Since November 2022, AI has continued to amaze us. The most recent jaw-dropper? OpenAI’s Sora: Text-to-Video AI Generator.
Unveiled on February 15, it is a text-to-video model that generates astonishingly realistic videos from text prompts.
If your mind is already racing about how it could revolutionize the entertainment industry, hold on to that thought. Let’s first delve into the magic behind Sora.
Luckily, OpenAI didn’t keep us in suspense for long, releasing their research paper just a few hours after the announcement. The paper “Video Generation Models as World Simulators” is available on OpenAI’s website for those inclined. This blog will guide you through the core of this technology, revealing the principles behind Sora, its unique qualities compared to other text-to-video LLMs, how it works, and its capabilities.
The Big Picture
OpenAI’s research paper unveils a grand vision for not only Sora but also for OpenAI. They write, “Our results suggest that scaling video generation models is a promising path towards building general-purpose simulators of the physical world.”
I was drawn to this statement, which provides insight into why it matters to OpenAI.
It shows that their vision goes beyond just creating a superior gen AI tool with Sora. Sure, that’s part of it, but there could potentially be a bigger game at play. One where Sora is more than an AI tool – it could be a fundamental piece in paving the way for a comprehensive real-world simulator.
The building blocks of Sora: The Patch and The Compression Network
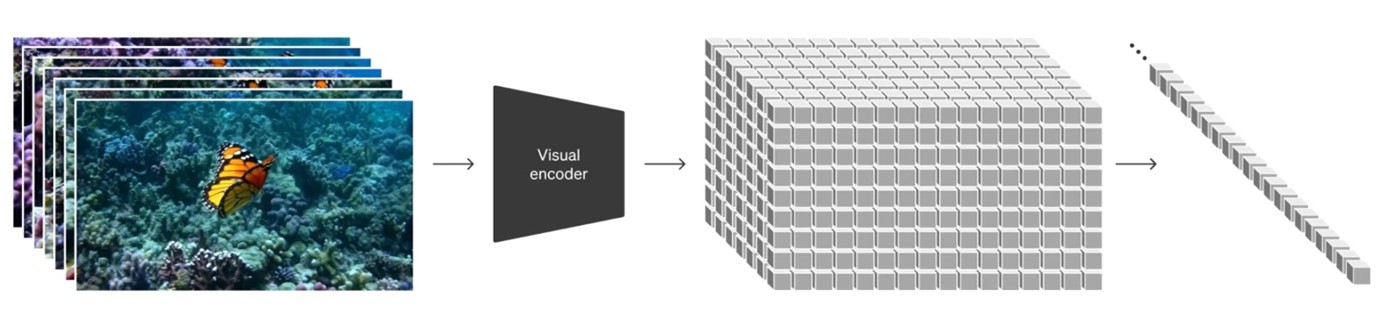
Image Source : Open AI Research Paper ‘Video generation models as world simulators’, February 15, 2024
Let’s dive into the key components of Sora—the concept of turning visual data into ‘patches.’ This technique is inspired by Language Learning Models (LLMs), known for their generalist capabilities, honed by training on a vast scale of data from the internet. The success of LLMs owes much to ‘tokens’—a method that beautifully integrates diverse types of data like text, code, math, and various languages.
As OpenAI developed Sora, they thought, “Why not apply the same concept to visual data?” Tokens are bits of words, while patches are bits of movies. Whereas LLMs have text tokens, Sora has ‘visual patches,’ a technique already proven effective in models dealing with visual data. It takes in a sequence of patches and outputs the next patch in the sequence.
What’s exciting is that these visual patches aren’t just effective; they’re also incredibly scalable. This makes them perfect for training generative models on a diverse range of videos and images. At a high level, they turn videos into patches by first compressing videos into a lower dimensional latent space and subsequently decomposing the representation into space-time patches. Cool, right?
Next, we have something referred to as a video compression network. Sora steps in as a diligent student and trains itself in this compressed, latent space. Once it’s done learning, it’s ready to create or generate new videos within this same compressed space. It’s a bit like learning a new language and then being able to write a story in that language.
Thus, given a compressed input video, Sora extracts a sequence of space-time patches that act as transformer tokens. Consider these patches as the building blocks. This process works for images, too, since images are just videos with a single frame.
Understanding Sora’s Essence: A Diffusion Transformer
![]()
Image Source : Open AI Research Paper ‘Video generation models as world simulators’, February 15, 2024
As detailed in their research paper, Sora is a diffusion model. Given input noisy patches and conditioning information like text prompts, it’s trained to predict the original clean patches. So more specifically, this makes Sora a diffusion transformer. This novel method could potentially reshape our understanding of image generation in the future.
If that sounds like jargon, don’t worry—I’ll break it down for you.
Transformers are a versatile family of machine-learning models. They excel in a variety of tasks, including language modeling, computer vision, and image generation. Additionally, transformers also ‘scale’ effectively as video models.
In this context, “scale” refers to the performance of these models as their size increases and they are given more computational power. The exciting aspect of diffusion transformers like Sora is that their performance doesn’t plateau when scaled up. In fact, the more their training intensifies, the better the video samples they generate.
So, if we were to personify Sora, think of it as an expert filmmaker. With every movie it makes, it hones its craft and delivers more impressive results.
Revolutionary Approach: Training, Flexibility, and Simulation
OpenAI has taken a unique approach to developing Sora.
Unlike past methods that typically resized, cropped, or trimmed videos to a standard size, such as four-second videos at 256×256 resolution, OpenAI trained data at its native size.
This has two advantages: one is sampling flexibility. Sora can sample widescreen 1920x1080p videos, vertical 1080×1920 videos, and anything in between. This allows Sora to create content directly at the native aspect ratios of different devices. It also enables Sora to quickly prototype content at lower sizes before generating it at full resolution using the same model.
The second advantage they found was that training on videos at their native aspect ratios enhances composition and framing.
Remarkable Capabilities
- Animation Magic: Sora can transform simple 2D images into lively 3D animations.
- Video Extension: Have an AI-generated video you want to lengthen? No problem. Sora can extend it both forward and backward, creating an infinite loop.
- Dynamic Camera Motion: Sora can generate videos where the camera shifts and rotates, giving a sense of depth and realism.
- Long-Range Coherence and Object Permanence: Sora ensures that people, animals, and objects persist in the video, even when they’re occluded or leave the frame. It can consistently maintain a character’s appearance throughout a video.
- Interacting with the World: It can interact with its environment. A painter leaving strokes on a canvas, a man eating a burger, and leaving bite marks – Sora can simulate these minute details, adding depth to its creations.
- Simulating Digital Worlds: Sora can create high-fidelity simulations of digital worlds.
Our Point of View
OpenAI’s Sora demonstrates that anyone can generate visually stunning content from a simple text prompt.
However, to elevate video art, create thought-provoking cinema, and produce great games, we need more control. It’s essential to fine-tune every detail of the outputs based on our specific project requirements. For this, we will require more sophisticated tools and interfaces to interact with this generative AI.
Guardrails are also paramount to prevent misuse and ensure ethical, responsible use of AI technology. These could include access levels, IP protection, and watermarks to detect deep fakes. The goal is to harness the power of Sora effectively, with appropriate security and governance.
Everything I’ve observed reaffirms that we may be living in a post-X world again. This time, X is not ChatGPT but Sora. What makes Sora revolutionary is that OpenAI took a completely different approach to developing Sora. Training data at its native size provides sampling flexibility while increasing composition and framing. This produces the breathtaking videos you see.
Will it have as significant an impact? That’s difficult to predict.
To explore more about our solutions, visit Data & AI Solutions


















