The ability to access high-quality data in real time is crucial for businesses. Whether it’s driving customer engagement, improving operations, or meeting compliance standards, accurate data powers better decisions. As enterprises grow, they often face the challenge of managing data from a wide variety of systems. Further, manual data handling introduces errors and limits the ability to scale.
A 2024 HFS Market Impact Report reveals that enterprises are grappling with a growing burden of ‘data debt’, with over 40% of organizational data deemed unusable because it is unreliable, outdated, or inconsistent. This poor data quality results in a staggering opportunity cost of 25%–35% across critical business metrics such as customer satisfaction, decision-making, employee productivity, revenue, and compliance.
Alarmingly, only one-third of enterprises are satisfied with their data management initiatives, and less than 40% have mechanisms to quantify the impact of bad data.
Becoming Aware of Your Data Quality Challenge
Traditional ETL tools and manual data validation are no longer sufficient for modern enterprises. These methods are slow, labor-intensive, and often struggle to keep up with the increasing variety and volume of data—whether it’s real-time, batch, or historical information coming from different systems.
With business-critical data arriving from multiple sources and in varying formats, ensuring data quality becomes a complex, time-consuming task that’s prone to human error. This not only slows down reporting but can also erode trust in analytics and decision-making.
According to Forrester, ETL software still dominates the data integration landscape for high-volume batch movement, but struggles with real-time integration, data quality, and metadata management.
Modern businesses are using cloud platforms and AI-powered tools to solve their data challenges, with intelligent automation to bring data together, checking its accuracy, and cleaning it up. While AI and machine learning spot errors, keep an eye on data quality, and make managing data easier.
Why Choose Google Cloud Platform for a Metadata-driven Data Framework
Google Cloud Platform’s strong data capabilities bring relief to business’ data challenges. When used by an experienced data and analytics service company like Hexaware, businesses are seeing how metadata-driven and automated data frameworks are a solution to many of its challenges.
Business teams can benefit from faster access to clean, trusted data—with the framework designed to simplify data ingestion, enforce data quality checks, and make the entire pipeline scalable and adaptable.
Furthermore, Google Cloud Platform’s (GCP) powerful tools like Google Data Cloud, new AI agents for data analytics, Data Studio, and more to help companies quickly access, clean, and build trust in their data.
Building the Metadata-Driven Architecture on Google Cloud Platform
Hexaware’s automated data ingestion framework on Google Cloud Platform uses metadata to automate and manage how data moves through the system. This means less manual work, more flexibility, and the ability to handle more data as your business grows. As a result, business teams get useful insights faster and more efficiently.
Your metadata-driven data ingestion framework built on GCP should collect data automatically from your company’s databases and applications, whether it comes in real-time or in batches. What it does:
- It checks the quality of the data as soon as it arrives: completeness, accuracy, and free of errors.
- It flags any issues immediately so teams can fix them before they cause problems for business.
- It shows easy-to-understand dashboards so everyone can see the health of the data in real time.
Solution Architecture and How to Build it
Here’s a step-by-step guide to building your metadata-driven data ingestion framework on Google Cloud Platform (GCP).
