Our client asked us to update their data lake using Apache Iceberg for an open data lake for its analytic datasets using the Snowflake platform for its enterprise analytics. They wanted a solution that would let them run fast, cost-effective analytics directly on Amazon S3, integrated with the Snowflake platform.
To make this work, they wanted to explore Apache Iceberg with both most compatible data catalogs: Snowflake Horizon Catalog and AWS Glue Catalog.
But how do you make the choice? Our guide distills our hands-on experience, helping you navigate choices for data catalogs and build a data lake that’s both open and optimized.
But First, Why Apache Iceberg for an Open Data Lake?
Apache Iceberg is an open table format purpose-built for large analytical datasets. It delivers ACID transactions, schema evolution, and time travel—features that make it ideal for high-scale analytics and AI workloads in cloud data warehouse environments.
Paired with the Snowflake platform, Iceberg lets you:
- Store data in Amazon S3 while managing metadata in your chosen catalog.
- Interact with multiple analytics tools and engines.
- Avoid lock-in while retaining enterprise-grade governance.
Our Approach: Matching Catalog Types to Business Needs
In our experience, both Snowflake Horizon Catalog and AWS Glue Catalog work well with Apache Iceberg tables, but they fit different needs.
Choosing Different Data Catalogs for Different Teams
As our client’s teams were all using the Snowflake platform, we set it up, so each team could use a data catalog that suited their working style and requirements.
Here are our practical tips to help data teams choose the right catalog for their needs.
You can evaluate on three criteria:
- Performance: How fast can analytics work with the Snowflake platform.
- Ecosystem Support: How well each works with Apache and Amazon s3.
- Catalog Cost: How much each catalog option costs for setup and usage.
When Do You Choose Snowflake Horizon Data Catalog?
The Snowflake Horizon Catalog (inbuilt in the Snowflake platform) is easy to use and manage on the Snowflake platform, making it a great choice for teams needing Snowflake’s in-built analytics features.
It supports real-time analytics, strong metadata management, and simple access control, but it can be more expensive and is less flexible with open-source tools.
Here are some decision points:
- Access to Snowflake analytics: Real-time analytics and simple data access control.
- Considerations: Higher cost, less flexibility with open-source tools.
- Best for: Teams seeking minimal setup and managed services.
When Do You Choose Amazon Glue Data Catalog?
On the other hand, AWS Glue Catalog is more flexible and cost-effective, especially for teams using AWS or multiple platforms. It’s ideal for building open data lakes that work with tools like Athena, EMR, and Redshift.
Here are some decision points:
- Access to AWS tools: Centralized metadata for tools like Athena and Redshift.
- Considerations: More setup for integration, but better open-source compatibility.
- Best for: Teams needing cost-effective, extensible solutions.
While it takes more setup—especially to connect with Snowflake—it gives you more control and can be extended to fit different needs.
Everything to Consider for Data Catalogs with the Snowflake Platform
With the Snowflake platform, both AWS Glue and the Snowflake Horizon catalog can be used for powerfully managing metadata and improving data access.
To truly zero in on a choice for each team, here are the strengths of each catalog and how they work best with the Snowflake platform.
|
How it Works with Snowflake’s Platform? |
Snowflake Horizon Catalog |
AWS Glue Catalog |
|
Platform Integration
|
• Seamless integration with Snowflake’s platform and partner ecosystem • Enables rapid deployment and managed services • Simplifies client onboarding and support |
• Enables partners to offer hybrid and multi-cloud solutions • Supports integration with AWS analytics tools |
|
Advantages |
• Fully integrated with Snowflake’s analytics, security, and governance features • High performance for BI and real-time analytics • Minimal setup and maintenance for clients |
• AWS-native metadata management • Multi-engine compatibility (Athena, EMR, etc.) • Cost-effective for AWS-centric clients • Supports diverse file formats |
|
Disadvantages |
• Higher cost for compute and storage • Less flexibility for clients needing open-source tool integration outside Snowflake |
• Requires manual refresh for metadata • Additional setup for secure Snowflake integration • Potentially more complex support model |
|
Best Fit Use Cases |
• Teams with minimal analytics needs or not using Snowflake • Small-scale data projects where Snowflake’s capabilities are not required |
• Real-time or low-latency analytics needs • Small, simple data environments • Teams not invested in AWS ecosystem |
|
When Not to Use |
• Teams with minimal analytics needs or not using Snowflake • Small-scale data projects where Snowflake’s capabilities are not required |
• Real-time or low-latency analytics needs • Small, simple data environments • Teams not invested in AWS ecosystem |
|
Cost Model |
• Consumption-based pricing: pay only for compute and storage used within Snowflake • Predictable billing for managed services |
• Pay-as-you-go pricing for AWS Glue resources • Potential cost savings for AWS-heavy workloads • Additional costs for cross-platform integration |
Everything to Consider for Data Catalogs with Apache Iceberg
Apache Iceberg is an open table format designed to simplify data processing on large datasets stored in data lakes. It is particularly useful for managing large analytical tables.
