Introduction – The advent of Generative AI
As businesses continue to explore increased automation and intelligent solutions to end-user problems, generative AI has upped the ante by revolutionizing automation like never before. Powered by huge corpora of data, robust computational power, and innovative, optimized algorithms, AI has brought the world to the cusp of a metamorphosis. The way individuals and businesses process data, use technology, and consume information is set to see a fundamental transformation. The unveiling of ChatGPT toward the end of 2022 has unleashed a chain reaction of sorts. Multiple AI tools are already out or are on the anvil, promising even better performances. According to a Dutch-based data provider Dealroom, investment in generative AI companies has increased tenfold from 2020, totaling nearly $2.1 billion in 2022! This is testimony to the promise and potential that generative AI holds for the future.
Autonomous Testing: An Overview
Autonomous testing is a fast-emerging paradigm driven by Artificial Intelligence and Machine Learning algorithms that help businesses eliminate or reduce manual effort in the software testing lifecycle. Autonomous testing offers several benefits, such as improved testing efficiency, faster time-to-market, reduced testing costs, and increased test coverage. It also enables testing in complex and dynamic environments and reduces the risk of human error. As a natural consequence of adopting this paradigm, the development teams benefit from shorter internal delivery cycles and early feedback.
Hexaware has carefully studied the entire software quality assurance lifecycle and identified several use cases that need human intervention and man-days to be completed. Examples include developing and maintaining automation scripts, failure analysis, corrective actions recommendation, and consuming data from various sources to provide meaningful insights that help improve the software quality. These implementations will help customers navigate from test automation to autonomous testing, where software testing is the fastest cog in the DevOps chain.
ATOP (Autonomous Test Orchestration Platform) is a unified platform built by Hexaware to implement autonomous testing in pursuit of making software testing independent of human intervention. ATOP is an integrated one-stop solution for the end-to-end testing lifecycle. It comes with a plug-and-play architecture that can be seamlessly integrated with the client’s IT landscape. We have over 200 use cases covering the following areas –
- Script Generation: Generation of Gherkin feature files/test cases and corresponding automation scripts from user story acceptance criteria.
- Dynamic Test Suite Generation and Test Execution: Real-time identification of test cases to be executed in the DevOps pipeline for a given change.
- Failure Analysis: Analysis of group test failures and implementation of necessary corrective actions to reduce the test execution analysis efforts.
- Root Cause Analysis: Proactively identifying the production issues and generating corresponding automation data and test scripts.
- Performance Modeling: Creation of performance models from production logs based on the real-time usage of the application.
- User Experience: Identification of application features with poor customer feedback through sentiment analysis and strengthening the test coverage.
Traditional Approach for Implementing AI & ML Algorithms Required for Autonomous Testing
The traditional approach for implementing AI and ML algorithms for autonomous testing essentially involves the following stages:
- Data collection: Historical Data from various log files, automation test results, customer reviews, user stories, test failures, metrics, etc., are collected and collated. Data may also be simulated if needed based on the use case scenarios. Larger datasets may enable us to explore deep learning options.
- Data preprocessing: The raw data is cleaned, transformed, and formatted in a way suitable for training an AI/ML model. Examples include handling missing values, processing outliers, etc. Data integrity checks are also performed.
- Feature engineering: The impact of each feature in the data on the outcome to be predicted is visualized/analyzed and studied. New features may have to be engineered and existing features transformed for the model to predict better.
- Model selection: Depending on the problem being solved, classical Machine Learning algorithms like Random Forest, Decision Trees, Logistic Regression, Boosting Models, and NLP libraries like NLTK would be considered and tried for optimal performance.
- Model training: The hyperparameters of the different models are finetuned to give the best results. After this, the model is trained using a part of the data, and its performance is validated using an ‘unseen’ part to gauge its performance. This would involve using suitable metrics such as accuracy, precision, recall, F1 score, or ROC curve.
- Model deployment: Once the model has been validated, it can be integrated with existing testing frameworks or deployed as a standalone application.
The traditional approach for implementing AI/ML algorithms for autonomous testing involves a rigorous and iterative process. Based on the use case, it can require larger volumes of data and more expensive computational resources.
Based on the production setup and domain of business, the models may have to be finetuned or retrained with relevant data. Regular retraining of the models in production based on recent, real-time data keeps the models relevant in time.
How Generative AI Can Be a Game Changer to Expedite and Scale AI & ML Algorithms Required for Autonomous Testing
Using AI/ML models provided by generative AI tools like ChatGPT takes autonomous testing up a notch. Below are some of the critical value-adds they can provide:
- Generative AI Models are trained on a huge amount of data, which is otherwise not easy to access or process.
- The data is sourced from a comprehensive continuum of domains, applications, lines of business, geographies, etc.
- The algorithms are trained and refined with high computation-powered infrastructure, which is generally expensive to procure and maintain.
- The models have cumulative and collective knowledge from across the length and breadth of the public domain from several years/decades in the past.
- Constant feedback from the global community and model retraining help keep the consumers of the tool up to date.
- State-of-the-art technologies in Deep Learning would keep our customers relevant and effective regarding market share.
