As data management evolves, the challenges businesses face, especially concerning the escalating costs of on-premises data warehousing (DW) solutions, are multifaceted. CTOs strive to maintain optimal technological infrastructure for business operations and innovation, while CFOs focus on prudent financial management, minimizing unnecessary expenditures, and maximizing returns on investments.
As part of our ongoing series on data management with the cloud, we delve into the impact of data warehouse strategy on technological agility, financial viability, and overall scalability. This installment focuses on the benefits of shifting from an on-premises data warehousing (DW) to an Azure cloud environment and the best practices to strategize a smooth shift.
Additionally, we delve into how data engineering platforms built with Azure Data Lake Storage support high-performance business analytics, enable intelligent automation, and facilitate the latest data capabilities.
Azure Data Lake Storage: Powering Your Data Engineering Platforms
Embark on a transformative journey into the future of data-driven insights with Azure Data Lake Storage, one of the top solutions to consider. Redefine how your business extracts valuable information and unlocks the full potential of its data assets.
Its latest version, Azure Data Lake Storage Gen2, has been described by Microsoft as ‘The world’s most productive Data Lake.’ Migration to this advanced data engineering platform unlocks a new outlook. It pioneers innovative frontiers through optimized storage tiering, seamless integration of analytics services, and robust security features, setting a new standard in data management excellence.
In this blog, we explore the importance of Azure Data Lake Storage as Storage as a Service (STaaS), its distinctive features, the business impact it creates, and industry scenarios where it unlocks significant business value.
Further, we delve into how to create a data lake within the Azure ecosystem that addresses the initial challenges of connecting with diverse external sources and establishing a foundational layer to house raw data.
Key Features for Advanced Analytics
Azure Data Lake Storage (ADLS) transforms the part that data management plays in enterprise-wide analytics, helping build effective data engineering platforms. Its support for multiple data processing frameworks like Apache Spark, Azure Databricks, and U-SQL facilitates versatile data transformations, real-time analytics, and machine learning initiatives.
Combined with its cost-effective storage model and seamless integration with Azure services, Azure Data Lake empowers data engineering platforms to efficiently manage, process, and derive insights from large-scale and diverse data sets, driving innovation and decision-making across the organization.
Specific features powering advanced analytics within the Azure environment:
- Limitless Scalability: Handles massive data volumes, accommodating structured and unstructured data.
- Storage Tier Flexibility: Offers multiple storage tiers (Hot, Cool, and Archive) and optimizes costs based on data access patterns, ensuring efficient data lifecycle management.
- Seamless Integration: Seamlessly integrates with Azure Databricks, HDInsight, and Synapse Analytics, fostering a comprehensive data ecosystem.
- Security and Compliance: Built to maintain robust security measures, including Azure AD integration, Role based Access Control (RBAC), and encryption, ensuring data protection and regulatory compliance.
- Analytics Capabilities: Supports various analytics engines like Spark and Hive and empowers organizations with advanced data analytics features.
Business Impact it Delivers
Azure Data Lake Storage (ADLS) revolutionizes data management, delivering impactful business benefits that align with your organizational strategy.
- Data-Driven Decision Making: ADLS facilitates storing, processing, and analyzing extensive datasets, empowering data-driven intelligence across the enterprise.
- Cost Efficiency Through Storage Tiering: The cloud warehouse offers storage tiering options to optimize costs based on data access patterns, ensuring data access capabilities are aligned with your budget.
- Accelerated Analytics and Business Intelligence: It supports a robust suite of analytics services and capabilities that accelerates data analytics and report deliveries.
Industry Use Case Scenarios
Azure Data Lake is transforming businesses across various industries. Here are a few examples to demonstrate how it is unlocking new opportunities for industry-specific use cases and keeping companies ahead of industry trends.
- Retail: Azure Data Lake enables analysis of customer purchasing patterns, sentiment from social media, and inventory management for optimized pricing and personalized marketing.
