Ever lost track of the “final” version of a document—only to find half a dozen copies named Report_v3_FINAL(2).xlsx? For most of us, that’s an occasional frustration.
But at enterprise scale, this chaos is amplified a thousand times inside data warehouses. Multiple systems feed in data, business rules keep changing, and without the right structure, teams end up with silos, duplication, and uncertainty about the “truth”.
A recent survey by IDC found that over 80% of enterprise data is never analyzed effectively, largely due to fragmentation and lack of trust in its quality. That’s the problem modern enterprises are racing to solve—and why the Data Vault 2.0 methodology, when combined with dbt data modeling on platforms like Snowflake, is gaining so much traction.
Together, these offer a pathway to scalable data warehousing that is both flexible and audit-ready.
Understanding Snowflake Data Vault 2.0
To understand why Data Vault is such a departure from older approaches, it helps to break down its building blocks. Instead of lumping everything into rigid fact and dimension tables, the Data Vault 2.0 methodology separates responsibilities, so the model is stable at the core but flexible at the edges.
Here’s how the pieces come together:
- Hubs act as central signposts. They represent unique business entities like Customer ID or Product Code, ensuring there’s always a clear anchor point.
- Links are the connectors. They describe the relationships between hubs, such as ‘Customer places Order’, and make it easy to navigate complex networks of data.
- Satellites capture the story over time. They store descriptive attributes—like customer names, emails, or addresses—and track how they evolve historically.
This modularity allows enterprises to expand or adjust their warehouse without reengineering everything—a level of data model agility that traditional schemas simply don’t provide.
Why This Matters for Enterprises Today
Enterprises are not just dealing with more data—they’re dealing with more complexity. Customer journeys now span dozens of touchpoints, supply chains stretch across continents, and regulations require meticulous record-keeping.
According to IDC, global spending on digital transformation is projected to reach $4 trillion by 2027, growing at a 16.2% CAGR, as organizations recognize that managing complexity is no longer optional—it’s mission-critical.
How Data Vault Compares to Traditional Data Models
Not all data models are built to handle the scale and complexity of today’s enterprises. Traditional approaches like the Star Schema were designed for reporting speed but often fall short when flexibility and historical accuracy are required. Data Vault 2.0, on the other hand, is built with change in mind—making it more resilient, auditable, and scalable.
|
Feature |
Data Vault |
Traditional Data Models |
|
Purpose |
Data integration, historical accuracy |
Efficient data retrieval, reporting, and analysis |
|
Structure |
Hubs, Links, Satellites |
Fact table, dimension tables |
|
Flexibility |
High |
Low |
|
Scalability |
High |
Moderate |
|
Data Integrity |
Strong, ensures a single source of truth |
Relies on denormalization, potentially less strong |
|
Complexity |
Higher, especially during initial setup |
Lower |
|
Position |
Staging layer, between source and presentation |
Presentation layer, ready for consumption |
|
Maintainability |
Robust, adapts well to changes |
May require more rework with evolving requirements |
|
Use Cases |
Large-scale data integration, evolving needs |
Reporting, business intelligence, data exploration |
How dbt Brings Snowflake Data Vault to Life
Of course, a methodology is only as good as its implementation. While Data Vault provides the framework, many teams hesitate because manual builds can feel overwhelming. This is where dbt data modeling steps in to bridge the gap.
dbt simplifies Data Vault by automating repetitive tasks and layering best practices on top of SQL transformations. Its value shows up in several key ways:
Key benefits of using dbt with Data Vault:
- Modularity: dbt’s model-based approach aligns well with Data Vault’s structured methodology.
- Version Control: dbt integrates seamlessly with Git, facilitating collaborative development and change tracking.
- Automation: dbt’s use of Jinja templates and macros allows for automated generation of repetitive code patterns.
- Documentation: dbt auto-generates documentation, providing clear insights into data lineage and transformations.
The result is that Data Vault becomes practical—not just theoretical—for modern enterprises.
Moving from Features to Everyday Impact
The real test of any approach isn’t just what it promises but also how it changes day-to-day work. When Data Vault 2.0 with dbt is implemented, its benefits are felt across multiple roles in the enterprise.
For example:
- Developers work faster and more confidently. They reuse patterns, reduce errors, and accelerate delivery cycles.
- Data Stewards gain visibility into transformations and lineage, strengthening enterprise data governance and audit readiness.
- Business Teams finally trust the insights they receive, knowing they’re based on a reliable history, not snapshots riddled with blind spots.
This shift takes organizations beyond ‘better data models’ and into a culture where data is trusted, scalable, and actionable.
Implementation Steps for Data Vault 2.0 With dbt
The architecture behind Data Vault 2.0 with dbt goes beyond theory—it shows how every part connects. A clear visual of the process makes it easier to understand and helps teams align on a common approach. The framework below captures the flow from raw data to trusted, auditable insights.
