools in isolation. What enterprises need is a connected lifecycle system—create → store → use → archive → delete—implemented consistently across applications, teams, and AWS environments, with audit evidence built in.
Business Value: Bringing Clarity to What to Keep, Protect, and Delete
In today’s digital enterprise, data is more than an operational byproduct—it is a strategic asset. But as enterprises generate and store growing volumes of information across applications, cloud platforms, and business functions, managing that data responsibly becomes increasingly complex.
The challenge is no longer just storing information. It is knowing what to retain, what to archive, what to protect, and what to defensibly dispose of. That is where Information Lifecycle Management (ILM) becomes essential.
ILM provides a structured, policy-driven approach to managing data from creation through secure disposal. By applying archival and retention policies intelligently, organizations can reduce storage costs, improve data usability, mitigate risk, and strengthen compliance.
For industries such as financial services, healthcare, and insurance, ILM is no longer just a technology initiative. It is a business imperative.
Why Is Information Lifecycle Management Important?
A strong ILM strategy helps organizations turn data management into a business advantage. From a business standpoint, ILM relies on clear classification of data such as customer data, financial records, operational data, regulated data, and archived historical information, ensuring that each category is handled according to its business value and risk profile.
- Make Data More Useful: ILM keeps information accessible, trustworthy, and well-governed so it can support operations, analytics, and informed decision-making.
- Reduce Storage Costs: Not all data needs to remain on high-cost production storage. ILM enables organizations to move inactive or low-value data to lower-cost archival tiers and safely delete data that has outlived its retention period.
- Mitigate Risk: By identifying and controlling sensitive data, ILM helps reduce the risk of unauthorized access, over-retention, data breaches, and non-compliant deletion.
- Ensure Compliance: ILM supports alignment with legal, regulatory, and internal policy requirements by ensuring that data is retained for the required duration and deleted defensibly when no longer needed.
Ultimately, ILM translates data strategy into execution—using automation and policy controls to manage growth, enforce compliance, and continuously optimize cost across the data lifecycle.
What Is an Information Lifecycle Management (ILM) Framework?
Information Lifecycle Management (ILM) framework for managing data throughout its entire lifecycle—from creation to secure disposal. It ensures that data is properly classified, stored, accessed, retained, archived, and deleted according to its business value, sensitivity, and compliance requirements.
In practice, ILM delivers measurable value by enforcing policy-driven data handling at scale—automating retention and deletion, reducing audit effort, preventing over-retention, controlling storage costs, and maintaining timely access to accurate data.
Rather than treating all data the same, an ILM framework helps enterprises apply the right controls at the right time, based on how that information is used and what obligations are attached to it.
Operationalizing ILM at Scale on AWS
AWS makes ILM operational at enterprise scale by integrating storage lifecycle policies, encryption, access controls, and audit logging into a unified governance model. Services such as Amazon S3 lifecycle policies, archival tiers, immutable storage controls, and centralized logging allow organizations to reduce audit effort, prevent over‑retention, enforce legal holds, and lower storage costs—while maintaining continuous access to the right data at the right time.
What Are the Stages of ILM Framework?
AWS natively supports every stage of the ILM lifecycle—from data ingestion to secure deletion—through tightly integrated cloud services that combine automation, security, and governance. This allows you to implement ILM as an always‑on operational capability rather than a periodic compliance exercise.
An effective ILM framework typically includes five key stages:
- Data Creation and Capture
Data is generated, collected, or ingested from business processes, applications, users, and external sources. - Data Storage and Access
Data is stored in appropriate platforms with the required levels of availability, security, and performance. - Data Usage and Analytics
Information is used for operations, reporting, customer interactions, and business insights. - Data Archiving and Retention
Inactive or infrequently accessed data is archived according to business and regulatory retention requirements. - Data Disposal and Deletion
Once data has met its retention requirement and is no longer needed, it is securely and permanently deleted.
While an ILM framework defines how data should be governed across its entire lifecycle, its credibility is ultimately tested at the point of retention and deletion. These stages determine whether data is held for the right duration, protected under legal and regulatory mandates, and defensibly removed when obligations end. As a result, retention and purging represent the most compliance‑critical execution layer of ILM.
