Many large companies often struggle with managing big data in the cloud. Handling tasks like processing, analyzing, and generating real-time insights from data, all while ensuring shorter development timelines becomes quite a challenge without the right tools.
To effectively unlock the power of data for strategic decision making, integrating big data solutions with cloud platforms is crucial. Organizations can now tap into tools that better harness big data—making it easier to connect different data systems and handle complex environments.
One standout solution is Microsoft’s Azure Synapse Analytics, which unifies big data and data warehousing into a secure, single platform. Whether it’s diving into customer behavior data or spotting fraud as it happens, it helps organizations make sense of massive datasets and gain valuable insights faster.
Let’s see how.
Enhancing Code Compatibility and Reusability
In Azure Synapse Analytics, code reusability plays a significant role while creating data pipelines, scripts, or custom data processing functions.
To create reusable and compatible code, it needs to communicate with other modules. This interaction relies heavily on parameters and variables. Even when testing functionality, this code has to run with different datasets. In cloud platforms where multiple coding languages help boost versatility and compatibility, parameters and variables are crucial.
In this blog, we will explore passing values between Azure Synapse Notebooks or in a Data Factory pipeline to facilitate code reusability and compatibility.
Streamlining Data Exchange with Azure Synapse Notebook
A notebook refers to a computational document or an interactive environment where users can combine code, documentation, and capture the output of code execution. Azure Synapse Analytics provides a notebook service that allows them to create, edit, and execute notebooks within the Synapse Studio environment.
With a Synapse notebook, we can:
Begin data exchange with zero setup effort
Keep data secure with built-in enterprise security features
Analyze data across raw formats (CSV, txt, JSON, etc.), processed file formats (parquet, Delta Lake, ORC, etc.), and SQL tabular data files in Spark and SQL
Increase productivity with enhanced authoring capabilities and built-in data visualization
Enabling Data Engineering, Data Warehousing, and Big Data Analytics
When we work in Azure Synapse, we make use of pipelines within the Synapse Analytics workspace, a part of the studio environment. This acts like a unified interface for data engineering, data warehousing, and big data analytics in Azure.
In Azure Synapse, creating multiple notebooks helps organize pipeline tasks and promotes code reuse. To make our code more reusable and organized, we create multiple notebooks for different pipeline activities. This means it’s important for these notebooks to communicate effectively. While using persistent storage is one way, we find using variables and parameters much better for performance and computational efficiency in passing values between notebooks.
Moreover, the notebooks support several programming languages such as SQL, Python, .NET, Java, Scala, and R, making it suitable for different analysis workloads and engineering profiles. The notebooks also seamlessly integrate with Azure Databricks enabling users to continue utilizing Apache Spark for Big Data processing while benefiting from a specialized data architecture for extract, transform, and load (ETL) workloads.
Understanding How Azure Synapse Notebooks Work
When building a data pipeline, we often have to call one notebook from another notebook. For instance, when refining the raw data, we might need to check the null value in the amounts column and replace the null values with 0.00. Or we might want to validate if the productid column follows a specific format, such as AAA-124789-XYZ.
We can tackle these checks in separate notebooks, called from the master notebook. This means passing necessary values between notebooks—like predefined structures or replacement values for nulls. Here, Synapse’s variable feature becomes really useful.
These notebooks support different programming languages to incorporate our logic for processing data. To ensure that the code is reusable and modular, and to make maintenance easier, we should split the logic for processing data across notebooks.
We have different methods, such as using variables, to transfer data between notebooks. But first, let’s delve into the key components involved in this solution.
Pipeline Parameters: Pipeline parameters are used to control the behavior of a pipeline and its activities, such as providing details on where to find a dataset or specifying the path of a file that needs processing. Parameters are defined at the pipeline level and cannot be modified during a pipeline run.
After defining a pipeline parameter, we can access its value during a pipeline run by using the @pipeline().parameters.<parameter name> expression in a pipeline activity.
Pipeline Variables: Pipeline variables are values that can be set and modified during a pipeline run. They can be used to store and manipulate data during a pipeline run. For instance, they can hold computed results or keep track of where a process stands at any given moment. After defining a pipeline variable, we can access its value during a pipeline run by using the @variables(‘<variable name>’) expression in a pipeline activity.
