Data ecosystems are constantly evolving to match the dynamism of modern markets. For this, a refreshed outlook on data collection, processing, and analysis is key to enhancing agility, making optimized data architecture a priority for businesses today.
Enter StreamSets: a leading data integration platform by Software AG that has helped us simplify data availability for multiple clients, unlocking holistic business potential from its data. In this blog, we’ll uncover the StreamSets platform, diving into its features, exploring its various use cases, and discussing strategies for maximizing its potential.
As businesses navigate the complexities of modern data landscapes, the demand for robust data engineering has never been higher. StreamSets addresses this demand comprehensively. Its powerful and innovative approach to managing data flows enables organizations to build, run, monitor, and maintain data pipelines at scale, empowering data engineering like never before.
This blog will showcase a practical application of StreamSets through a solution developed for a global insurance aggregator company. Faced with the challenge of standardizing and transforming data from numerous sources, our approach leveraged StreamSets to orchestrate an efficient and scalable data pipeline. This strategy involved the innovative integration of Jython code with StreamSets connectors—a combination that facilitates data ingestion and enables dynamic data transformation.
Additionally, we’ll explore our uniquely designed pipeline that epitomizes the concept of ‘write once, run anywhere.’ This pipeline consolidates the tasks of what traditionally would require 100 separate pipelines. By leveraging the dynamic capabilities of StreamSets, we delivered a solution that resonates with the ethos of modern data engineering—do more with less.
What is Data Engineering, and Where is it Needed?
In recent years, modern enterprises have prioritized the development of advanced cloud data warehouses to support robust data engineering processes. As a result, data engineering today involves the intricate task of converting raw data from various sources and formats into a usable and accessible form suitable for analysis and utilization. This multifaceted process requires the design of systems that efficiently manage data collection, storage, and processing tasks.
Data engineering solutions are at the heart of DataOps, responsible for constructing complex data pipelines essential for transforming raw data into actionable insights. However, as data sources become more diverse and data volumes increase, modern data warehouses face challenges such as managing disparate data formats, handling schema evolution, and coping with the scale of operations.
With the StreamSets DataOps platform, data engineering embraces a sophisticated approach that revolves around orchestrating data pipelines across various platforms, databases, and cloud environments. This approach facilitates seamless data movement and transformation, ensuring data quality and integrity are maintained throughout your analytics journeys.
Understanding StreamSets: A Powerful Data Integration Platform
StreamSets significantly influences the trajectory of data ecosystem modernization efforts. Designed to handle continuous data flows, StreamSets excels in environments where data is voluminous, fast-moving, and constantly evolving. It provides real-time analytics and immediate insights crucial for maintaining a competitive edge in business operations.
What are the Key features of StreamSets?
StreamSets’ user-friendly visual interface and pre-built connectors empower data engineers to swiftly create, monitor, and manage data pipelines without requiring extensive coding expertise. This democratization of data engineering fosters collaboration among teams, accelerates time-to-insight, and enables organizations to unlock the full potential of their data assets, thereby driving informed decision-making and fostering innovation.
Key features and capabilities include:
- Integration capabilities with any hyperscaler cloud platform, such as AWS, Microsoft Azure, and Google Cloud, as well as on-premises systems, to offer flexibility and avoid vendor lock-in.
- Advanced data integration capabilities powered by Apache Spark, utilizing Data Collector and Transformer engines. This facilitates the flexible construction of batch and streaming data pipelines, making it accessible to data professionals of all skill levels.
Its capability to integrate with diverse environments and dynamically meet the fluctuating demands of data makes it a comprehensive, cost-effective solution for modern data integration and analytics strategies.
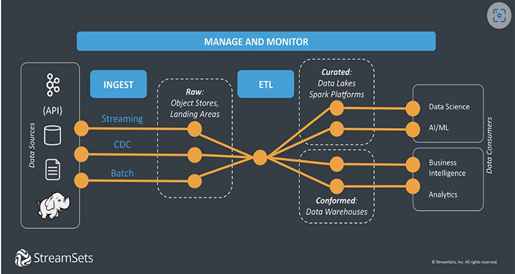
StreamSets Data Integration Framework
Components of StreamSets
StreamSets’ has several key components that work together to offer a comprehensive, flexible, and user-friendly platform for data ingestion, transformation, and delivery.
- StreamSets Data Pipelines: These ensure a smooth and efficient flow of data from source to destination, transforming it along the way for analytics, machine learning, and AI applications. These pipelines automate the data flow process, enabling seamless access to cloud data warehouses, data lakes, and on-premises storage applications for deep analysis.