Understanding ILM Framework for Business Regulatory Compliance
By establishing clear and enforceable policies across every phase of the data lifecycle, ILM frameworks help consistently to meet legal, regulatory, and industry-specific requirements. Strong ILM practices support compliance with major regulations and standards such as:
- GDPR: General Data Protection Regulation
- HIPAA: Health Insurance Portability and Accountability Act
- SOX: Sarbanes-Oxley Act
- Industry-specific financial services regulations: Regulations governing financial institutions (e.g., banking, insurance, capital markets) that define requirements for data retention, reporting, and auditability
- Internal governance and risk mandates: Organization-defined policies and controls for managing data, risk, compliance, and operational accountability across the enterprise.
Effective data governance extends beyond classification and retention. It also requires continuous monitoring to ensure that data remains:
- Accurate
- Secure
- Accessible to authorized users
- Used only for approved and appropriate business purposes
For regulated enterprises, this level of control is critical. Both over-retention and premature deletion can create serious compliance and operational risk.
Rightsized Storage and Compliance‑Aware Control with AWS
With AWS, ILM frameworks dynamically align data value with storage cost and risk. Frequently accessed data can remain on high‑performance storage, while inactive or compliance‑bound records are automatically moved to lower‑cost archival tiers with retention locks and deletion controls.
While an ILM framework defines how data should be governed across its entire lifecycle, its credibility is ultimately tested at the point of retention and deletion. These stages determine whether data is held for the right duration, protected under legal and regulatory mandates, and defensibly removed when obligations end. As a result, retention and purging represent the most compliance‑critical execution layer of ILM.
How to Build a Data Retention and Purging Framework
Building a data retention and purging framework is a pivotal part of ILM—it is the mechanism through which ILM policies are enforced in practice. This is where lifecycle governance moves from definition to execution, translating regulatory requirements, internal policies, and business rules into defensible, repeatable actions that can withstand audits, legal scrutiny, and operational scale.
Because retention and deletion decisions carry direct regulatory, legal, and business impact, they cannot be treated as a purely technical responsibility. How long data is retained, when it is placed under legal hold, and when it is permanently deleted affects compliance posture, legal defensibility, cost control, and customer trust. For this reason, an effective retention and purging framework must be governed as a shared enterprise responsibility, not an IT task.
Key stakeholders typically include:
- Business teams
- Data governance teams
- Privacy and legal teams
- IT and data engineering teams
- Information security teams
A structured, cross‑functional operating model ensures that retention and purge policies are accurate, enforceable, and aligned with real‑world usage. Each stakeholder group contributes essential context—business value, regulatory interpretation, technical feasibility, and security enforcement—so that lifecycle decisions remain consistent across systems, geographies, and regulatory regimes.
Driving the Initial Assessment
Before implementing a data retention and purging framework, enterprises should assess:
- The definition and scope of retention and purging requirements
- The business domains and datasets in scope
- Current retention and purging policies
- The existing technology environment and technical stack
- Structured and unstructured data targeted for archiving or purging
- Retention periods and purge actions by data type
- Key design considerations, guardrails, and operational risks
This assessment creates the foundation for a scalable, policy-driven ILM model.
Building the ILM Framework for Structured Data
For structured data, the recommended approach is a flexible, metadata-driven framework that supports secure and policy-based deletion while accounting for dependencies, sensitive data classification, and operational performance.
Structured Data ILM Framework Process Flow on AWS
On AWS, these steps are implemented using policy‑driven lifecycle rules, metadata and dependency tracking, automated compliance checks, and workflow‑based approvals integrated with logging and audit services. This enables scheduled enforcement, stakeholder notifications, controlled deletions, and immutable audit records—all without manual intervention.
