Rising data complexity—driven by advances in AI, increasing regulatory demands, and the shift toward treating data as a product—calls for smarter data cloud architectures and deeper integration across analytics ecosystems.
Highlighting this challenge for high-compliance industries, Gartner’s 2025 predictions report that the rise in GenAI and unstructured data is overwhelming traditional governance models, creating an urgent need for a strategic reset in data and analytics approaches.
A Pivot to Metadata-driven Strategy
Our blog post shares how we used AWS for a global investment firm to build a metadata-driven, serverless data platform. This platform helped them automate data tasks, improve compliance by tracking data clearly, and grow their operations efficiently.
Why Metadata Matters in High-Compliance Areas
Metadata, or “data about data,” helps enterprises manage their information better, especially when rules are strict. It shows where data comes from, how it moves, and how it’s used. This makes it easier to find and trust data, speed up compliance checks, and allow automated reports and analysis.
AWS for Simple, Secure Data Solutions in Industries
In industries where data is complex and strict rules add to the challenges, cloud solutions like AWS are very helpful.
Like for our client, an investment management firm that operates under strict data guardrails while managing vast and diverse datasets, ranging from market information to client transactions.
Here, metadata-driven serverless data processing on AWS helps them win at advanced analytics. Let’s explore how.
The Business Need: A Platform to Manage Data Complexity
The client, a leading global investment firm, needed a robust platform to:
- Centralize data ingestion and transformation workflows
- Support metadata-based data pipeline design for analytics
- Drive team collaboration without infrastructure dependency
- Ensure scalability without compromising on cost or complexity
What We Built: A Serverless Data Platform
The objective was to create a unified, serverless data platform that could support the ingestion, processing, and transformation of data across multiple teams and departments.
We aimed to enable seamless data aggregation and analytics while ensuring scalability and operational simplicity. This approach helped the firm streamline operations, accelerate insights, and minimize manual interventions across departments.
Serverless, Metadata-driven Architecture using AWS
Our solution adopted a phased implementation model. The initial release focused on processing CSV-based file ingestions. Future phases are designed to incorporate APIs, SQL integrations, and event-driven streaming pipelines.
We designed a serverless, metadata-driven architecture using AWS-native components to ensure cost-effectiveness, high availability, and minimal operational overhead. Every new serverless data pipeline was now driven by metadata configurations, enabling flexible modifications without the need to rewrite code.
Step-by-Step Architecture Flow
The following describes the step-by-step data ingestion and processing architecture on AWS, integrating multiple native services for automated, scalable, and flexible data management:
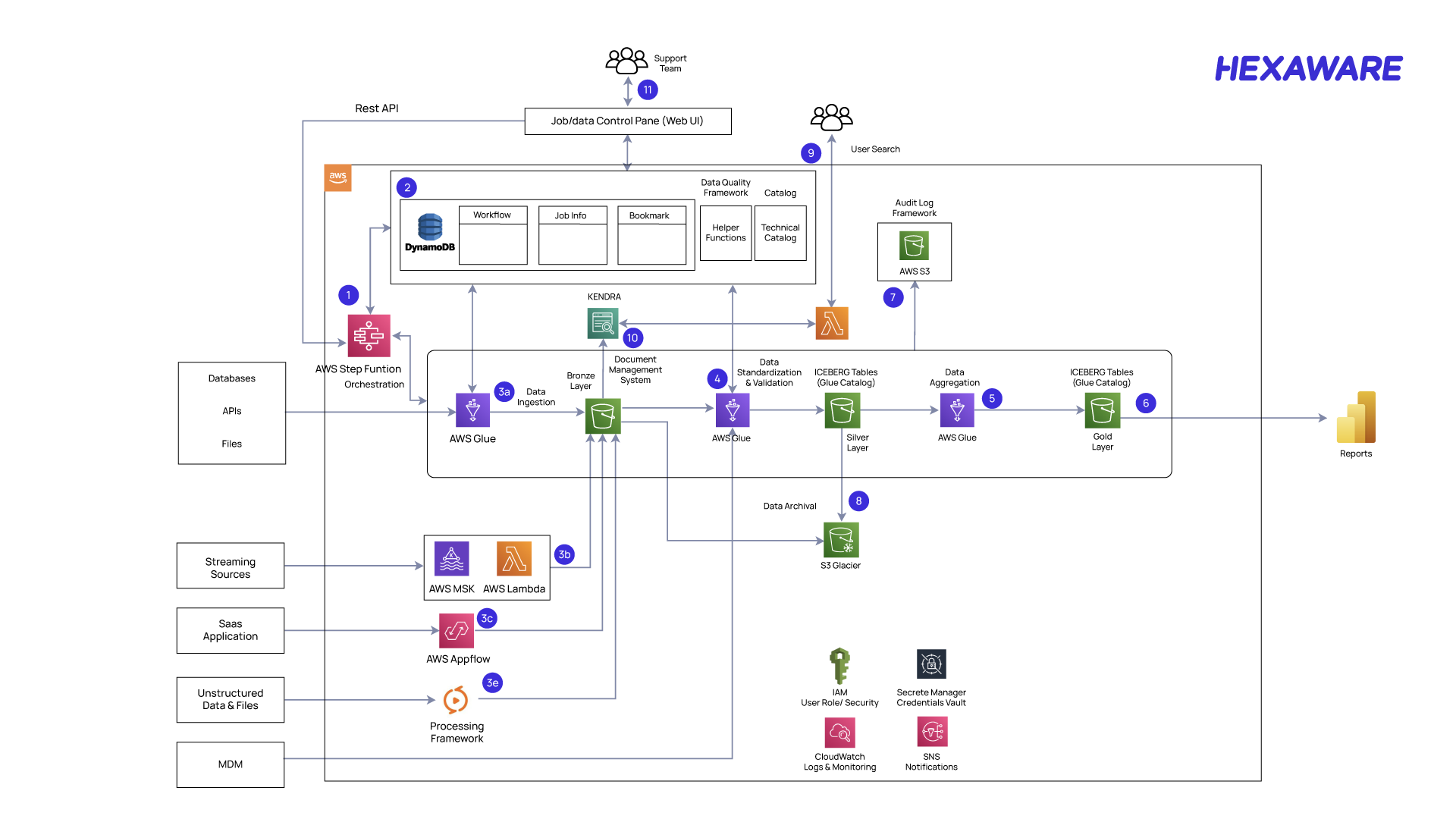
1. Data Source Ingestion
Data is ingested from multiple sources including:
- Structured datasets like files, databases, and APIs
- Streaming platforms via AWS MSK
- SaaS applications, unstructured files, and MDM systems
Each ingestion source is tagged with metadata that defines the expected structure, transformation logic, and destination layer.