Use Case for Azure Synapse Notebook
Microsoft Spark Utilities
Microsoft Spark Utilities (MSSparkUtils) is a built-in package within Azure Synapse Analytics designed to simplify various everyday tasks. For example, it streamlines file system operations, accesses environment variables, connects notebooks, manages secrets, and more, making the workflow smoother.
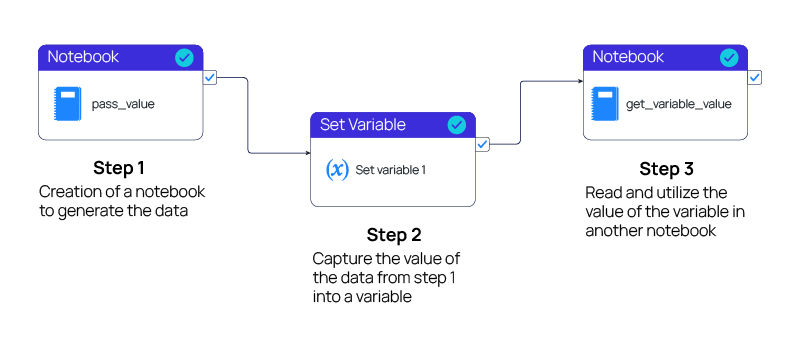
When we refer to the diagram below and break down the step-by-step tool approach, we uncover precisely how data moves seamlessly between two different notebooks.
Figure 1: Data Exchange Between Two Different Notebooks
Uncovering the Details
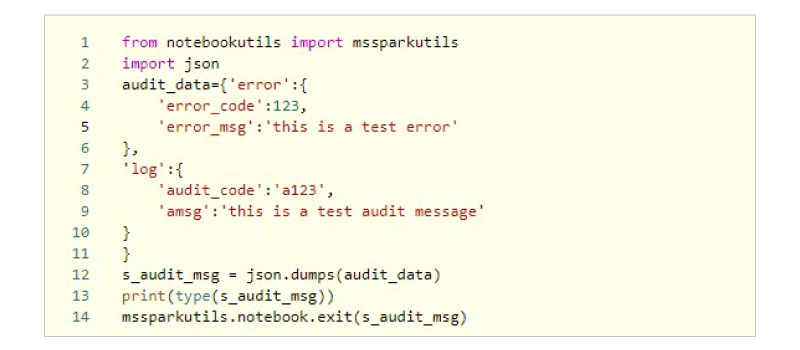
Step 1 If we have some logic for processing data in the first notebook and need to use the following part of that logic in the second notebook, we will need to pass specific parameter values to the second notebook. This involves creating a JavaScript Object Notation (JSON) structure from the data that needs to be transferred and converting it into a string. Then, by leveraging Microsoft Spark Utilities, we can return the value to the pipeline, as shown below:
Step 2
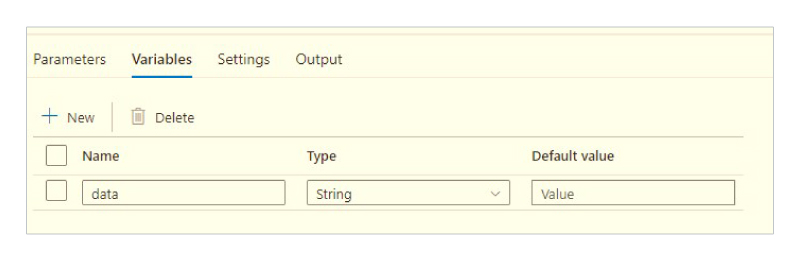
We create a pipeline variable as shown below. There is no need to enter any value for the variable.
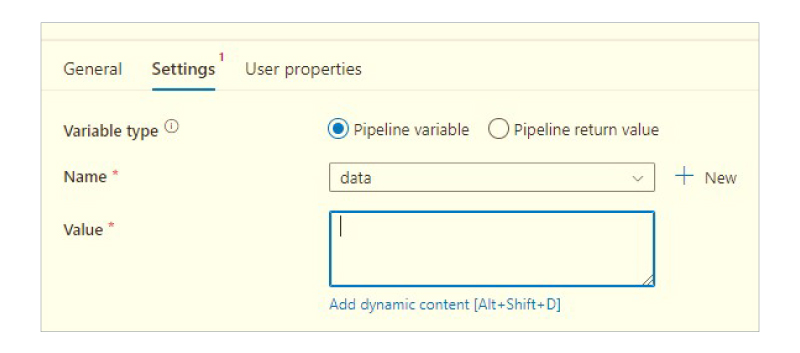
After adding a Set Variables activity in the pipeline, link it to the previous notebook.