Let’s see the benefits of the two catalogs chosen:
Snowflake Horizon Catalog
- Snowflake Horizon lets you manage Iceberg tables that store data in Amazon S3.
- The table information (metadata) is kept inside Snowflake, while the actual data files remain in S3.
- You can easily control access and run queries directly from the Snowflake platform, making management simple and secure.
AWS Glue Catalog
- AWS Glue Catalog is a central service for storing and managing table information, used by tools like Athena and EMR.
- You can manage Apache Iceberg tables using AWS Glue Studio or other AWS tools.
- If you want to use these tables with Snowflake, you need to set up a connection and configure the right permissions using AWS IAM roles.
Everything to Consider for Data Catalogs with Amazon S3
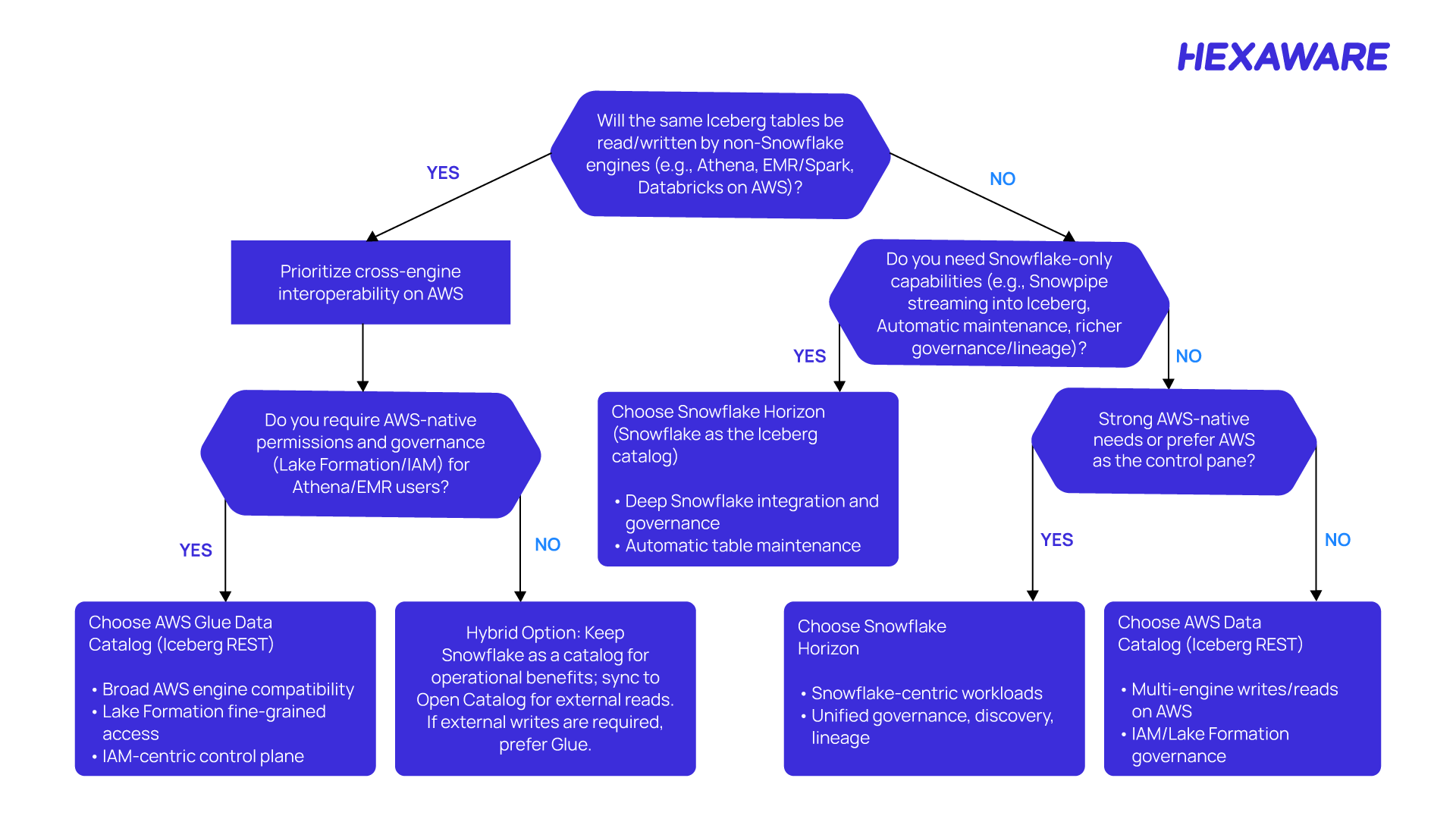
When deciding how to catalog your Apache Iceberg tables on Amazon S3, start by asking: Will engines other than Snowflake (like Athena, EMR, Spark, Databricks, or Redshift) need to read or write these tables?
If the answer is yes, it’s best to use the AWS Glue Data Catalog. This option offers open access and compatibility across multiple analytics platforms, allowing seamless collaboration and flexibility.
If only Snowflake Horizon will access the Iceberg tables, or you want to take full advantage of Snowflake’s advanced governance and security features, choose Snowflake as the catalog. This keeps everything inside the Snowflake ecosystem and lets you leverage powerful platform-native controls.
Further, there is also a hybrid option: If external engines only need to read (not write) the data, you can primarily use Snowflake for cataloging and governance, while still enabling read-only access for other engines through supported integrations.
This balances Snowflake Horizon’s powerful data management with the openness of AWS Glue for analytics and reporting.
Understanding Data Catalog Pricing Factors
When planning your modern data lake architecture, understanding the cost structure of different catalog services is crucial for budgeting and long-term planning.
