In data management, achieving efficient query performance has long been a challenge. Traditional data layout techniques such as partitioning and Z-Ordering required constant fine-tuning, often demanding significant upfront planning and ongoing maintenance.
Enter liquid clustering, a revolutionary technique introduced by Databricks with Delta Lake 3.0. This method promises self-tuning data layouts that dynamically adjust based on changing workloads, providing unmatched flexibility and performance. In this blog, we will explore liquid clustering, delve into its advantages, and present real-world case studies that showcase its impact on large-scale data environments.
What is Liquid Clustering in Databricks?
Liquid clustering is a smart data layout strategy designed to replace traditional partitioning and Z-Ordering in Delta Lake tables. The approach dynamically organizes data based on clustering columns, eliminating the need for complex and static partitioning schemes. Unlike its predecessors, liquid clustering evolves with the data, adapting to new query patterns and workloads over time.
The technique offers several key benefits:
- Simplicity: Users can define clustering keys on columns most frequently queried, without needing to worry about column cardinality or partition order.
- Flexibility: Clustering keys can be redefined without the need to rewrite existing data, allowing the layout to evolve as analytics needs change.
- Self-tuning: Automatically adjusts to prevent over- and under-partitioning, ensuring optimal performance.
- Skew-resistant: Ensures consistent file sizes and minimizes write amplification, leading to efficient storage.
- Efficiency: Liquid clustering incrementally clusters new data as it is written, improving query performance without increasing write costs (Databricks,Delta Lake).
Databricks recommends liquid clustering for all new Delta tables. The following are examples of scenarios that benefit from clustering:
- Tables are often filtered by high cardinality columns.
- Tables with significant skew in data distribution.
- Tables that grow quickly and require maintenance and tuning effort.
- Tables with concurrent write requirements.
- Tables with access patterns that change over time.
- Tables where a typical partition key could leave the table with too many or too few partitions.
Databricks Liquid Clustering v/s Partitioning
One of the primary challenges with traditional data layout techniques like partitioning and Z-Ordering is their rigidity. Once a partitioning scheme is set, it often requires constant monitoring and manual adjustment to keep up with changing data patterns. This can be both time-consuming and expensive, particularly for large tables with billions of rows.
In contrast, liquid clustering automatically adjusts the data layout based on real-time query patterns. This flexibility makes it particularly useful for tables with high-cardinality columns, skewed data distributions, or rapidly growing datasets. It also reduces the engineering overhead associated with managing partitioning strategies, as seen in traditional hive-style partitioning (Delta Lake, Databricks).
What you don’t need to worry about:
- Optimal file sizes
- Whether a column can be used as a clustering key
- Order of clustering keys
How Does Liquid Clustering Work?
Liquid clustering extends beyond simple data aggregation; it prioritizes efficient data segmentation to enable more precise filtering at a granular level. This capability enhances not only storage management but also the performance of queries across large-scale datasets. By breaking down data intelligently, liquid clustering allows systems to retrieve the necessary information faster and more accurately, reducing the overall processing load and boosting efficiency in environments with complex data retrieval needs.
Liquid clustering optimally balances the precision of data clustering with the overall file size. For instance, a single file can encompass multiple dates for a single customer, several customers for a single date, or even a combination of multiple dates for several small customers. This method also intelligently subdivides larger partitions, such as breaking down a heavy partition by hours within a single day, ensuring efficient data management and retrieval.
Additionally, liquid clustering offers flexible and self-tuning architecture. It automatically adjusts the data layout based on clustering keys, dynamically reorganizing data according to evolving usage patterns. This adaptability helps prevent the common issues of over- or under-partitioning that often occur with traditional Hive-style partitioning. The result is a system that consistently optimizes both data ingestion and query performance without the need for constant manual intervention, making it a powerful tool for modern data management.
Setting Up Liquid Clustering with Databricks
Enabling liquid clustering in Delta Lake is straightforward. It involves specifying the clustering columns when creating a table. For example:

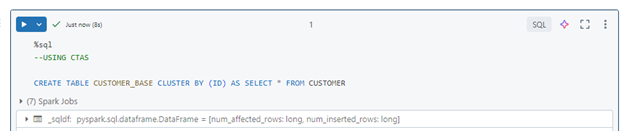
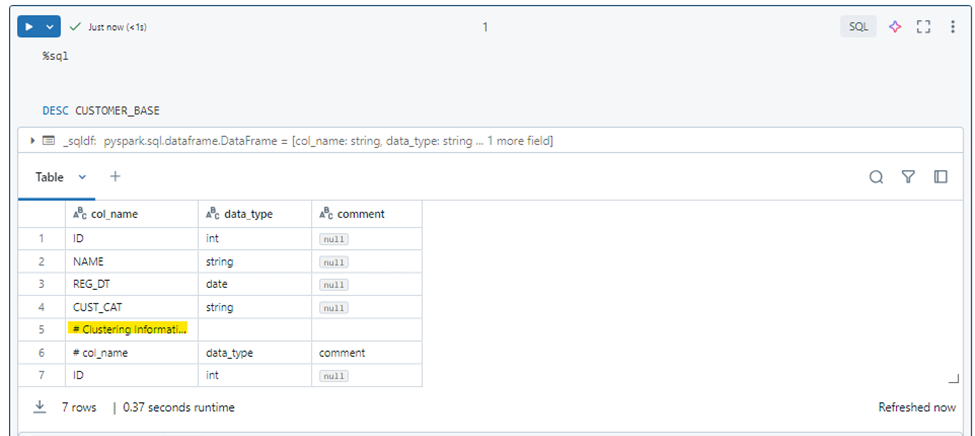
Once clustering is enabled, users can run the `OPTIMIZE` command to incrementally cluster new data as it is ingested. Always use OPTIMIZE FULL to ensure that data layout reflects the current clustering keys, it’s only supported for clustered tables with non-empty clustering columns.