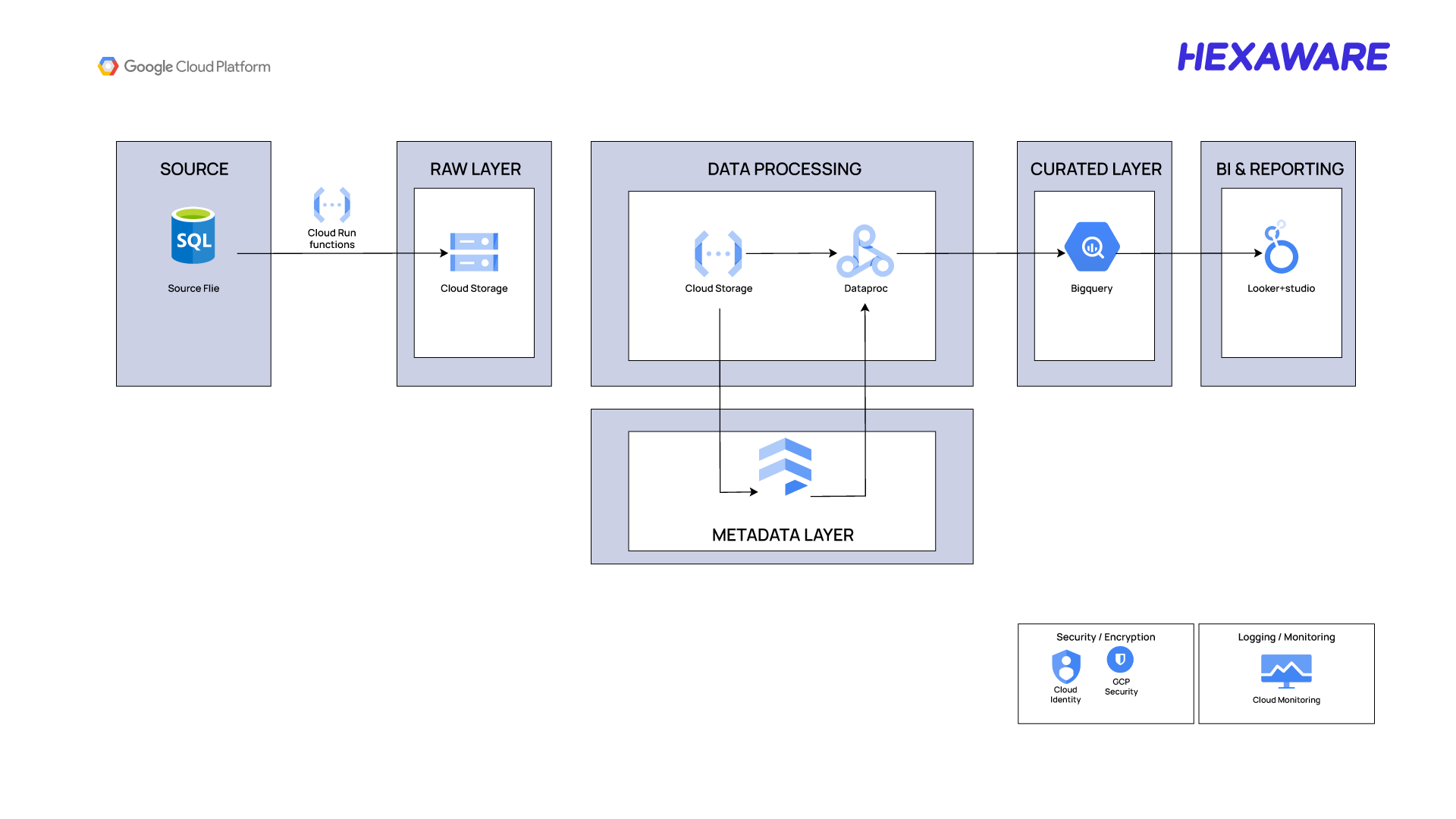
Solution Architecture Fundamentals
Set Up the Source Systems
- Identify the data sources (e.g., SQL databases, files, APIs).
- Configure the source systems to export data in a format compatible with GCP tools.
Ingest Data into the Raw Layer
- Use Cloud Run to orchestrate ingestion workflows and Cloud Storage to land raw data into the Raw Layer.
- Ensure the data is stored in its original format for traceability and auditing.
Establish the Metadata Layer
- Create a metadata repository using Firestore.
- Define metadata schemas to capture details such as data source, format, lineage, and quality rules.
Process Data in the Data Processing Layer
-
Use Cloud Dataproc to process raw data.
-
Leverage metadata from the Metadata Layer to automate validations and checks.
Store Processed Data in the Curated Layer
- Load the transformed data into BigQuery for analytics and reporting.
- Organize data into datasets and tables optimized for querying.
Enable BI and Reporting
- Connect Looker Studio or other BI tools to the Curated Layer.
- Build dashboards and reports to visualize insights and support decision-making.
Implement Security and Monitoring
- Use GCP Security features like IAM, encryption, and VPC to secure data.
- Set up logging and monitoring with tools to track performance and detect issues.