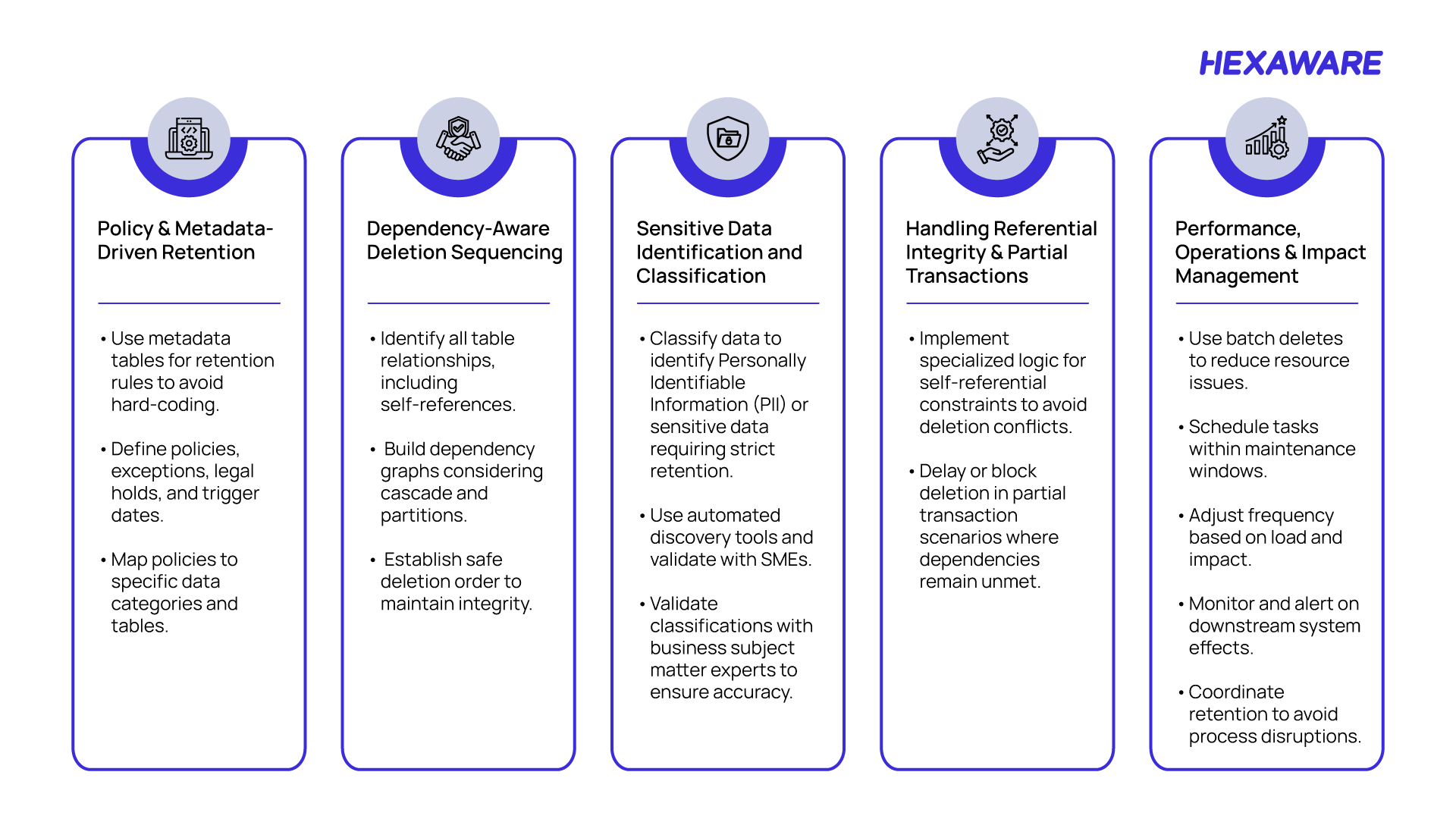
Metadata‑driven framework for secure, policy‑based structured data management
How to do it: Once governance ownership is established, data retention and purging must be operationalized through a clear, repeatable execution model.
An effective framework defines how retention rules are created, how exceptions and dependencies are managed, how eligibility for deletion is assessed, and how actions are approved and audited.
Our framework approach ensures that data is retained only as long as required, purged defensibly, and fully traceable for regulatory and compliance purposes. This approach makes structured data purging more controlled, transparent, and auditable.
Building the ILM Framework for Unstructured Data
For unstructured data—such as documents, images, emails, PDFs, and archived files—enterprises need an approach that combines retention rules, metadata tagging, storage tiering, access controls, and automated lifecycle actions.
Unstructured Data ILM Framework Process Flow on AWS
On AWS, unstructured data governance is enabled through standardized storage layouts, object metadata and tagging, lifecycle policies, and role‑based access controls applied natively across services such as Amazon S3. This allows retention rules and access policies to be enforced uniformly, even as unstructured data volumes grow and usage patterns change.