- StreamSets Control Hub: A centralized platform for building, managing, and monitoring data pipelines, offering lifecycle management for data flows. It enables the deployment and execution of data flows at scale, providing real-time performance metrics and statistics.
- StreamSets Engines: These feature two main engines that power the data pipelines:
- Data Collector: Facilitates data collection from various sources, and performs record-based data transformations in streaming, Change Data Capture (CDC), or batch modes. It supports writing data to a wide variety of targets, ensuring flexibility in data handling.
- Data Transformer: Operating on Apache Spark, it executes data processing pipelines, enabling set-based transformations such as joins, aggregates, and sorts across the entire dataset. This functionality is crucial for executing complex data transformation operations on big data and streaming data.
- Data Collector Pipelines: These pipelines are designed for data ingestion from a range of sources and destinations, supporting reading and writing operations. They specialize in record-based data transformations across streaming, CDC (Change Data Capture), or batch modes.
- Transformer Pipelines: These Pipelines operate on Apache Spark deployed on a cluster. This setup allows Transformer Pipelines to execute set-based transformations such as joins, aggregates, and sorts on the entire dataset, enhancing processing efficiency and scalability.
Case Study One: StreamSets for Data Transformation in Insurance Analytics
Project Background and Problem Statement
A leading global insurance aggregator faced challenges in efficiently managing and analyzing data from various insurance carriers, all stored in a Data Lake on AWS S3 but presented in disparate formats. This diversity hindered the ability to standardize analysis and generate insights, thereby limiting the company’s potential for advanced analytics. The unstructured nature of the incoming data, which included headers in multiple formats and languages, necessitated a structured transformation approach to make the data analyzable.
This language diversity further complicated the standardization process, requiring specialized connectors and techniques to ensure interconnectivity with data and improve data handling.
Specific Use Case Scenario
The data received included files with column names featuring multiple headers, presenting a significant challenge for standard analysis.
Example:
Imagine a student file STUDENT_MARKS in this format.
Student name: Akash
Physics Maths Chemistry
89,90,78
Student name: Sreya
Physics Maths Chemistry
98,80,87
The objective will be to have at destination the data in the below format.
|
Student Name |
Physics Marks |
Chemistry Marks |
Maths Marks |
|
Akash |
89 |
90 |
78 |
|
Sreya |
90 |
80 |
87 |
Solution
Hexaware developed a solution to transform and standardize carrier data stored on AWS S3 enabling end users to make data-driven decisions. The solution includes data transformation and standardization processes, which help ensure that the data is consistent, accurate, and formatted in a way that makes it easy for end users to analyze and derive insights. Here’s a breakdown of our solution:
- We transferred vast amounts of raw insurance carrier data from AWS S3 to Snowflake on AWS using StreamSets.
- The cornerstone of our solution was the innovative integration of Jython code within StreamSets connectors. Jython, a Java implementation of Python, augmented StreamSets by enabling Python code for execution.
- Leveraging Jython’s flexibility, we precisely identified and extracted varied header information from the incoming data streams. This data was then organized into a structured, tabular format, suitable for detailed analysis.
- A dynamic data pipeline was designed to automatically standardize the heterogeneous data into a consistent format, ensuring uniformity and readiness for analysis.
