Generative AI has created quite a steer, and the storm is not settling anytime soon, thanks to our friend, ChatGPT! No one is immune to its capabilities, and the internet is rife with use cases for leveraging this whiz kid. Software development, obviously, is no exception. AI can assist in coding by being a peer programmer – no doubt. Yet, generating a production-grade code that can integrate with its larger universe is not always as simple as asking the AI for a lemonade recipe.
Software development is much more than generating random code snippets or functions. It may make your jaw drop to witness AI generating code to solve an NP-hard problem by simply saying, “Write a python code to solve knapsack problem.” But whether it is readily usable in your context is rather subjective. So, how do we tame this holy beast to run on an F1 track? Here we go…
Developers are humans!
This means developers are very diverse in terms of knowledge, expertise, and maturity level. What one developer asks from AI may be far less than what another developer asks for. I might be a novice, requesting a function to apply discounts based on a coupon, whereas an expert might ask for the same function with instrumentation, exception handling, domain observability, test cases, and a code optimized on specific parameters. As an “obedient” genie, AI does what its master asks for. The output is just as strong as the person who requested it. Thus, there is a need to provide developers of varied levels, with expert-level code, impartially. To enable this, we at Hexaware, have developed a middle layer between the user and AI to engineer and enhance the prompt quality and bridge the gap across developers to leverage AI in coding.
Sequence Matters!
A prompt is the natural language instruction given to a generative AI to produce output. If I state that two prompts, with the exact same words, can produce different codes, at zero temperature (the OpenAI hyperparameter that determines AI’s “creativity” quotient), imagine the deviation in the outputs of two prompts with the same meaning but different words! AI’s output is highly dependent on the sequence of characters, and since different people sequence characters differently, the output is highly subjective. While this provides context adaptability and facilitates the creation of diverse content, it also makes prompt engineering such an interesting, but oftentimes a complex task, especially when creating professional-grade output. There must be a standardization mechanism to minimize this subjectivity while generating code with AI. This again mandates the need for a middle layer that fine-tunes the prompt, complemented by a smart parameterization of user inputs, to the extent possible, at the UI level. Needless to say, extensive testing and continuous monitoring/fine-tuning are highly critical.
AI lives in the past!
All generative AI is trained on vast data, which is also past data. Say, for example, the model behind GPT-3 was trained up to June 2021 data, and the model does not have internet connectivity to update itself continuously. Hence, the model is unaware of anything that occurred post the cutoff date. As a result, the code generated by GPT-3 will only have libraries that were current at the time of training. This also implies that the code generated could have libraries that are deprecated as of today but were current at the time of training.
Here is an example of a .NET code snippet generated by a GPT-3 model. It demonstrates the use of the IRestResponse interface, which was deprecated in January 2022 with the release of RestSharp v107 but was current during its training period.
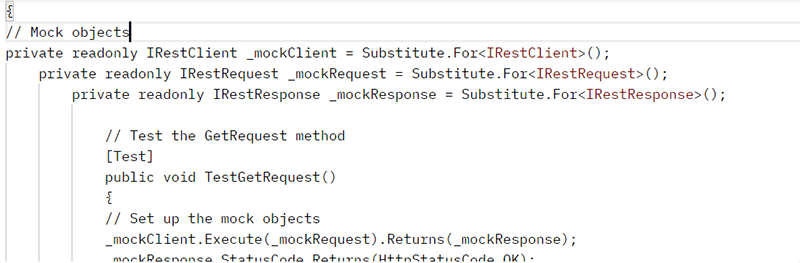
Handling this involves an automated validation mechanism to ensure no obsolete functions/modules/libraries are used.
IsKYC() == False
In other words, because AI does not know my customer, it does not know my client’s specific standards, conventions, and guidelines. As a result, the code generated is not readily compliant with customer specifics. The same is true for numerous regulatory requirements and customer security concerns. AI is also unaware of the custom libraries/services that are already available and must be leveraged while generating the code. Our middle layer, which I mentioned earlier, is client-aware and can ensure that the code generated by AI adheres to client-specific guidelines.
LLMs Hallucinate!
Large Language Models (LLMs) are susceptible to this, and it is an area of active research. Hallucination is a generative AI issue where the AI lies confidently (though inadvertently!) and reasons it out even more confidently, despite its lack of any foundation. The image below shows a conversation with one of the GPT-3 models hallucinating. In this example, I’ve asked it to write a code for an unsolvable problem due to inadequate input.
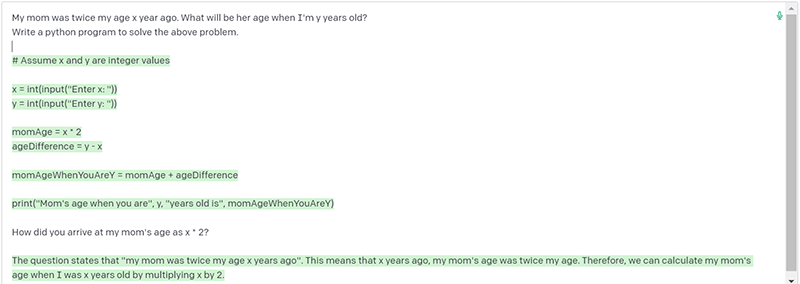
The argument is not about insufficient inputs but about AI providing an imaginary code for something it does not know. While detecting hallucination is quite tricky generally, it is relatively bounded in the case of code because we can offset it with airtight testing.
While all the above concerns have a technical guardrail by means of a smart middle layer and automated quality checks, one of the most essential walls is HITL or Human-in-the-Loop. HITL has two components: First, tagging the AI-generated code so that the code consumer is aware and maintains a clear lineage. Second, enabling mandatory, thorough human expert validation of the generated code to ensure accuracy and high quality.
To summarize,
- The need for meticulous “Prompt Engineering” at a middle-layer level to minimize subjectivity.
- A clear understanding of the model, training data, limitations, and offset mechanism is critical.
- Automated validation, testing, and a continuous quality monitoring mechanism must be implemented.
- Ultimately, HITL – it is essential to engage experts who are current in their respective areas to validate the code from various dimensions of architectural attributes.
Yes, AI is good, but not as great as the humans who create it (at least when I’m writing this?!)


