- For the quality of the responses generated, the processing time is lower when using generative AI tools.
Overall, these can make the output more reliable, accurate, exhaustive, and relevant to the context as it results from intelligent decision-making, smarter transactions, and optimized data processing. Hexaware envisions using this power of generative AI within the ATOP systems, thereby taking autonomous testing to a new level.
OpenAI’s ChatGPT, GPT-4, MidJourney, Jasper – AI, Google Bard, and DeepMind’s AlphaCode are a few popular generative AI platforms.
Examples of Autonomous Testing Use Cases: Conventional and Generative AI-Powered Approaches
Described below are a few autonomous use cases in ATOP. We discuss the conventional approaches taken to implement these, along with the value that Generative AI adds to the implementation when incorporated.
1. Root Cause Analysis of Failures:
Problem Statement: Given the failure logs from various test automation runs, we would want to classify the errors and exceptions into categories like application errors, automation exceptions, environmental downtimes, etc.
Conventional Approach: Preprocessed and labeled exceptions related to test automation failures are used to train classic Machine Learning models. The exceptions cover a list of root causes like:
- Automation issues
- Application error
- Data-related issues
- Environmental downtime
- Infrastructure-related issues
- Latency issues
Algorithms like Random Forest and Decision Trees Classifier are trained and finetuned to predict the root cause of the failure or exception.
Model retraining is done periodically with more recent data to keep the models temporally relevant and stable.
RCA Using Generative AI – Strategy and Advantages: The strategy is to use their official APIs to tap into the generative AI model tools. These models are trained on huge corpora of data, including failure logs and their corresponding labels.
We would post API requests with prompts containing the details of the test failure exceptions to the models. The response from the models having the failure classification is post-processed with the failure reasons identified by LLM and sent to downstream systems.
AI algorithms can swiftly process large corpora of test failure logs to classify them based on the root cause that triggered each failure. Given a context, generative AI can also suggest a corrective action based on the root cause of an automation test failure.
Generative AI significantly increases confidence in the output, as the models are trained on huge data sourced across businesses and domains. We would save on training and retraining costs as well.
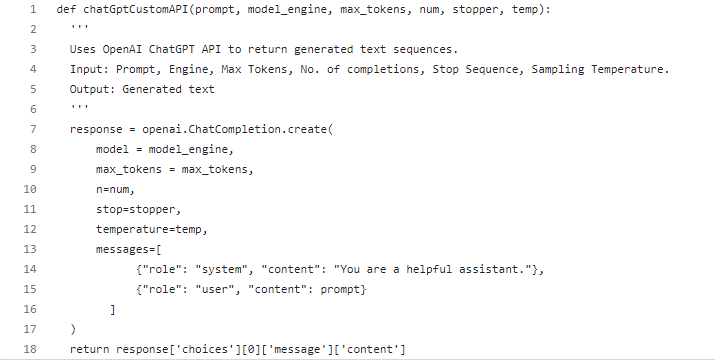
Following is a Python code snippet with the API request that we send to ChatGPT:
Here is a sample output where ChatGPT labeled exceptions:

2. Feature Files Generation:
Problem Statement: Given user requirements from the business, we would want to convert them to Gherkin feature files automatically, with good test coverage and parameterization.
Conventional Approach: Rule-based mapping and similarity computations generate statements based on the input user stories. Based on the best rule match, feature statements are selected and generated, given an input requirement statement. The mapping rules are hashed and are periodically updated based on new templates encountered.
Predefined feature file statements are also triggered based on similarity with the incoming user requirements. The initial data for creating the mapping of rules was sourced from user story requirements and corresponding feature files for known scenarios.
Feature File Generation Using Generative AI – Strategy and Advantages: Generative AI can handle user requirements in several forms and templates. It can intelligently recognize and process requirements through user stories, acceptance criteria, simple text, or even comprehensive documentation. These state-of-the-art models are not adversely sensitive to dynamic presentation styles, verbose, or templates. The requirements, usually in the form of user stories, need not be in a specific format or follow a certain syntax.
Generative AI can thus be used to transform end-user requirements into parameterized behavioral features. This comes with the added advantage of increased test coverage and validation of non-functional aspects relevant to a given requirement.
The other benefit we derive by using models like ChatGPT here is that we can leverage complex deep-learning models with a large number of parameters and cutting-edge algorithms using transformers at a very competitive price point. These are otherwise very expensive investments to train and retrain at stipulated intervals.
Below is a simple example where a requirement related to incident management is converted to a feature file:
Prompt sent to ChatGPT using OpenAI’s API:
“Generate Gherkin BDD scenarios for the following user story, including parameters and values as applicable:
As a customer service representative, I want to be able to create a new incident in ServiceNow when a customer reports an issue so that the incident can be tracked and resolved in a timely manner.”