Snapshot of the Code
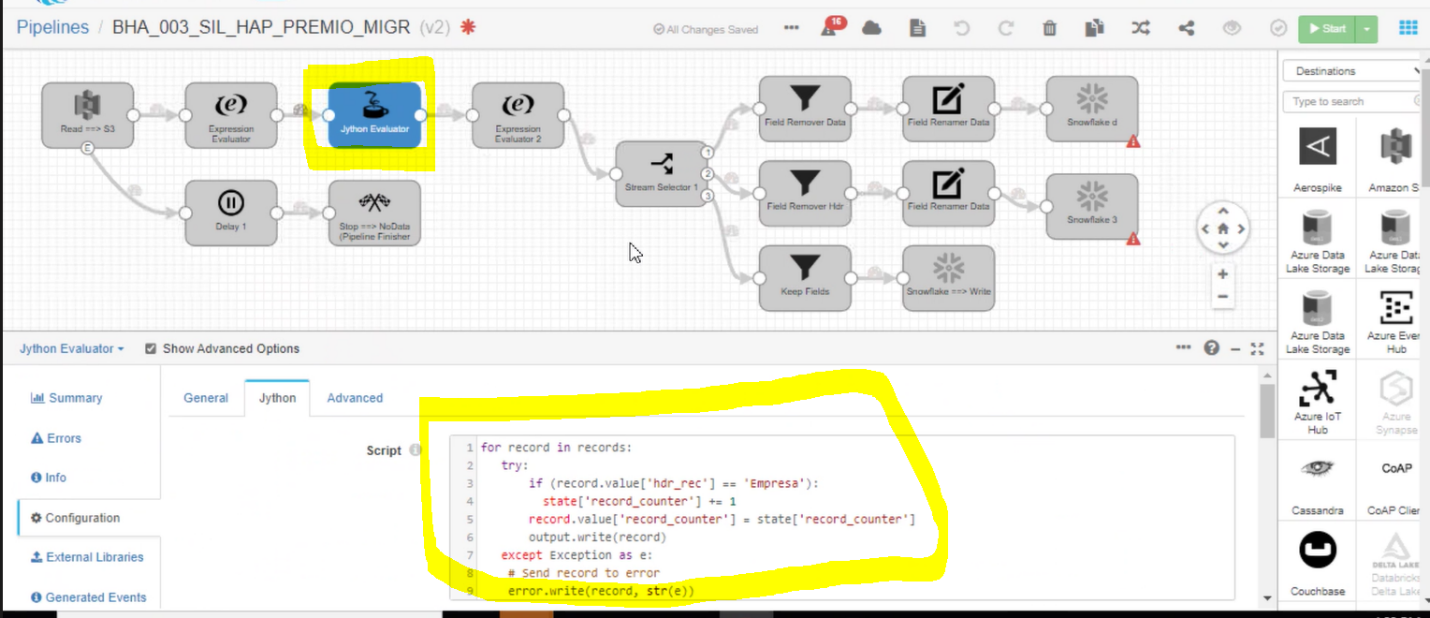
StreamSets Pipeline using Jython Connector
The image above provides a snapshot of a StreamSets pipeline utilizing the Jython Connector. This image not only showcases a snapshot of a StreamSets pipeline utilizing the Jython script but also provides the code that was implemented. By referencing this visual guide, you can easily identify the Jython Connector when navigating the StreamSets interface.
Benefits
The implementation of StreamSets, combined with customized Jython scripting, delivered several significant benefits for the client:
- Customized data processing was made possible with Jython scripts within StreamSets, allowing for adaptation to various data formats and structures.
- StreamSets facilitated customized data processing through Jython scripts, enabling adaptation to diverse data formats and structures.
- The dependency on carrier compliance, which could have caused indefinite delays, was eliminated with StreamSets.
- Automation of the data transformation process accelerated the implementation timeline by over 50%, reducing the need for manual intervention and saving time while minimizing errors.
- The automated data pipeline significantly reduced the time required for data preparation, allowing analysts to focus on deriving insights instead of cleansing data.
- The company’s agility in responding to market trends and customer needs has markedly improved due to the expedited and more reliable data analysis capabilities enabled by StreamSets.
Customizing the data transformation process to meet specific needs enables the global insurance aggregator to unlock the full value of their data, paving the way for enhanced business intelligence and strategic advantage. The case study exemplifies the transformative potential of integrating StreamSets with Jython scripting in overcoming complex data pipeline challenges, showcasing how innovative solutions can drive efficiency and innovation in data management and restructure processes for advanced analytics.
Case Study Two: One StreamSets Pipeline’s Hundredfold Impact
Project Background and Problem Statement
The project involved orchestrating a complex data migration initiative that focused on transferring data from various tables within a SQL Server database to a Snowflake environment. The main challenge was to efficiently identify and migrate solely the new or modified records based on portfolio IDs from numerous tables, all while avoiding the redundancy and complexity accumulated in multiple pipelines.
Solution
Leveraging StreamSets, we devised a generic pipeline with the agility to dynamically handle records with new portfolio IDs from SQL Server tables and transport them to Snowflake. This solution required the innovative application of a single, flexible pipeline instead of the typical one or two, allowing for the same workload to be distributed over multiple iterations with variable parameters.
StreamSets, as a data integration platform, played a pivotal role in streamlining the data processing workflow described. This dynamic adaptability meant that as new data entries with different portfolio IDs were introduced, the pipeline could flexibly adjust without requiring manual modifications or the creation of separate pipelines. A single, flexible pipeline instead of multiple rigid pipelines highlights StreamSets’ versatility in this use case.