Iterate and Optimize
- Continuously update metadata definitions to accommodate new data sources and formats.
- Optimize data pipelines for performance and scalability.
This framework ensures scalable, automated, and high-quality data ingestion for analytics and decision-making.
Understanding the Data Movement
Understand the metadata-driven data ingestion framework on Google Cloud Platform (GCP). It demonstrates the flow of data from source systems to business intelligence (BI) tools, ensuring automation, quality, and scalability.
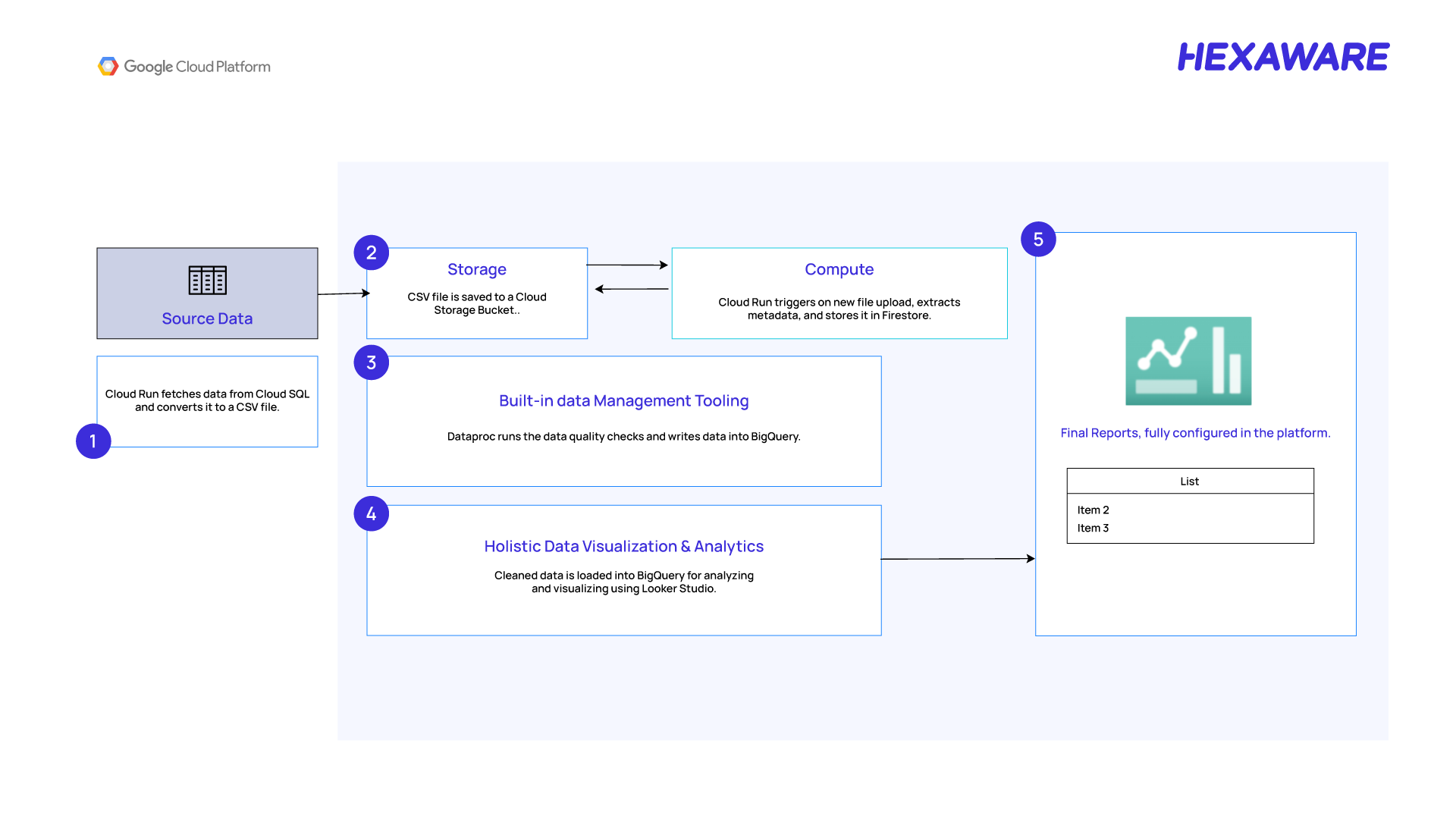
- Automated Data Movement: Every 30 minutes, our system connects to your on-premises database (like SQL Server), pulls the latest data, and uploads it to Google Cloud.