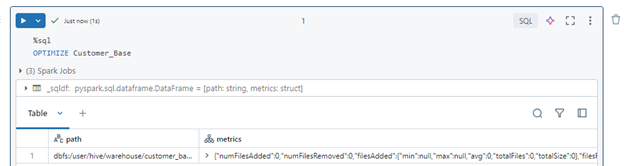
Unlike traditional methods, liquid clustering does not require rewriting all existing data when clustering keys are changed.

In Databricks Runtime 16.0 and above, you can create tables with liquid clustering enabled using Structured Streaming writes:
(spark.readStream.table(“source_table”)
.writeStream
.clusterBy(“column_name”)
.option(“checkpointLocation”, checkpointPath)
.toTable(“target_table”)
Benchmarking Liquid Clustering
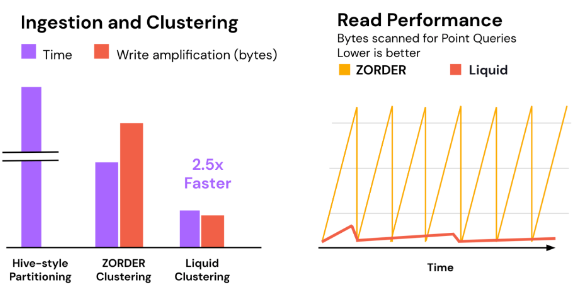
In a benchmark conducted by Databricks, liquid clustering outperformed traditional Hive-style partitioning and Z-Ordering techniques. When applied to a 1TB data warehouse workload, liquid clustering achieved 2.5x faster clustering compared to Z-Order and significantly faster performance compared to partitioning. This performance boost is due in part to Liquid’s ability to cluster data dynamically and incrementally, without the need for expensive shuffle operations that are common with partitioning (Delta Lake, Databricks).
Key Considerations and Best Practices
While liquid clustering offers many advantages, it is important to choose clustering columns wisely. For tables that were previously partitioned, users can start by using the same columns as clustering keys. For tables optimized with Z-Order, using the Z-Order columns as clustering keys is recommended. Additionally, the flexibility to redefine clustering keys means that organizations can adapt their data layouts to evolving analytics needs without significant rework.
Limitations
The following limitations exist:
- In Databricks Runtime 15.1 and below, clustering on write does not support source queries that include filters, joins, or aggregations.
- Structured Streaming workloads do not support clustering-on-write.
- In Databricks Runtime 15.4 LTS and below, you cannot create a table with liquid clustering enabled using a Structured Streaming write. You can use Structured Streaming to write data to an existing table with liquid clustering enabled.
Hexaware’s Use Cases
Case Study 1: Improving Query Performance in a Financial Services Company
A large financial services company struggled with slow query performance due to the rapidly changing nature of their data. The company relied heavily on partitioning by date, but over time, this led to uneven partition sizes and poor query performance. After implementing liquid clustering, the company saw a 2.5x improvement in query performance compared to their previous Z-Order approach. The incremental nature of liquid clustering allowed them to maintain consistently fast reads, even as new data was ingested .
Case Study 2: Accelerating Data Ingestion for a Media Streaming Platform
A media streaming platform dealing with terabytes of log data every day faced challenges with high write amplification and slow data ingestion due to the overhead of partitioning. Switching to liquid clustering not only improved their write speeds but also reduced the time needed to query large data sets. The company reported that liquid clustering allowed them to optimize their data storage without having to continually reconfigure their partitioning scheme.
Conclusion: Training on Liquid Clustering for Optimal Data Management
Liquid clustering represents a significant leap forward in data layout optimization, offering both simplicity and flexibility in managing large-scale Delta Lake tables. Its ability to dynamically adjust to changing workloads ensures that organizations can maintain optimal query performance without the constant need for manual tuning. With proven success in industries ranging from financial services to media streaming, liquid clustering is poised to become a standard practice for modern data lakehouses.
For those looking to enhance their data management strategies, Hexaware offers comprehensive solutions to help you leverage the power of liquid clustering and other advanced data technologies. Our expertise in Databricks and Delta Lake can guide your enterprise through the platform’s integration and adoption. To further enhance your data management, explore our Comprehensive Guide to Databricks Unity Catalog: Features, Setup, and Best Practices or get insights on Databricks Unity Catalog: Security, Row-Level Access, and Column-Level Security Control.
Reach out to us today to discover how Hexaware can assist you in transforming your data infrastructure for better performance and scalability. Our team is ready to support your journey towards efficient and secure data management solutions.


