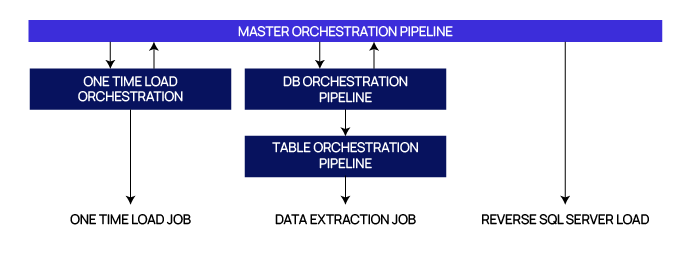
How to design your StreamSets jobs using orchestration pipelines
Process Flow
The orchestration process was designed to ensure efficiency and accuracy in data transformation:
|
Pipeline Name |
Parameter Passed |
Execution Order ID |
|
IFEXP_UC3_Orchestration_Master – Pipeline (streamsets.com) |
None |
E1 |
|
IFEXP_UC3_Orchestration_Config_OTL – Pipeline (streamsets.com) |
None |
E1.2.1 |
|
IFEXP_SQL Server _SNF _IF_POC_UC3_OTL – Pipeline (streamsets.com) |
DB_NAME DB_ACCT_ID |
E1.2.1.3 |
|
IFEXP_UC3_DB_Orchestration_Config – Pipeline (streamsets.com) |
None |
E1.2.2 |
|
IFRES_UC3_DB_Selection_Config – Pipeline (streamsets.com) |
DB_NAME DB_ACCT_ID CNT_ARIL |
E1.2.2.3 |
|
IFEXP_UC3_Table_Orchestration_Config – Pipeline (streamsets.com) |
DB_NAME DB_ACCT_ID |
E1.2.2.3.4 |
|
IFEXP_SQL Server _SNF _IF_POC_UC3_TLoop – Pipeline (streamsets.com) |
DB_NAME DB_ACCT_ID TABLE_NAME |
E1.2.2.3.4.5 |
|
IFEXP_SNF_SS_PRTFL_CHK – Pipeline (streamsets.com) |
None |
E1.2.3 |
Execution Order ID: E1
First, initiate sub-tasks for a one-time load and portfolio load orchestration. Next, create a reverse backup from Snowflake to SQL Server. This will culminate the procedure.
Execution Order ID: E1.2.1
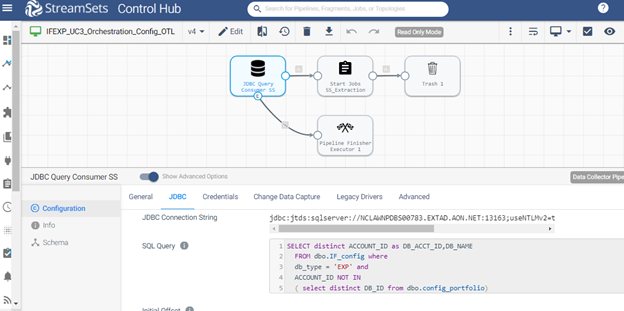
Identify databases that have not been processed before by passing their respective ID and name to the job.
Execution Order: E1.2.2
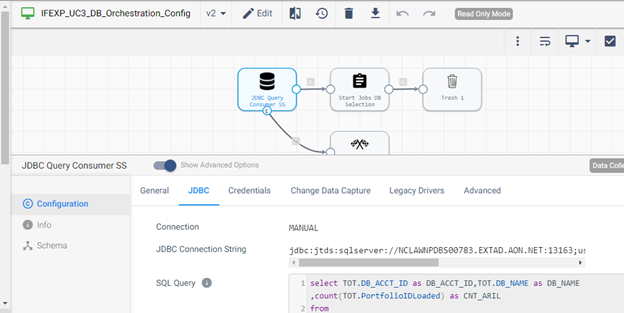
Use the job to receive the database ID, name, and the count of loaded portfolios. This information will help assess the availability of new portfolios for loading.
Execution Order: E1.2.2.3
Select relevant tables from the given database, excluding tables tagged for one-time load, for forwarding to the core extraction pipeline.
