It is the Digital Leapfrogging era, there is a strong need for speed in carrying out Analytics and generating Actionable Insights.
The data is growing, thanks to the technologies such as internet, mobile, social media, IoT, and web media such as blogs, syndication services, etc.. There is also a large pool of public datasets that can be used to enhance the insights and bring in better context to the businesses.
It is essential that we enable the end users to onboard these datasets without the need of IT teams.
Thus, holistically, there is a strong need of an Automated Data Ingestion Process and a Framework to automate the ingestion process.
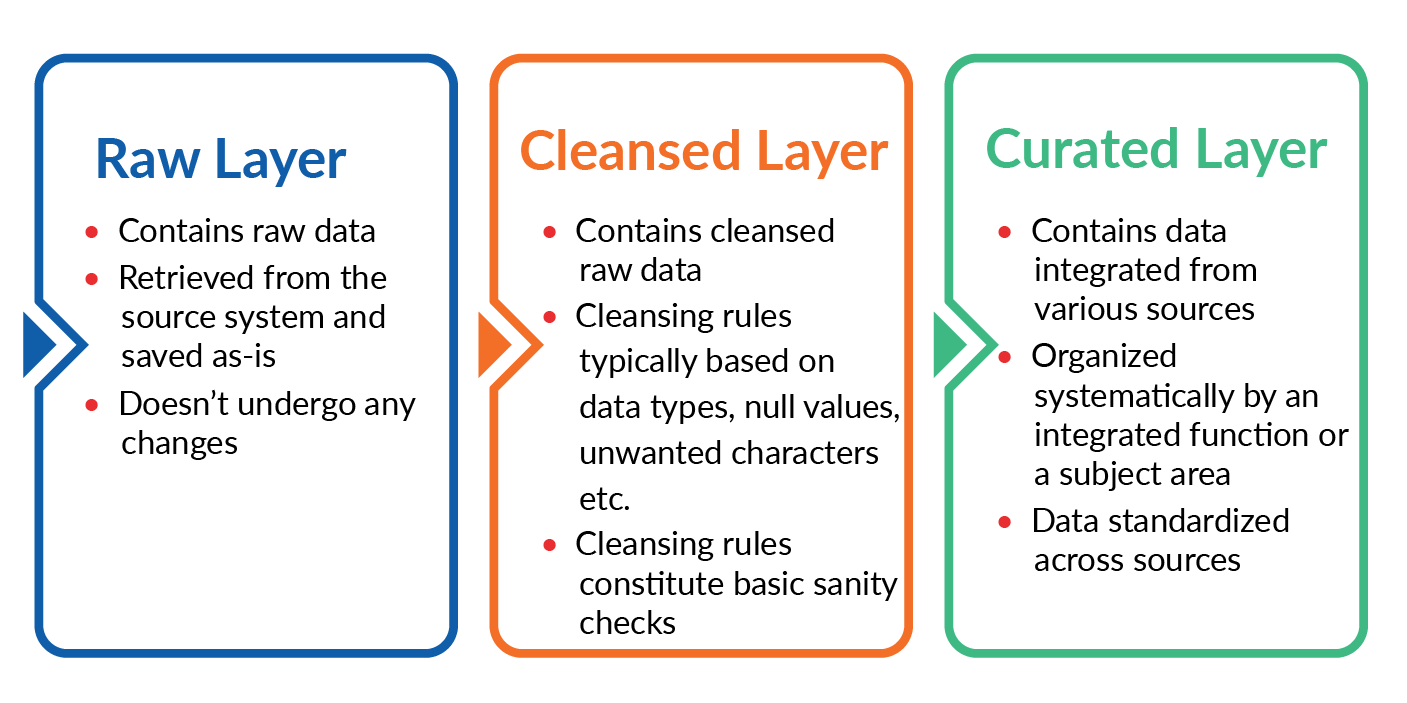
Typical Layers in Data Lake
Whenever we construct a data lake, we organize the data in multiple layers. The typical layers are Raw, Cleansed and Curated. There are also couple of more layers History and Archive where the complete historical data in active form and archived data in dormant form is maintained.
Raw layer, as the name indicates, contains raw data, retrieved from the source system and saved as-is. The data here doesn’t undergo any changes.