- Cloud Storage: The incoming data is first stored securely in Google Cloud Storage. This acts as a central landing zone before any processing begins.
- Smart Processing:As soon as new data lands in the cloud, an automated process kicks in. It reads the data, checks its quality using predefined rules, and flags any records that donʼt meet standards.
- Dynamic configuration via Firestore: All the rules and configurations are stored in Firestore. If you want to change a rule or add a new data source, you simply update the settings—no coding required.
- Data Quality Insights: The results of these checks are stored in BigQuery, Business users can instantly see data quality metrics—like completeness, accuracy, and trends—on interactive dashboards in Looker Studio for reporting and analytics, supporting better business decisions.
Key GCP Services in Our Solution
|
Service |
Role in the Solution |
Feature Highlights |
|
Firestore |
Stores dynamic configurations and rules for automated data processing. |
Handles large-scale metadata with better monitoring, easier updates, and multi-region support. |
|
Dataproc |
Runs data quality checks using scalable Spark jobs. |
Now supports serverless Spark, easier job tracking, and built-in security improvement. |
|
BigQuery |
Stores clean data and data quality results for analysis and reporting. |
Offers AI-assisted insights, improved forecasting, and unified metadata management. |
| Google Cloud Storage |
Stores both raw data from source systems and processed output for further use. |
Faster file access, smarter storage controls, and better cost optimization. |
|
Cloud Run |
Runs ingestion and validation workflows automatically, without managing servers. |
Launches faster, scales reliably, and supports secure network connectivity. |
|
Looker Studio |
Visualizes data quality metrics and trends via real-time dashboards. |
More interactive visuals, quicker refresh times, and seamless BigQuery integration. |
How These Power Our Framework
Firestore: Stores all pipeline configurations and DQ rules, enabling dynamic, metadata-driven execution. Recent updates include bulk delete capabilities, multi-region support, and improved monitoring, making it even more robust for enterprise-scale metadata management.
Dataproc: Runs scalable Spark jobs for data processing and validation. The latest releases bring new serverless Spark runtime versions, enhanced security, and a Spark UI for easier monitoring and debugging, ensuring high performance and reliability for large-scale data workloads.
BigQuery: Acts as the central analytics engine, storing both imported data and DQ results and historical summary of it. New features like BigQuery Metastore for unified metadata management, Gemini AI for natural language data preparation, and advanced forecasting models further enhance analytics and governance capabilities
Google Cloud Storage: Serves as the centralized storage layer for both raw ingested files and processed outputs. It ensures reliable, cost-efficient data storage across the pipeline. Recent improvements in data availability, smarter lifecycle rules, and faster access help streamline processing and reduce operational overhead.
Cloud Run: Enables event-driven execution of ingestion and validation workflows without managing infrastructure. It provides a fully serverless environment that scales on demand. With recent updates like reduced cold start times and better VPC integration, Cloud Run ensures faster, more resilient automation across the pipeline.
Looker Studio: Delivers real-time visibility into data quality through interactive dashboards built on BigQuery. It empowers business users to monitor trends and catch issues early. Enhanced customization, faster refresh rates, and seamless BigQuery integration make reporting more agile and user-friendly.
Bring in Metadata-Driven Flexibility for Business Operations
A core advantage of this framework is its metadata-driven flexibility, primarily enabled by Firestore. As a metadata repository enables unprecedented flexibility in pipeline management:
- Dynamic Pipeline Logic: Pipeline configurations and DQ rules can be updated in real time by modifying metadata in Firestore, eliminating the need for code changes or redeployments.
- Rapid Onboarding: New data sources or validation checks are added simply by updating metadata templates, ensuring quick adaptation to evolving business needs.