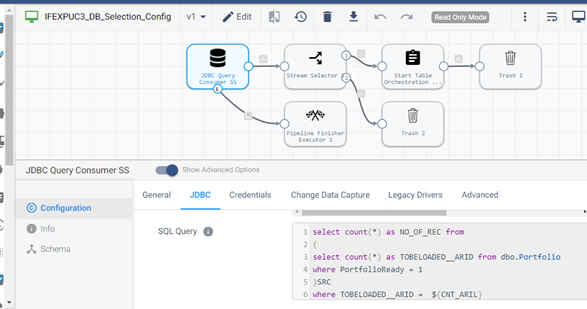
Execution Order: E1.2.1.3
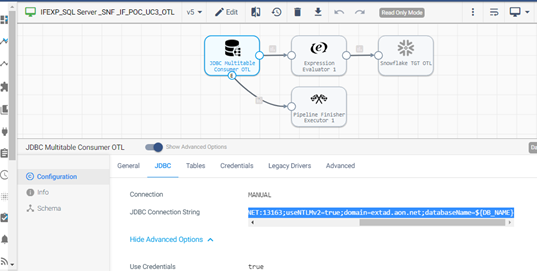
Leverage the Multi Table Consumer JDBC to extract data from all one-time load tables of a particular database.
Execution Order ID: E1.2.2.3.4
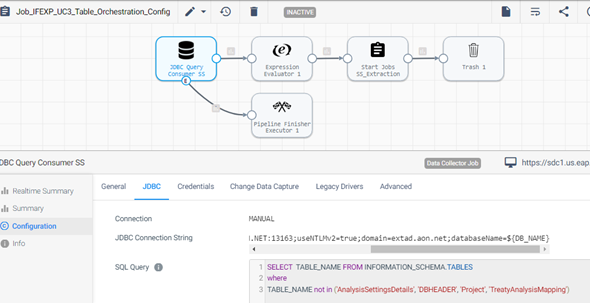
Use this process to select all relevant tables from the specified database, excluding one-time load tables, which are then passed to the core extraction pipeline.
Execution order ID: E1.2.2.3.4.5
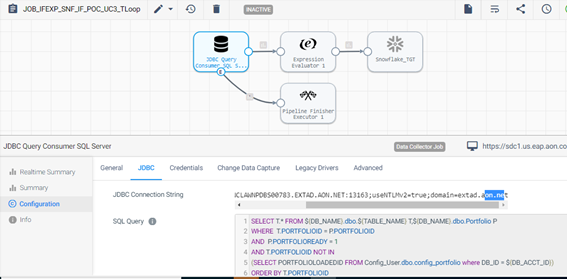
Extract records for portfolios that are marked for loading but have not been processed before.
Execution order ID: E1.2.3
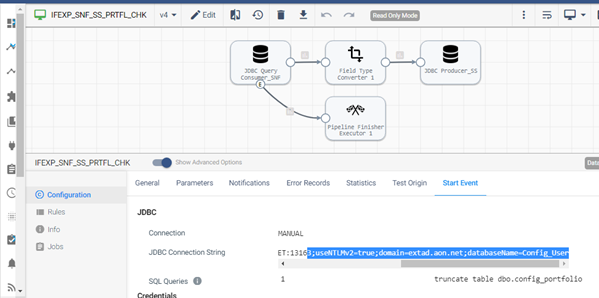
Truncate the existing portfolio configuration table in SQL Server and back up the latest version of the Snowflake Portfolio table to SQL Server.
Benefits
Our strategic use of StreamSets for orchestrating this complex data migration project yielded significant advantages:
- The ability to dynamically select and migrate only new or updated data records significantly enhanced the efficiency of the data migration process.
- Automating the migration process reduced manual intervention, minimizing errors and saving considerable time.
- The solution’s design allows for easy scalability, accommodating additional data sources or tables as the client’s data environment evolves.
- Ensuring only relevant, up-to-date data was migrated, the solution enhanced the client’s ability to perform accurate analytics and gain insights.
- Crafting a singular, multi-use pipeline that can substitute the work of 100 pipelines, we introduced a paradigm shift in data migration efficiency.
- The newfound adaptability, coupled with the ability to pass variable parameters for each run, marked a pivotal advancement in data processing capabilities.
Conclusion
As analytics advances to its next AI-driven frontier, the ability to efficiently integrate and manage data from diverse sources is paramount. Data engineering serves as the backbone of this endeavor, encompassing a range of processes and technologies aimed at designing, building, and maintaining robust data pipelines and infrastructure. At the core of this effort lies the utilization of cutting-edge tools and platforms such as StreamSets, empowering you to extract maximum value from their data assets.
Hexaware is at the forefront of offering state-of-the-art data engineering services that harness the full potential of StreamSets. By leveraging StreamSets, we empower our clients to ensure data integrity, facilitate real-time analytics, and enhance decision-making processes. Our expertise in implementing StreamSets-based solutions spans various industries and use cases, from simplifying data ingestion from numerous sources to orchestrating complex data pipelines for analytics and business intelligence.


