- Healthcare: Supports managing patient data, medical records, and clinical trial data for predictive analytics, treatment optimization, and research initiatives.
- Financial Services: Utilized for fraud detection, risk management, and compliance reporting, analyzing transactional data to detect suspicious activities and provide insights for informed decision-making.
- Manufacturing: Enables predictive maintenance, supply chain optimization, and quality control by integrating IoT sensor data for equipment monitoring and production efficiency.
- Telecommunications: Used for network performance monitoring, customer churn prediction, and targeted marketing by analyzing call detail records and customer interactions for hyper-personalized services.
- Company HR system: Serves as a central hub for generating comprehensive reports on employee data, facilitating effective policy formulation, and contributing to employee and organizational wellbeing.
Your Roadmap for Setting up a Data Lake with Azure
Creating a data lake is a strategic endeavor that demands meticulous planning and execution. Here are essential steps to ensure a seamless and effective implementation:
- Configure Self-Hosted Integration Runtimes (IR):
Begin by setting up self-hosted integration runtimes, ensuring a robust connection to each data source. A deep understanding of each source system is crucial for configuring integration runtimes effectively.
- Establish Connectivity from ADF to Source Systems:
Create a reliable connection between Azure Data Factory (ADF) and each source system. This step is foundational for seamless data movement and processing within the data lake architecture.
- Implement Backup and Disaster Recovery Plans:
Prioritize the establishment of comprehensive backup and disaster recovery plans. Adhering to Azure’s guidelines ensures that your data lake remains resilient in the face of unforeseen challenges, safeguarding critical data assets.
- Deploy Data Quality and Lineage Tracking:
Enhance the integrity of your data lake by implementing robust data quality and lineage tracking mechanisms. Leverage tools like Azure Purview or build custom solutions using Azure Data Factory (ADF) and Synapse to gain insights into data quality and lineage.
- Establish Role-Based Access Control (RBAC):
Security is paramount. Implementing Role-Based Access Control (RBAC) ensures that data access is secure and controlled. Define roles and permissions meticulously to safeguard sensitive information within the data lake.
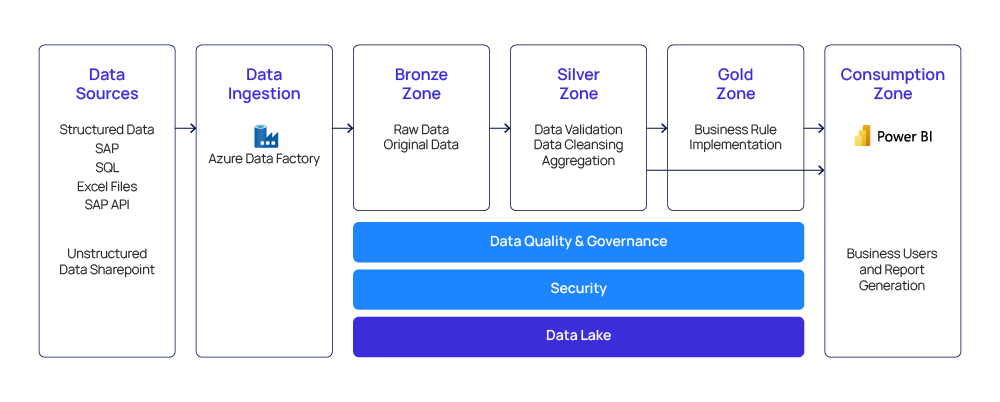
Figure 1: Building a Data Lake with Azure
How to Migrate from Different Data Sources to Azure Data Lake
Efficient migration is vital for data engineering platforms as it ensures seamless transitions from legacy systems to modern cloud environments, minimizing downtime, maintaining data integrity, and optimizing costs. Azure facilitates efficient migration through specialized services like Azure Data Migration services, Azure Database Migration service, and Azure site recovery, providing automated assessment, compatibility checks, and disaster recovery solutions.