- Audit Trails: Every configuration change is tracked, supporting compliance and providing a transparent history for governance purposes.
- Configurable DQ Checks: Enable or disable data quality validations through metadata flags, optimizing processing efficiency and aligning with business priorities.
This powerful adaptability directly translates into tangible business benefits: accelerated time-to-insight, reduced operational overhead, and the agility to respond instantly to market data shifts.
Using all these easy updates, Firestore enables seamless updates to pipeline logic and DQ rules. Changes can be made in metadata without redeploying code, supporting agile business needs.
Adding new data sources or modifying validation checks is as simple as updating metadata entries, allowing rapid scaling and adaptation to evolving requirements.
To conclude, the metadata-driven approach fundamentally transforms how enterprises manage data pipeline automation, shifting from rigid, code-centric processes to flexible, configuration-based operations that respond dynamically to changing business requirements.
Business Impact of the Framework
Gartner reports that to ensure maximum business value from your data, analytics and AI investments, enterprises must adopt a strategy that is outcomes-led and aligned with enterprise-wide priorities. Here’s how a metadata-driven ingestion framework has had a strong and measurable impact on business:
- Quicker Reporting and Analytics
Real-time ingestion and validation make high-quality data available sooner, allowing teams to act on insights without delay. - Lower Manual Effort and Fewer Errors
The framework minimizes routine data checks and manual interventions, saving valuable time and reducing the risk of human error. - Optimized Costs and Improved Scalability
Using serverless tools like Cloud Run and scalable services like Dataproc means resources are used efficiently and can grow as needed. - Better Business Decisions with Trusted Data
Dashboards built in Looker Studio provide full visibility into data quality. Business teams can now monitor key metrics and spot issues early, increasing confidence in every decision.
Our framework turns data into a strategic asset by combining automation, transparency, and agility. It’s built not just for today’s challenges, but also for tomorrow’s opportunities.
The Data Environment Benefits
A leading enterprise has already deployed this framework, proving its ability to handle large-scale, complex data environments and transform the way data is managed.
- Automated Ingestion: Data now moves automatically from different on-premises systems into Google Cloud. This cuts out manual work, reduces operational costs, and allows teams to focus on more important tasks.
- Real-Time Data Quality Insights: The system checks data quality instantly and flags issues right away. Business users can spot and fix problems within minutes, ensuring decisions are always based on reliable data.
- Scalable Across Data Sources: The framework supports a wide range of data—from old legacy systems to modern real-time apps—and easily handles massive volumes. It works just as well for big batch loads as it does for live streaming data, without slowing down.
- Flexible and Future-Ready: Thanks to metadata-driven orchestration, the framework adapts as business needs change. It can support new data types, growing volumes, and more complexity without needing major redesigns.
The metadata framework delivers real business value by combining automation, trusted data quality, and the ability to scale effortlessly.
A Quick Recap on What Business Should Aim For
Your metadata-driven approach ensures that operational knowledge is captured and preserved, reducing dependency on individual expertise. Automated processes reduce manual effort, eliminate routine errors, and provide consistent, reliable data processing. Building it on GCP empowers you to:
- Achieve operational efficiency through data automation, reducing manual efforts.
- Ensure data integrity and governance with robust, configurable validation rules.
- Rapidly adapt to changing business requirements and integrate new data sources
- Modify processing logic without code changes to respond quickly to opportunities.
- Deliver timely, actionable insights to business users via real-time dashboards.
- Build cloud-native architecture with intelligent resource scaling optimizes costs.
- Prepare for future expansion, including AI integration and increased automation.
Improve Data Strategy with Hexaware and Google Cloud
The future of data management lies in intelligent, automated systems that adapt to business needs while maintaining the highest standards of quality and governance. Enterprises that begin this transformation today will be best positioned to capitalize on the data-driven opportunities of tomorrow.
While seeking to modernize your data, adopting a data ingestion framework built on GCP can be pivotal to the pace of business growth. Hexaware helps with Google Cloud data and analytics services that help you accelerate your journey.




