2. Ingestion Orchestration
The ingestion process begins with AWS Step Functions, which orchestrate the flow based on the data pipeline configuration:
- For batch workloads, it invokes AWS Glue jobs
- For streaming data, it routes through MSK + AWS Lambda
- For SaaS sources, AWS AppFlow will be used.
- For unstructured inputs, there will be a processing framework to convert data into structured format.
All orchestrations are metadata-driven, pulling job parameters, transformation rules, and destination details from Amazon DynamoDB, which serves as the centralized metadata store.
3. Bronze Layer – Raw Storage and Ingestion
Once data is received:
- It is landed into an S3-based Bronze Layer.
- AWS Glue executes ingestion jobs to clean, format, and log raw data based on metadata configurations.
Glue job execution is dynamic, controlled via workflow entries and job info stored in DynamoDB.
4. Document Management and Enrichment
In parallel, the ingested data is processed by a Document Management System for structural parsing, tagging, or enrichment tasks (e.g., PDF/text parsing). All intermediate files are stored on S3 for auditability.
5. Data Standardization and Silver Layer Transformation
Next, standardized schemas and validations are applied:
- A second set of AWS Glue jobs pulls raw data and applies transformation logic (e.g., field mappings, data type enforcement, lookups).
- Processed data is written into the Silver Layer using Iceberg Tables in Glue Catalog.
6. Data Aggregation and Gold Layer Publishing
After standardization:
- Data undergoes aggregation or business rule calculations using additional Glue jobs.
- Aggregated outputs are published to the Gold Layer, again using Iceberg-backed tables in Glue Catalog.
This Gold Layer is the trusted, analytics-ready dataset layer.
7. Reporting and Analytics
The final output is consumed by business reporting tools:
- Data from the Gold Layer is exposed to Amazon Athena, or integrated into BI dashboards.
- Reports and dashboards are served to users in a self-service or scheduled manner.
8. Metadata Control & Search
- All data pipeline activities—job status, bookmarks, catalog entries—are stored in DynamoDB.
- A Control Panel (Web UI) allows users to configure new data pipelines, monitor executions, and review audit logs.
- Amazon Kendra is used to search across metadata entities for schema properties of the actual dataset.
9. Data Quality & Audit Logging
- Audit tables are implemented using the Apache Iceberg table format
- Data quality checks and helper functions are triggered during data pipeline execution to ensure correctness and consistency.
10. Archival & Retention
- Cold/older data is automatically archived into Amazon S3 Glacier for long-term storage.
- Archival logic is governed by metadata rules around data age or usage frequency.
11. Security, Access, and Monitoring
- IAM roles govern access to data and services
- Secrets used for accessing external systems are managed securely via AWS Secrets Manager
- CloudWatch monitors the serverless data pipeline’s health, and SNS sends out alerts and notifications
Key Benefits of the New Data Platform
Modern data processing needs to be fast, flexible, and easy to manage. Using metadata to control pipelines lets teams quickly make changes without redeploying.
Combined with AWS’s serverless setup, our approach scales automatically and removes the hassle of managing servers.
Here’s a full view of the benefits:
- Metadata-Driven Flexibility: The serverless data pipeline behaviour is controlled via metadata, allowing quick onboarding and changes without redeployment
- Serverless & Scalable: Zero server management with native AWS scalability built in.
- Team Collaboration: Centralized UI and metadata store enable teams to build, modify, and track data pipelines independently
- Phase-wise Deployment: Allows for incremental delivery, with current support for CSV file ingestion and future support for APIs and SQL
Build Fast, Stay Flexible: AWS for NextGen Enterprise Data Platforms
Our metadata-driven serverless data processing setup shows how AWS’s native tools can create a modular, metadata-driven, and serverless data platform. By focusing on a phased, configuration-first approach, it’s designed to grow and adapt easily, making it perfect for businesses that want speed and flexibility in their data modernization journey.
Curious about the right AWS data and analytics services for you, learn more here.



