Its comprehensive services help migrate different data types such as SQL Data, transferring document data using API, and SAP API data from on-premises environments to Azure Data Lake Storage. Businesses can adopt best practices for an effective migration by adopting a methodical approach that considers the intricacies of different data types.
Let’s explore the different migration steps for different data sources:
| Data Sources | Migration Steps | Considerations |
| SQL Data |
1.Assess SQL schema and data volumes. 2.Connect Azure Data Lake to SQL On-premises with Azure Self-hosted Integration. 3.Employ Azure Data Factory for ETL. 4.Extract SQL data into Azure Data Lake Storage. |
1. Ensure SQL version compatibility. 2. Implement incremental extraction using existing watermark columns. 3. Prioritize security and encryption during transit. 4. Maintain data consistency and integrity. |
| Transferring Document Data using API |
1.Identify document types and structures. (e.g., JSON, XML, CSV, Excel, JPEG, docx). 2.Understand endpoints and authentication mechanisms. 3.Use Azure Data Factory or Azure Synapse with Python API for ingestion. 4.Transform document data to/from base64 for Data Lake storage. 5.Store transformed data in Azure Data Lake Storage. |
1. Address nested structures and incremental transfer using unique identifiers like File ID. 2. Implement compression techniques for storage optimization. |
| SAP API Data |
1. Understand SAP API endpoints and authentication mechanisms. 2. Develop connectors or custom Python scripts for data extraction from SAP. 3. Use Azure Data Factory or Azure Synapse for data ingestion. 4. Store SAP API data in Azure Data Lake Storage. |
1. Ensure secure authentication and authorization with SAP APIs. 2. Handle pagination effectively. 3. Implement error handling and retries for API calls. 4. Adhere to SAP data access policies. |
Azure Data Lake Use Case: Consulting Firm Improves HR Reporting
Let’s explore the process and steps involved in setting up a data lake for a client, and examine the approach used to improve data delivery and construct a resilient data lake infrastructure with Azure Data Lake Storage Gen2.
A leading management consulting firm wanted to establish a data lake for integrating and storing data from their transaction systems. Our task involved constructing a data engineering platform using a blend of Azure tools to meet specific needs such as data residency requirements, local reporting requirements, and fulfilling data requests from other solutions in its ecosystem.
Our client needed to upgrade its reporting capabilities for their HR data. Their existing on-premises system comprised diverse source systems such as SQL Server, SAP, SharePoint, along with various other Microsoft files, encompassing approximately 300+ tables. Azure Data Factory (ADF) was utilized as the ETL tool, Synapse for building and maintaining Delta tables, and Python for transferring documents in various formats such as PDF, JPEG, Word, and Excel. Due to an older version of SharePoint, we employed a custom PowerShell script for migrating SharePoint data.
This approach allowed us to perform atomicity, consistency, isolation, and durability (ACID) operations on the data and improve cost-effectiveness. The data lake was also a step up compared to Azure SQL DB, which only supports structured data and transactional workloads. Whereas Azure Data Lake is designed for big data analytics, unstructured data processing, and machine learning on diverse data types.
To ensure ongoing efficiency, we implemented a strategic approach known as incremental logic using control tables and adopted a plug-in/plug-out methodology. This innovative approach allows us to flexibly manage the migration of specific tables or databases based on future business requirements.
Conclusion: Towards Platform-based Data Operations
As we conclude our exploration of Azure Data Lake Storage, it can be said that Azure offers a scalable and cost-effective solution for managing both structured and unstructured data. Its versatility makes it an excellent choice for accommodating a wide range of data sources, supporting the foundation of platform-based DataOps.
By adopting our systematic approach and considering the unique attributes of different data types, you can harness the data lake’s full potential. It empowers you to build an efficient data engineering platform capable of building valuable big data analytics processes to transform your business intelligence and drive innovative data strategies.
For further insights on how Hexaware can assist in strategizing your data landscape for optimal utilization and enhancing your business acumen with the latest data capabilities, visit: Data & AI Solutions | Hexaware


