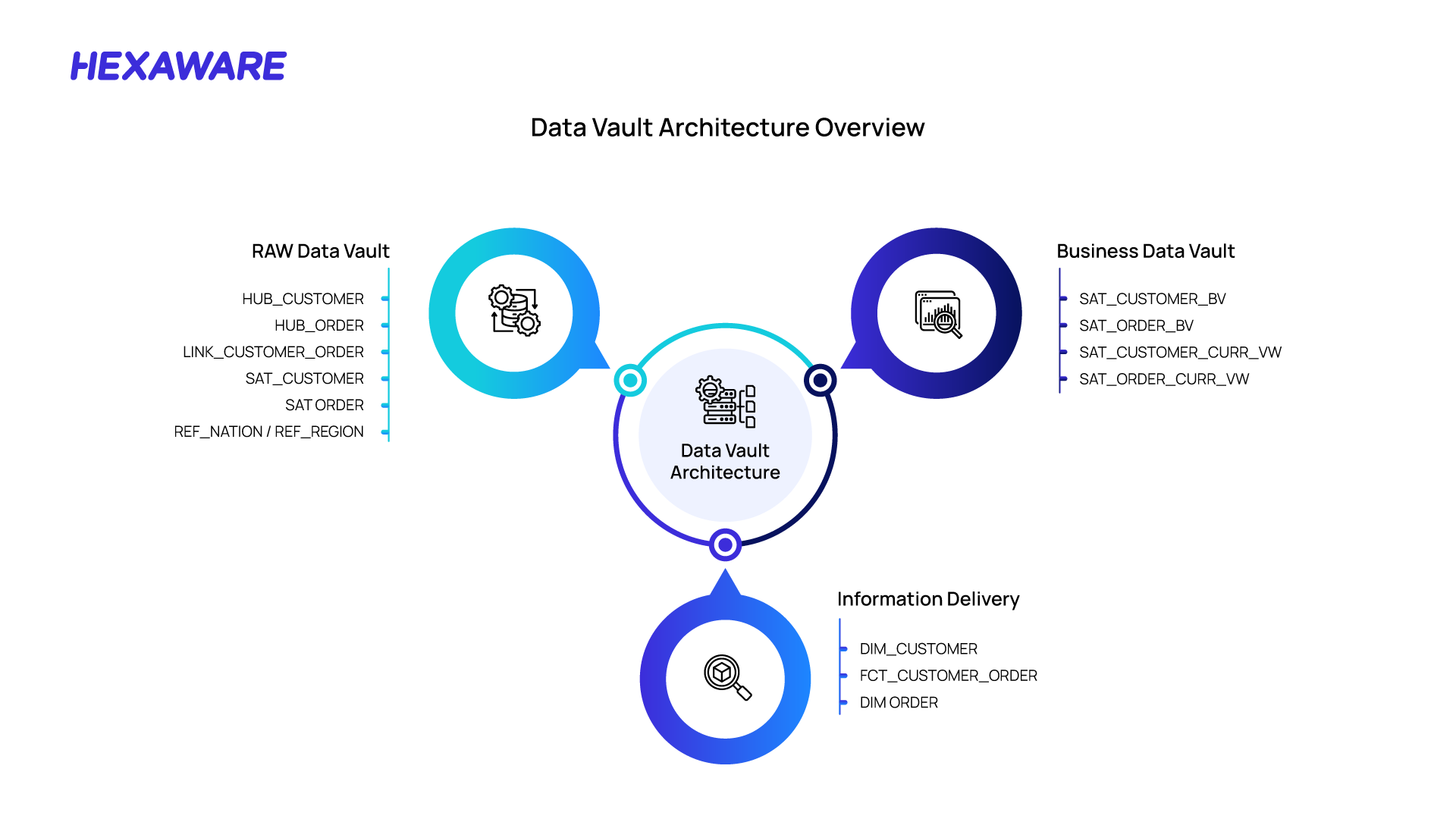
Knowing the benefits is one thing, but seeing how it comes together in practice is where the magic happens. Implementing Data Vault 2.0 with dbt follows a clear sequence that balances planning, automation, and validation. Here’s a simple roadmap you can follow:
Step 1: Setting Up the Environment
The journey begins with configuring a dbt project connected to your chosen data warehouse (e.g., Snowflake or BigQuery). At this stage, ensure that raw data sources are available and that the right permissions exist to create schemas and tables.
Step 2: Designing the Data Vault Model
Next, define the structure of your model by identifying the core hubs, links, and satellites. This design step ties directly to business entities and their relationships, laying the foundation for scalability and traceability.
Step 3: Utilizing dbt Packages for Data Vault
To accelerate adoption, leverage purpose-built dbt packages:
- AutomateDV: An open-source package that provides macros to automate the creation of hubs, links, and satellites. It simplifies implementation and ensures adherence to Data Vault best practices.
- dbt-constraints: A package that automatically applies constraints such as primary keys, unique keys, and foreign keys, based on tests you define within your dbt models.
Step 4: Building the Models
With design and automation in place, the next step is constructing your models:
- Hubs: Extract unique business keys and load them into hub tables.
- Links: Capture relationships between hubs to ensure referential integrity.
- Satellites: Track historical changes and descriptive attributes, incorporating effective dating and change detection mechanisms.
Step 5: Testing and Documentation
Finally, validate and document the work. Use dbt’s built-in tests to guarantee data integrity and consistency. Generate documentation using dbt docs generate and visualize end-to-end data lineage with dbt docs serve, giving stakeholders both confidence and clarity.
Zooming Out: Trust in Data is the Ultimate Outcome
When you step back, the conversation isn’t just about models or automation—it’s about trust.
- Trust that the modern data warehouse can scale without breaking under pressure.
- Trust that governance and compliance are built into the process, not added as an afterthought.
- Trust that every team, across every region, is working from the same reliable source of truth.
That trust is what turns data from a liability into a competitive advantage.
Partner with Hexaware for Snowflake
At Hexaware, we work closely with Snowflake to help enterprises modernize their data ecosystems with strategies that balance scalability, governance, and agility.
Whether you are looking to implement Data Vault 2.0 with dbt, accelerate data warehouse automation, or strengthen enterprise data governance, our joint expertise ensures you get a future-ready architecture that adapts to your business needs.
Explore how our Hexaware + Snowflake partnership can help you transform your data landscape.


