To apply ILM principles effectively to unstructured environments, environments must first establish order, classification, and access discipline. This high‑level process flow defines how unstructured data is organized, tagged, secured, and placed under lifecycle control so that retention, access, and deletion policies can be enforced consistently across the environment.
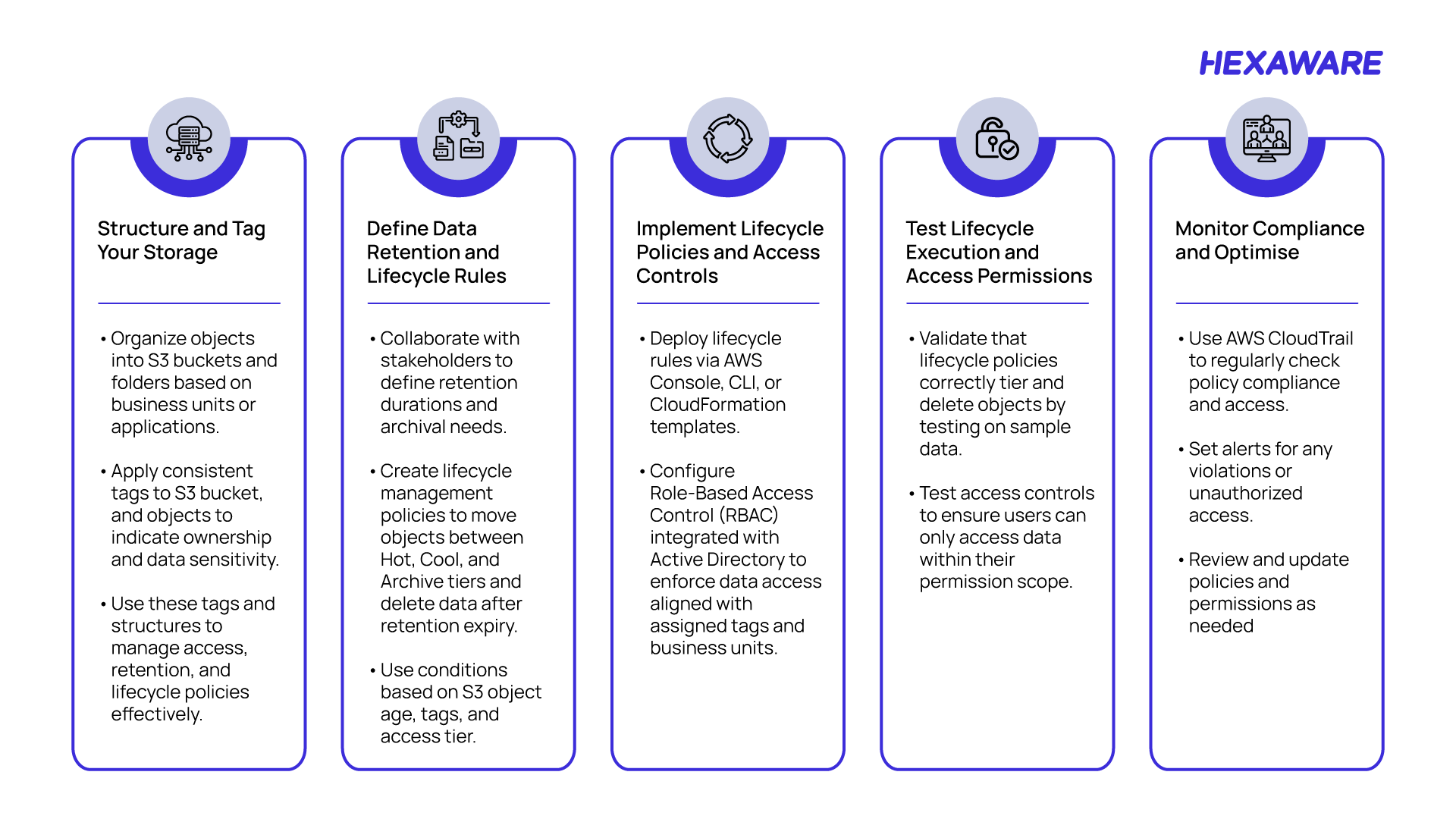
Metadata‑driven framework for secure, policy‑based unstructured data management
How We Built an ILM Framework for Financial Services
In financial services, information lifecycle management (ILM) is a regulatory and business imperative.
