In the dynamic landscape of cloud data engineering, AWS Lambda has emerged as a transformative force in the realm of serverless computing, empowering developers worldwide to construct scalable applications without the encumbrance of server management. However, a major stricture with AWS Lambda’s runtime is the prescribed runtime limitation of 15 minutes for long-running tasks. In today’s era characterized by an unprecedented surge in data generation, data engineers and data scientists frequently encounter challenges in effectively processing and deriving data-driven insights due to this restriction. Consequently, they are actively seeking viable solutions to address data processing, complex computations, and protracted workflows.
This blog delves into the experiences of one of our distinguished clients, a leading provider in the financial markets, who confronted challenges while consolidating vast amounts of data from diverse sources into a robust data lake using AWS Lambda for executing long-running tasks. We will explore how they harnessed Parameter Store and EventBridge to unlock the full potential of a serverless architecture, enabling seamless handling of extended tasks and effectively overcoming the runtime limitation of AWS Lambda.
Concept of AWS Lambda, EventBridge, and Parameter Store
AWS Lambda is an event-driven, serverless computing platform provided by Amazon as a part of their Amazon Web Services. Hence, users are relieved from the concerns of selecting and managing AWS resources. All they need to do is deploy their code on AWS Lambda, and it will execute seamlessly whenever required, scaling automatically.
AWS EventBridge is a serverless event bus that enables developers to build event-driven applications. It is a central hub for receiving and routing events from various AWS services, custom applications, and third-party sources. It provides a way to decouple services and serves as a secure platform for building event-driven architecture.
AWS Parameter Store is a secure and scalable storage service for the configuration of data and secrets management. It allows users to store and manage sensitive information such as database credentials, API keys, and configuration values. The Parameter Store offers a hierarchical structure, making organizing and retrieving parameters across multiple applications and environments easy.
Problem Statement and Hexaware Solution
One of our clients, a leading provider of financial markets data, received large volumes of data from various sources. Each source had different data formats, structures, and update frequencies. The client needed a robust and flexible solution for consolidating and storing data in their data lake.
They sought a solution to ingest raw data from numerous sources into a data lake. Additionally, they needed the transformed and consolidated data to be easily accessible for analysis and reporting purposes by business users.
We proposed an approach involving executing an AWS Lambda serverless function to process large volumes of data. Yet, we faced a problem processing the entire result set due to the runtime limitation of 15 minutes, leading to incomplete data processing.
To overcome the challenges, we proposed a solution that utilizes AWS services, including AWS Lambda functions, Parameter Store, and EventBridge.
Solution
The data was ingested using feed files or API calls, utilizing AWS services. AWS Lambda functions (developed with Python) were employed to handle the API calls and retrieve the responses in various formats, such as JSON files or XML. The extracted files were stored in AWS S3 Buckets and then ingested into Snowflake using AWS Lambda functions.
1. Creating AWS Lambda Functions with Python
Python code can be used for creating the AWS Lambda function to fetch responses from REST APIs and save them in an AWS S3 bucket.
While creating an AWS Lambda function to run Python code, choose the Python version as shown below:
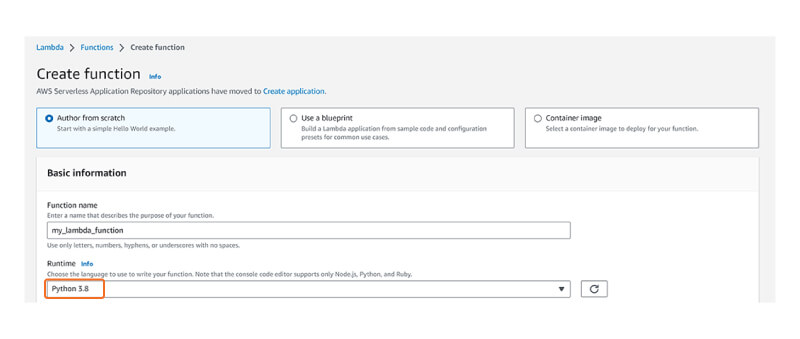
Figure 1: AWS Management Console: Creating AWS Lambda Function
To use Python libraries, click on layers and choose the default AWS-provided layer. Please refer to the snapshots below for further guidance.