Response received from ChatGPT:
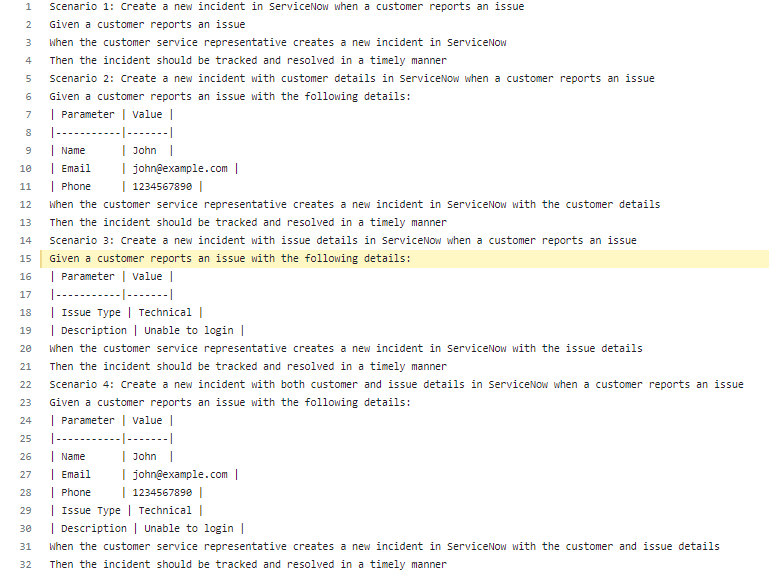
With this initial output, with additional context-based prompts, the output quality can be further fine-tuned and enhanced to meet enterprise demands.
3. Data Generation and Validation:
Problem Statement: This relates to ETL (Extract/Transform/Load) testing. Based on the information related to the source database, target database, and the transformation business rules, generate SQL queries that can be used to validate successful data transformation from source to target.
Conventional Approach:This process was a manual activity and a white space for potential automation. Based on business rules for transformation, SQL queries for ETL testing were arrived at.
Data Generation using Generative AI – Strategy and Advantages: Autonomous test data generation for a given feature is a popular application of AI capabilities. Apart from this, businesses can also leverage this to validate data transformation from the source to target systems based on business rules.
One such example is this use case. ChatGPT generates source and target SQL queries for ETL [Extract/Transform/Load] testing, as shown in the example below. The input prompts generally include the source and target table names, columns in question, and any transformation business rules applied before load.
This implementation would eliminate the manual effort needed to write the queries by using models that can generate code, as they were trained on a large number of code bases. It saves us time and effort that would have otherwise been incurred to access, process, and train with this grand scale of data.
Source SQL Query:
SELECT
Order_identifier,
Trade_identifier,
CASE WHEN Product_Code = ‘EQ’ THEN ‘EQUITY’ ELSE Product_Code END AS Product_Code,
Transaction_Type,
Trade_Date,
Settle_Date,
Transaction_Currency,
Settlement_Currency,
Broker_Id,
Broker_Email,
Clearing_Broker,
CASE WHEN Cusip = ‘000000000’ THEN ‘0’ ELSE Cusip END AS Cusip,
ISIN,
Security_Id,
Execution_Price,
Order_Quantity,
Commission_Amount
FROM Order_Details_Staging;
Target SQL Query:
Order_identifier,
Trade_identifier,
Product_Code,
Transaction_Type,
Trade_Date,
Settle_Date,
Transaction_Currency,
Settlement_Currency,
Broker_Id,
Broker_Email,
Clearing_Broker,
Cusip,
ISIN,
Security_Id,
Execution_Price,
Order_Quantity,
Commission_Amount
FROM Order_Details_Staging1;
Challenges and Conclusion
While Generative AI tools like ChatGPT do make significant value adds to business solutions, we see a few challenges that need to be worked with. Apart from the commonly known limitations like lack of context and open-ended responses, listed below are a few challenges particular to implementing APIs for autonomous testing use cases.
- Sensitivity to request prompts: By design, generative models are very sensitive to input prompts and context. Responses significantly differ in content, style, and tone, with even small changes in the prompts. Creative prompts generation based on feedback from responses helps stabilize the responses generated.
- API Request Parameters: Often, the APIs provided by companies to tap into their generative AI models come with several parameters that can be used to finetune the output. The responses generated are sensitive to these values. Careful consideration and tuning of the individual/combined parameters are required to create appropriate and relevant content.
- Token sizes: APIs have token size restrictions for API requests and responses. Effectively breaking down scenarios and fragmenting input requests would aid in the optimal usage of allowed token sizes.
- Randomness in responses: By its very design, deep learning generative models are stochastic and not deterministic. Depending on the prompts and hyperparameters set, the randomness in the output can be controlled. Consistent/identical outputs may not always be a possibility with these models.
- Post-validation and processing: Since the responses are random, teams need to add a layer that validates the responses from the model for content, relevance, and context. It is a challenge to arrive at these validations as there are no definite rules or checks here, given that the responses do not have to be identical every time.
Using creative and smart ways to address these challenges will enable teams and businesses to benefit from the capabilities of generative AI. Faster responses, training on huge corpora of data, high computational power, and cutting-edge deep learning algorithms are the key differentiators that these tools can offer.
We see an opportunity for autonomous testing tool providers to leverage these AI algorithms and cover the white spaces in the software testing lifecycle. Generative AI has great potential to not only accelerate autonomous testing implementation but also increase confidence in the output of the tools and platforms that use it.


