Banks, insurers, and capital market firms must manage massive volumes of data while meeting strict retention, privacy, audit, and risk requirements that continue to evolve across jurisdictions. At the same time, they must ensure data remains accessible, secure, and cost‑efficient throughout their lifecycle.
Our approach to building an ILM framework for financial services was grounded in policy‑driven governance, regulatory alignment, and automation—enabling retention of the right data for the right duration, defensibly purge data when it is no longer required, and reduce compliance risk while improving operational efficiency.
About Our Client
A leading American financial services company sought to modernize and unify data archival and retention across multiple banking and financial applications through a cloud-native ILM solution. Operating at enterprise scale, they faced complex regulatory requirements around data retention, purging, auditability, and legal hold management.
Key Challenges
Complex purge dependencies: Intricate parent-child data relationships meant records could not be deleted out of sequence without affecting downstream data integrity and reporting.
Application-specific retention codes: Different banking products followed distinct policy codes, such as BNK110 and ACC340, requiring accurate and regulation-aligned policy enforcement.
Legal hold exceptions: Standard purge logic had to pause immediately when legal holds were triggered, increasing both operational complexity and compliance risk.
Our Solution
We designed and deployed a cloud-native ILM framework aligned with the institution’s regulatory and operational landscape.
The solution unified:
- Archival management
- Retention enforcement
- Legal hold management
- Purge sequencing
- Stakeholder notifications
- Auditable lifecycle controls
This secure and automated data lifecycle management architecture was designed on AWS to address the stringent regulatory, governance, and compliance requirements of the financial services sector.
Built on AWS
Built on AWS with Amazon Simple Storage Service (Amazon S3), the framework drove scalable and policy-driven lifecycle management across enterprise data environments, supporting archival, retention, purging, auditability, and legal hold management.
Key technologies and services leveraged within the solution include Amazon Simple Storage Service (Amazon S3), Informatica Data Management Cloud (IDMC) on AWS, the Snowflake Data Platform on AWS, and reporting and visualization tools such as Microsoft Power BI and Tableau.
Benefits for the Client
Our ILM framework gives end-to-end control—from creation to disposal—putting the right data in the right hands exactly when it was needed.
- Enterprise-grade compliance with leaner operations: Automated, policy-driven lifecycle controls strengthened compliance while reducing manual effort, operational risk, and audit overhead. Coordinated archival and purge processes lowered storage costs without compromising data integrity.
- Up to 80% improvement in purge sequencing accuracy: AI-driven parent-child dependency detection significantly improved purge precision, reducing the risk of data corruption and compliance breaches.
- Up to 90% reduction in manual retention effort: Automated workflows replaced manual lifecycle orchestration, enabling teams to focus more on governance and analytics rather than operational clean-up.
- 40% reduction in storage and backup costs: Timely purging of inactive and closed customer data reduced Snowflake storage and archival costs.
- 100% policy-driven compliance enforcement: Metadata tagging, audit trails, and automated exception handling improved regulatory posture and strengthened audit readiness.
The Role of Information Lifecycle Management in Core Industries
Beyond banking, the ILM framework adapts seamlessly to the needs of other industries. In healthcare, it safeguards patient records while ensuring strict regulatory compliance and timely data access. In retail and e-commerce, it helps manage high-volume customer and transaction data, optimizing storage while enabling sharper personalization and insights.
Manufacturing organizations benefit from structured management of operational and IoT data, improving traceability and efficiency. In telecom and media, it handles massive data flows with precision, ensuring retention policies are met without inflating costs. Across industries, it brings the same core advantage—controlled, compliant, and cost-efficient data management that scales with business growth.
Begin Information Lifecycle Management with Hexaware
As data volumes continue to grow and regulatory scrutiny intensifies, Information Lifecycle Management has become a strategic necessity. A well-designed ILM framework helps enterprises archive intelligently, retain with purpose, and delete defensibly. It strengthens governance, improves compliance, lowers costs, and reduces operational risk.
For enterprises looking to modernize their data landscape, ILM is more than a framework—it is the foundation for responsible, scalable, and future-ready data management. Learn more about our AWS partnership and explore Hexaware’s strategic data and analytics services.


