Cleansed layer contains the data that is produced by applying the cleansing rules on the raw data. The cleansing rules are typically based on the datatypes, null values, unwanted characters, etc. They also constitute basic sanitizing checks.
Curated layer contains the data integrated from various sources and organized systematically by an integrated function or a subject area. To achieve integration, the data undergoes various transformations in order to standardize across various sources.
Building the Raw layer
The data from various data sources such as RDBMS (custom business applications), File Systems (on-premise), APIs and data from other packaged enterprise Applications and cloud SaaS platforms are ingested into the raw layer on Cloud object store.
The process of ingesting data from the data sources to the raw layer faces challenges, including the ones listed below:
- Ability to add a new data source without IT help
- Avoid creating multiple code copies or jobs for loading data into the raw layer
- Ensuring higher performance irrespective of the form of data or the mode of feed like batch or stream
- Organizing data based on function with business tags
Metadata in the system plays a vital role in automating the data ingestion process. The Data Ingestion Framework (DIF), can be built using the metadata about the data, the data sources, the structure, the format, and the glossary.
DIF should support appropriate connectors to access data from various sources, and extracts and ingests the data in Cloud storage based on the metadata captured in the metadata repository for DIF. The whole ingestion process should be configurable, and the configurations are managed in a Metadata Database which the end user can manage without IT support.
We might lose the metadata due to dynamism in the execution process, this is addressed by an effective audit process combined with the configuration metadata.
Managing the data extraction & ingestion within the scheduled windows and reducing the load on source systems are the major challenges associated with data ingestion, that too when there are hundreds of tables. Essentially the ingestion process needs to be parallelized heavily. The parallelization can cut across tables and can be within a table too. This strategy helps in meeting the SLAs related to Data Loading and keeping the load on the Source Server under control.
We need to build the data ingestion strategy based on the data volume. We can categorize the tables as small, medium and large based on their size. We can group certain number of small or medium sized tables into one or more groups and execute the ingestion in parallel across tables in a group and across groups as well. We can group the large tables and apply parallelization within each table.
Data Storage is a critical aspect of a Cloud Data Lake. The entire data should be stored in Block storages in the cloud platforms such as S3 in AWS, Blob Storage in Azure and Cloud Storage in GCP in order to achieve better economies for data storage.