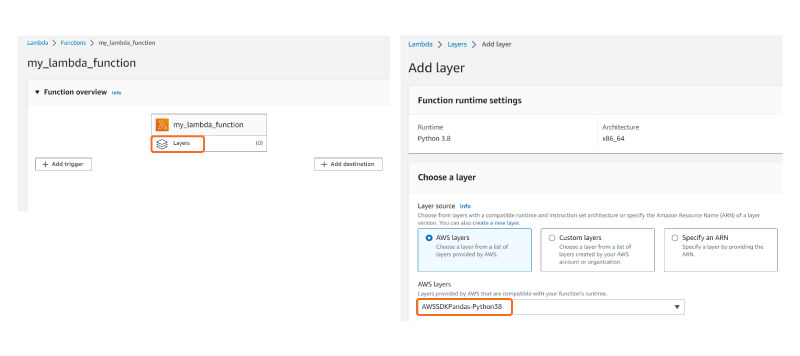
Figure 2: AWS Management Console Demonstrating the Usage of Python Libraries
Enter the Python code in the AWS Lambda function.
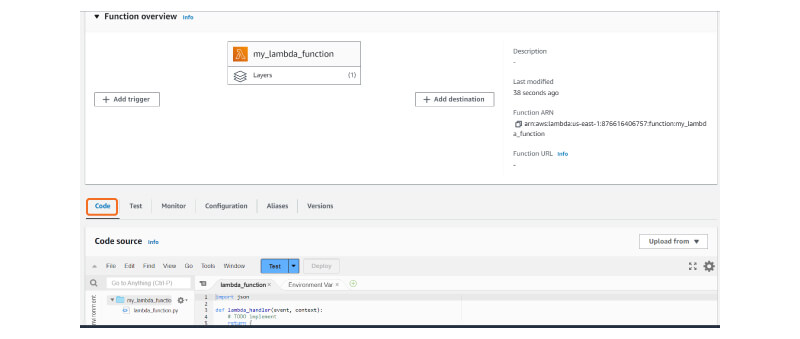
Figure 3: AWS Management Console Illustrating the Process of Adding Python Code
For example, the AWS Lambda function was scheduled to run every 20 minutes between 6 AM and 9 AM. Upon being triggered at 6 AM, the initial file count was 0. The code would then execute, updating the file count value accordingly. For example, if the API result contained 600 elements and AWS Lambda processed 400 elements, the file count value in the Parameter Store would be updated to 400.
2. Schedule the AWS Lambda Function Using Amazon EventBridge
Click on Add a Trigger and choose Amazon EventBridge. Then, either create a new rule or select an existing rule.
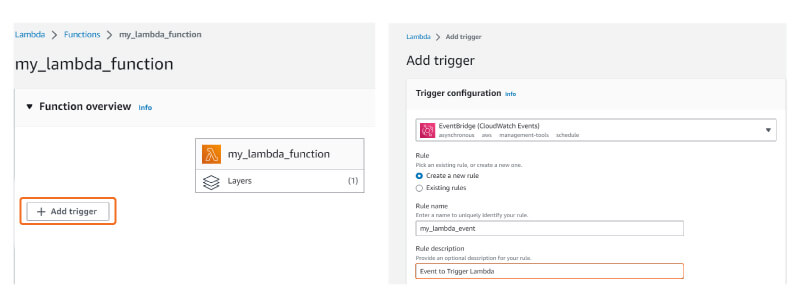
Figure 4: AWS Management Console Demonstrating the Triggering of a Lambda Function Using EventBridge
Schedule the time to trigger the AWS Lambda Function.