Both AWS Glue Catalog and Snowflake Horizon Catalog offer powerful ways to manage metadata and connect analytics tools to data stored on Amazon S3, but they have different pricing models and cost drivers.
This section breaks down the key cost components for each service, including charges for data processing, S3 API requests, and data transfers, helping you make an informed choice based on your workload and usage patterns.
Pricing Factors to Consider for Snowflake Horizon Catalog
- Crawler Execution: AWS Glue charges for crawler execution based on the number of Data Processing Units (DPUs) used. The cost is approximately $0.44 per DPU-hour.
- S3 API Requests: Charges for API requests made to the S3 bucket, such as GET, PUT, LIST, and HEAD requests. These costs vary depending on the number and type of requests.
Pricing Factors to Consider for AWS Glue Catalog
- AWS Glue charges for ETL jobs based on the number of Data Processing Units (DPUs) used. The cost is approximately $0.44 per DPU-hour.
For example, if your job uses 6 DPUs and runs for 15 minutes, the cost would be 6 DPUs×0.25 hours×$0.446 DPUs×0.25 hours×$0.44, which equals $0.66. - If data is transferred out of the S3 bucket to another region or the internet, additional data transfer charges apply.
Build Your Open Data Lake to Suite Business Needs
Our solution was built for the best of both worlds: true business intelligence in real-time via Snowflake Horizon accessibility and mainframe-scale scalability and flexibility with AWS, fueling Apache Iceberg and the open data lake it supports.
This guide provides a useful reference when you plan to use Apache Iceberg for enterprise data modernization journeys.
Whether performance, price point, or multi-tool support is your top priority, the right data catalog solutions let you create a modern, open data lake that suites every team’s needs.
Let’s achieve the true potential of your business with our data and analytics strategy and Snowflake partnership benefits.




