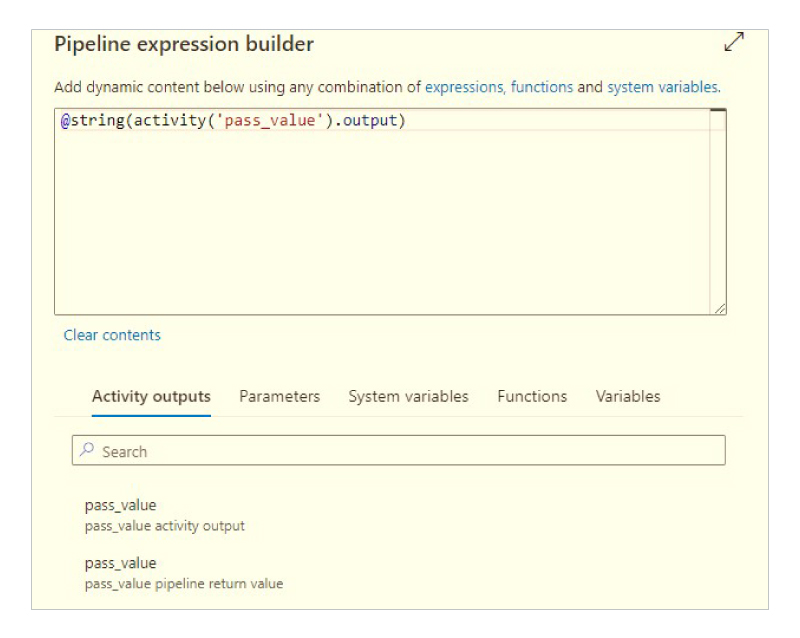
2. In the Set Variables activity, we need to select the Settings tab, Name the variable, and add dynamic content.
3. Select the Functions tab and select string under the Conversion Functions header. Then select pass value (activity output) in Activity Outputs tab.
Step 3
Create a base parameter for the notebook as follows: set the parameter’s value to the name of the variable created in step 2. Then, open the notebook and create a parameter cell to initialize a variable with the same name as the parameter.
Result
The value of the variable from the first notebook is now accessible from the second notebook.
Please note the example above was created on PySpark, a powerful open-source big data processing framework. In notebooks, we can write Spark code to process and analyze large datasets.
Empowering Data Processing with Advanced Capabilities
Better Efficiency: Using reusable code saves time and effort by doing the same tasks automatically across different projects or datasets
No External Dependency: Handles large amounts of data without relying on outside services like SQL or Blob, which makes it lighter and more flexible
Seamless Communication: Helps different notebooks talk to each other easily without needing extra computing power or traditional SQL read/write operations
Adaptable Support: Offers robust support for dynamic components within the data flow/pipeline, which results in significant cost savings during data processing
Cost Optimization: Utilizes variables to optimize costs, avoiding the need for expensive SQL instances and reducing input/output costs by eliminating variable extraction from tables
Streamlining Azure Synapse Workflows for Efficient Analysis
With a focus on code reusability and compatibility, we streamline workflows in Azure Synapse Analytics by passing parameters between notebooks developed in different languages. This approach greatly improves how we create, maintain, and scale analytics workflows, helping us get more done and manage projects better.
What we also achieve are fewer errors, lesser repetition, and enhanced overall efficiency of data processing within Synapse Analytics. The reusable code components often bundle up industry best practices and can be customized. This translates into time and effort savings across projects by cutting out repetitive tasks.
We are an experienced Microsoft partner with a deep understanding of Azure capabilities. For details on our partnership with Microsoft, email us at marketing@hexaware.com.
About the Author
Joy Maitra
Principal Consultant - Data & AI Practice
Joy Mitra is a lead architect for Hexaware’s Amaze® platform, passionate about designing innovative solutions for real-world business challenges. He excels at engaging with clients to deeply understand their pain points and crafting optimized, scalable solutions that blend human expertise with intelligent automation.
He firmly believes in AI for humans, not instead of humans. This philosophy drives him to build secure, compliant, and human-centric AI ecosystems that empower people rather than replace them. His work consistently reflects this balance—leveraging technology to enhance human capability while ensuring trust, transparency, and responsible implementation.