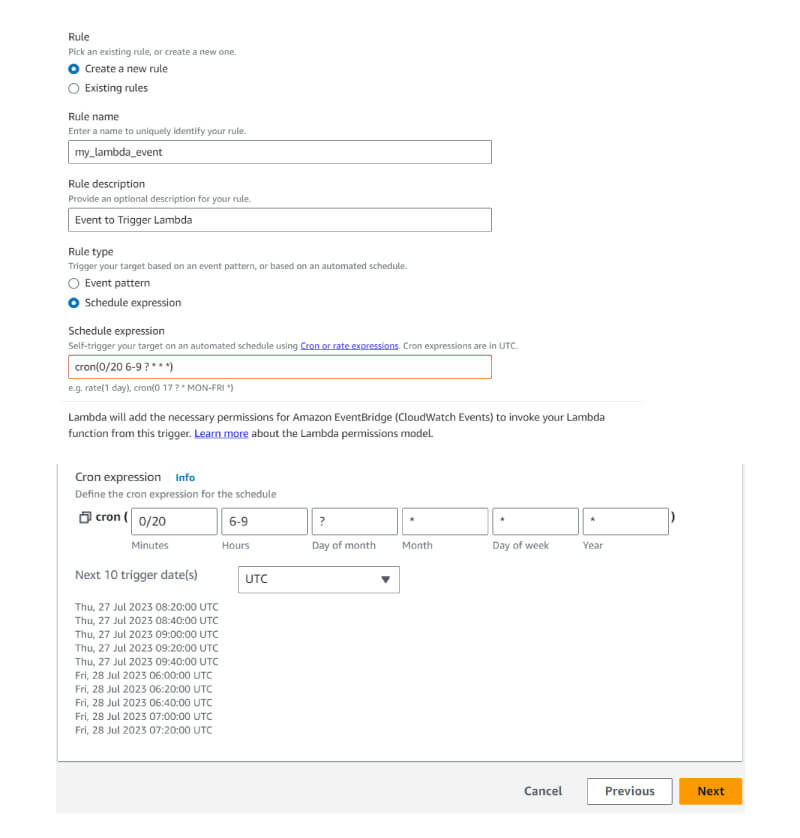
Figure 5: AWS Management Console Showcasing the Use of a Cron Schedule to Trigger a Lambda Function
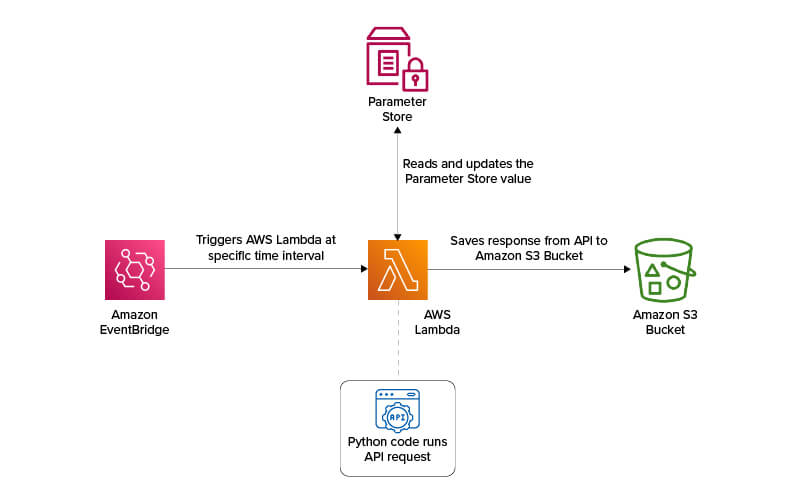
Figure 6: Architecture representation to overcome Lambda Runtime Execution Limitation
As depicted in the illustration above, Amazon EventBridge would trigger another AWS Lambda function using the parameters stored in the Parameter Store, where the loop would begin from 400. Once all 600 elements were processed, the file count value was reset to 0 in the Parameter Store.
In the next AWS Lambda execution, the API request code will not run based on the time condition. This prevents repetitive API calls after completion, as there is no need to call the API once all the data has been processed.
AWS Lambda’s 15-minute execution limit makes executing the code on a local machine challenging without Parameter Store and Amazon EventBridge.
By combining the services, a solution was designed where long-running processes were divided into smaller, manageable tasks triggered by Amazon EventBridge.
Business Benefits
By using AWS EventBridge and Parameter Store, we built a distributed and scalable architecture that overcame the limitations. This architecture offered cost savings compared to running long-running processes on EC2 instances.
- With AWS Lambda, the client only had to pay for the actual execution time of the function, eliminating the expense of running idle EC2 instances.
- Since AWS Lambda takes care of the underlying infrastructure, there was no requirement to manage and maintain the EC2 instances, resulting in reduced operational overhead.
Pseudo Code
The pseudo-code below explains how the AWS Lambda function code used Parameter Store to run the API request based on the result of another API request.

Conclusion
In conclusion, AWS Lambda offers serverless architecture that eliminates the concerns of provisioning and managing servers, as well as the need for virtual machine setup. With lightning-fast code execution in milliseconds, it serves as an efficient Platform-as-a-Service (PaaS) for executing backend code. By harnessing the power of AWS Lambda, alongside Parameter Store and Amazon EventBridge, we can successfully overcome the challenges associated with running API requests based on the results of other requests or with pagination.
To delve deeper into Amazon EventBridge and Parameter Store for Long-Running tasks, reach out to our team of experts. Contact us at marketing@hexaware.com for further information.


