It is essential that the Data is well organized in the storage, aligning with the Enterprises’ structure such as LOBs, Divisions and Teams or Groups within each Division. In addition to this, the data should be stored in a specific folder-and-file structure so that we can leverage services such as Glue Catalog, Athena, in AWS and similar services in Azure (Polybase) and GCP (External Tables in BigQuery) to query the data. When storing large tables, it is essential that the data is stored based on a partitioning strategy and in high performant columnar formats such as Parquet or ORC so that query costs are under control.
Since there are too many activities performed for a variety of data sources, it is essential to build a consistent, repeatable Data Ingestion Process which is also quick in handling the ingestion.
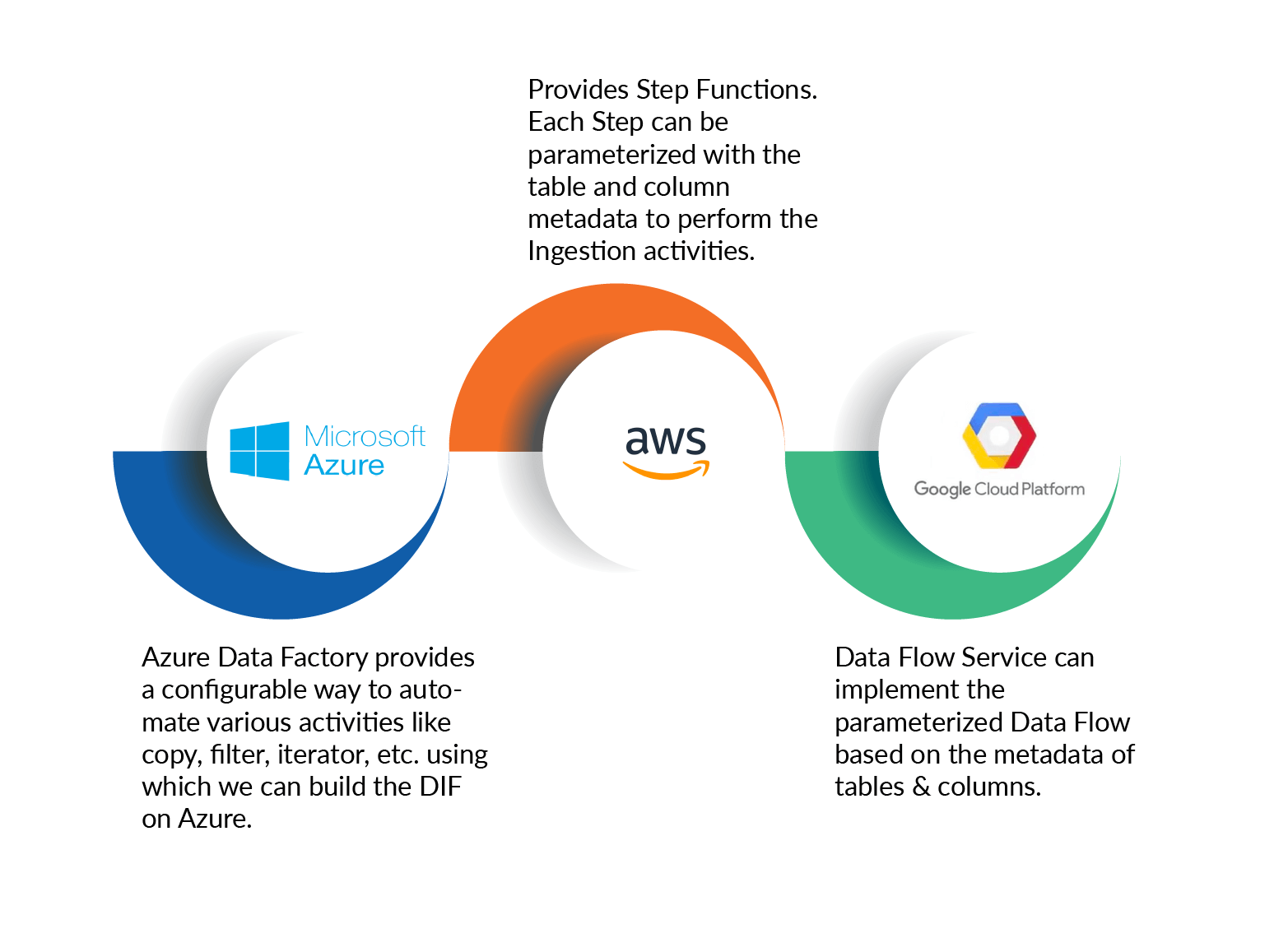
How Cloud Platforms like Azure, AWS and GCP support automated ingestion…
Cloud platforms such as Azure and GCP provide Data Ingestion and Processing services. For example, Azure provides Azure Data Factory (ADF) service that provides a configurable way to automate various activities like copy, filter, iterator, etc. using which we can build the DIF easily. ADF provides a Dynamic Content capability using which we can build the parameterized pipelines to ingest different tables by leveraging the table and columns’ metadata appropriately.
GCP provides the Data Flow Service, using which we can implement the parameterized Data Flow based on the metadata of tables and columns.
AWS provides Step Functions and each Step Function in the Step Functions Framework can be parameterized with the table and column metadata to perform the Ingestion activities.
These Services are natively offered by the respective Cloud Service Providers and help us build the Cloud Native Data Lakes, using the native services.
Extending the Data Ingestion to other layers…
While ingestion is the first step to load the data into raw layer of the Cloud data layer, there are further processes applied onto the data in subsequent layers. For example, data gets cleansed from raw layer and loaded into cleansed layer. Subsequently the data gets transformed and loaded into curated layer.
Now, looking at the kinds of checks that we carry out in Cleansing process, the same can be extended in the Data Ingestion Framework with common reusable components to support metadata driven and rules driven Data Cleansing process.
Not only cleansing, the standards-based Transformations can be applied on the data in the Curated layer as well. This would produce a standardized data in cloud.
Hexaware has built the Data Ingestion Process and the Data Ingestion Framework to automate the construction of the Cloud Data Lake
While automation smoothens the process of data ingestion, it does lead to significant effort and cost savings to the tune of 70-80%.
Kindly reach us at marketing@hexaware.com for a quick solution demo and for thoughts on how to enable DIF in a week.


















